Explainability & Robustness
Explainability and robustness are often grouped together, but they answer different questions. Explainability asks why a model behaves the way it does. Robustness asks whether that behavior remains stable under perturbations, distribution shift, or runtime noise. This page centers XAI while keeping robustness as a tightly related trustworthiness topic.
1. What interpretability is
Interpretability is not one technique. It is a family of questions:
- can humans understand the evidence behind a prediction?
- can we localize which inputs, concepts, or circuits matter?
- is the explanation stable and causally meaningful?

Source: Tufts EE141 Trusted AI, Lecture 8, Slide 3. Image note: the slide places interpretability, explainable ML, and the black-box problem on one page. Why it matters: interpretability is not a decorative visualization step; it is about making model behavior inspectable and challengeable by humans.
1.1 Transparent vs black-box models
| Type | Examples | Interpretability profile |
|---|---|---|
| Transparent | linear models, decision trees, rules | directly readable but limited in expressiveness |
| Semi-transparent | GAMs, sparse models, concept bottlenecks | trade off readability and performance |
| Black-box | deep nets, Transformers, LLMs | need post-hoc or mechanistic tools |

Source: Tufts EE141 Trusted AI, Lecture 8, Slide 8. Image note: the slide directly contrasts transparent and non-transparent models. Why it matters: once the model itself is no longer readable, interpretability has to shift from “reading rules” to constructing evidence, concepts, and mechanisms.
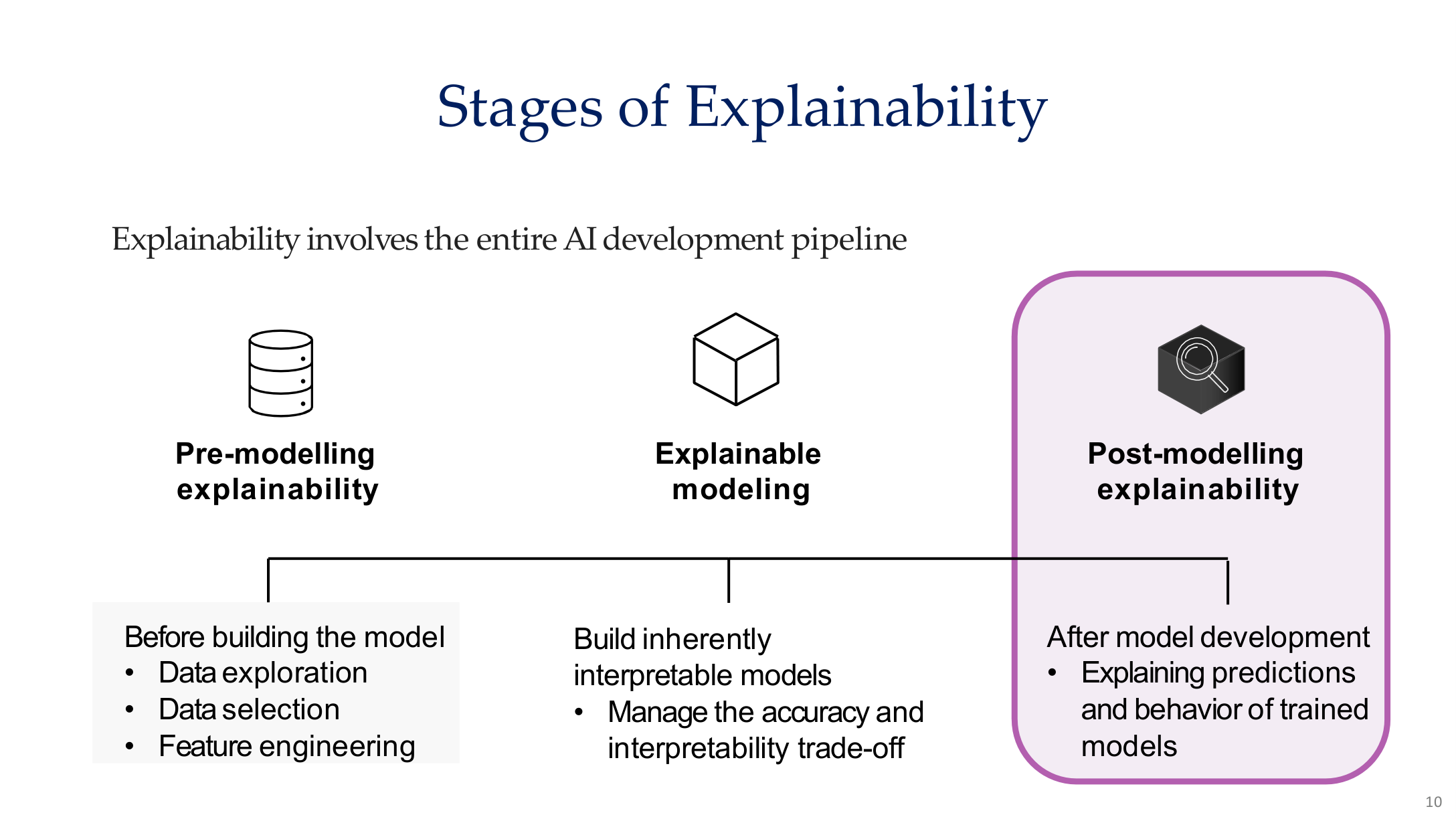
Source: Tufts EE141 Trusted AI, Lecture 8, Slide 10. Image note: explainability is divided into pre-modeling, modeling, and post-modeling stages. Why it matters: explainability is not a post-training add-on but a design principle spanning the entire AI development pipeline.
2. Main families of interpretability methods
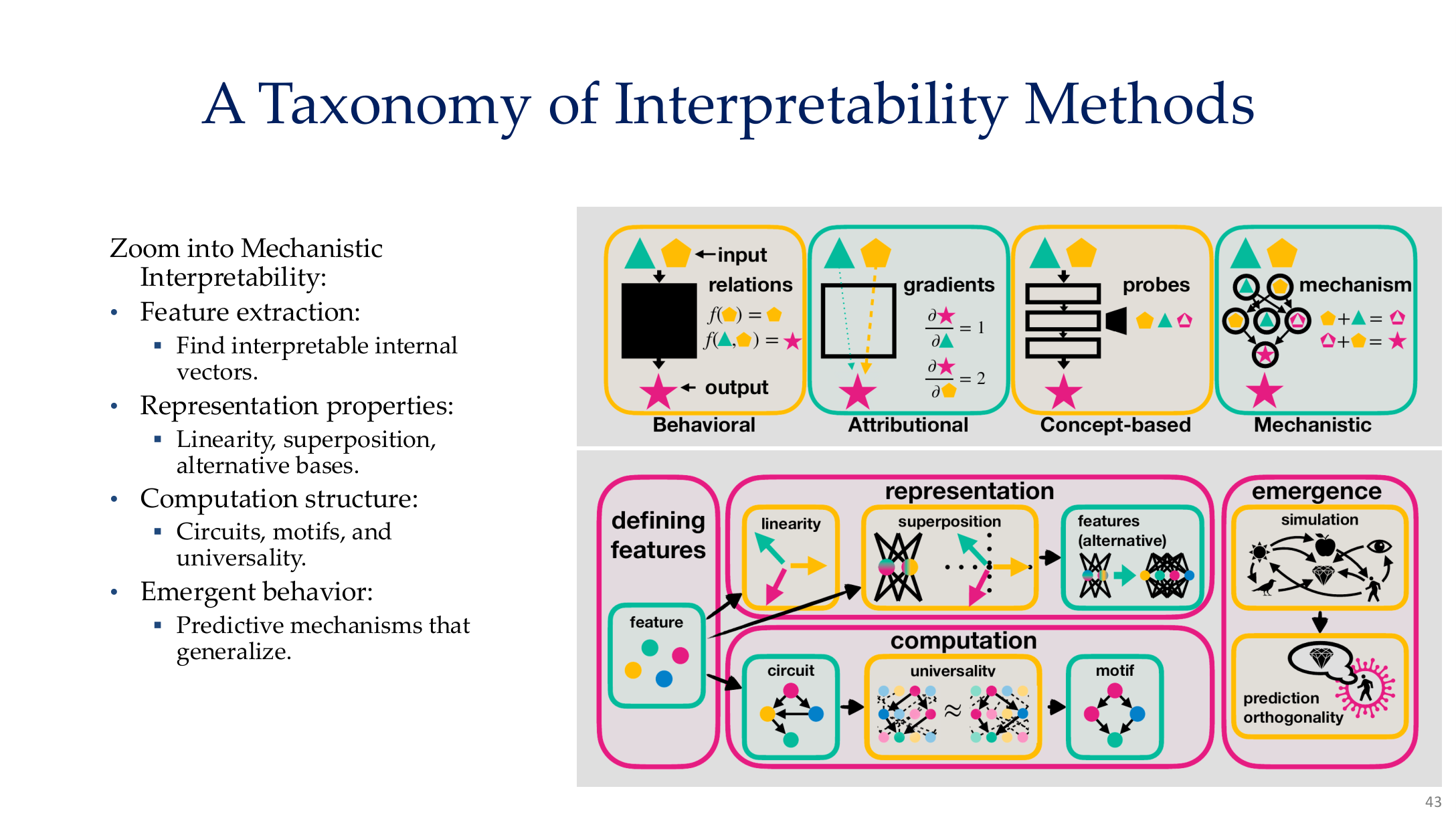
Source: Tufts EE141 Trusted AI, Lecture 8, Slide 43. Image note: the figure organizes interpretability into behavioral, attributional, concept-based, and mechanistic families, then further expands representation, computation, and emergence. Why it matters: XAI should not be reduced to heatmaps alone.
2.1 Behavioral explanations
Behavioral methods treat the model as an input-output system and ask how outputs change when inputs change. Typical tools include:
- counterfactual explanations
- feature ablation
- sensitivity analysis
- behavioral tests and probing prompts
2.2 Attributional explanations
Attributional methods ask which input dimensions matter most for a given output. Common examples are:
- saliency maps
- integrated gradients
- SHAP
- Grad-CAM
They often estimate local importance with expressions like:
2.3 Concept-based explanations
Concept-based methods move beyond pixels or tokens and ask whether the model relies on human-named concepts such as color, texture, faces, medical devices, or other semantic features.
2.4 Mechanistic interpretability
Mechanistic interpretability asks how internal features, circuits, and representations implement computation. The course highlights:
- feature extraction
- representation properties such as linearity and superposition
- computation structure such as circuits and motifs
- emergence and compositional behavior
3. Grad-CAM and counterfactual explanations

Source: Tufts EE141 Trusted AI, Lecture 8, Slide 20. Image note: the slide places the original image next to a Grad-CAM heatmap and a counterfactual region-suppression example. Why it matters: it separates evidence for the current class from evidence that would flip the class.
3.1 Grad-CAM

Source: Tufts EE141 Trusted AI, Lecture 8, Slide 18. Image note: the page compares the original image, guided backpropagation, and Grad-CAM outputs. Why it matters: different explanation methods do not just “look different”; they aggregate evidence at different levels.
Grad-CAM computes channel weights from class gradients:
It is useful for checking whether a model is focusing on the right region, or whether it is relying on background or shortcut features instead.
3.2 Counterfactual explanations
Counterfactual explanations ask not only “why class A?” but also “what minimal change would make it not class A?” They are closer to human causal reasoning and often make shortcut dependence easier to see.
4. LIME, SHAP, and local surrogate methods

Source: Tufts EE141 Trusted AI, Lecture 8, Slide 23. Image note: the slide explains LIME as fitting a locally faithful interpretable model around one prediction. Why it matters: LIME is useful precisely because it explains a local neighborhood rather than claiming to expose the full global mechanism.
LIME explains a sample by fitting a simple local surrogate:
Its strengths are model-agnostic local explanations; its limitations are instability and sensitivity to neighborhood sampling.
SHAP provides stronger game-theoretic semantics through Shapley values, but often at higher computational cost.
5. Mechanistic interpretability for LLMs
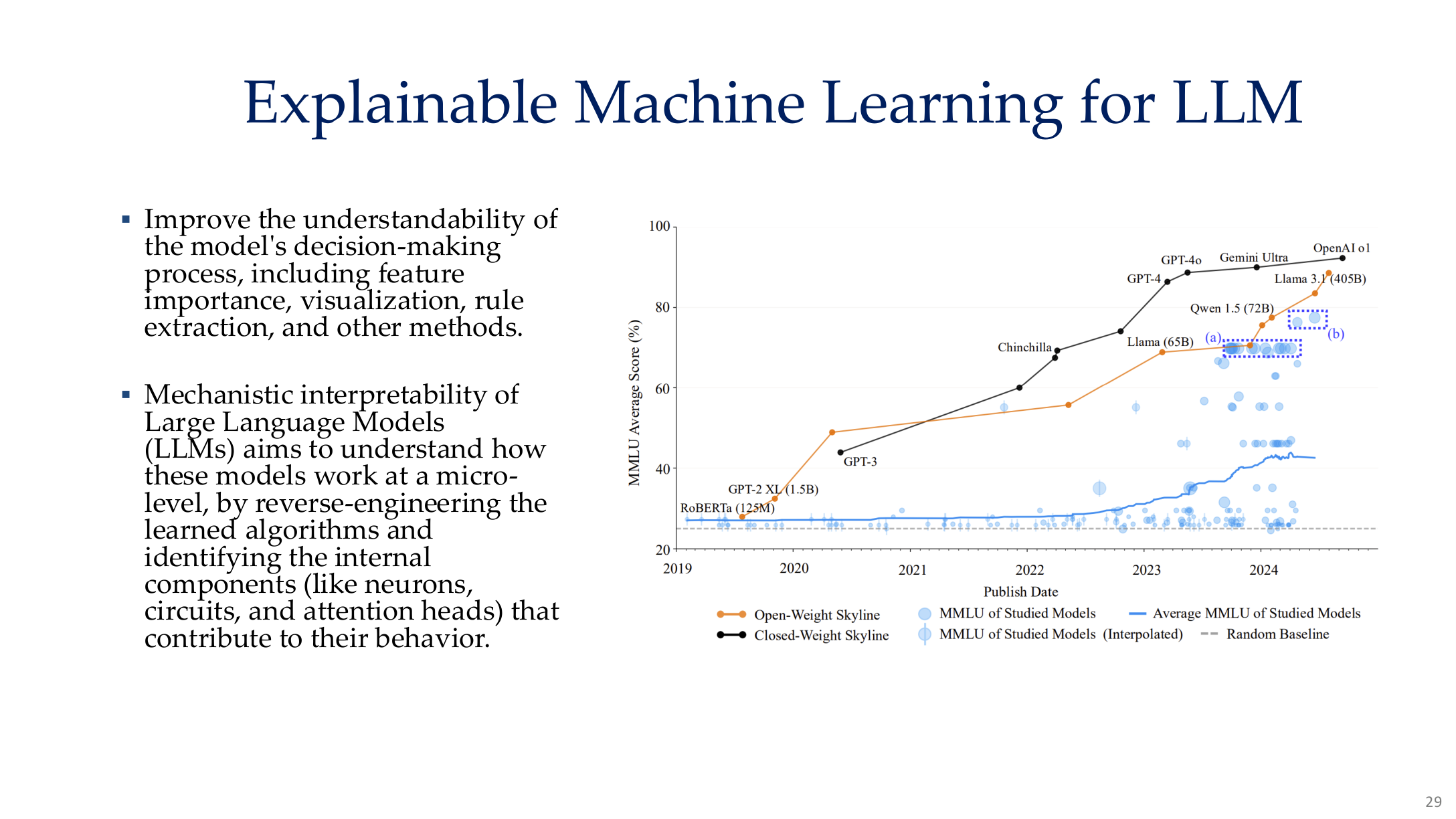
Source: Tufts EE141 Trusted AI, Lecture 8, Slide 29. Image note: the figure places larger scale, deeper stacks, and more complex behavior on one chart. Why it matters: for LLMs the question changes from “which pixel mattered” to “which submechanisms support capability and failure.”
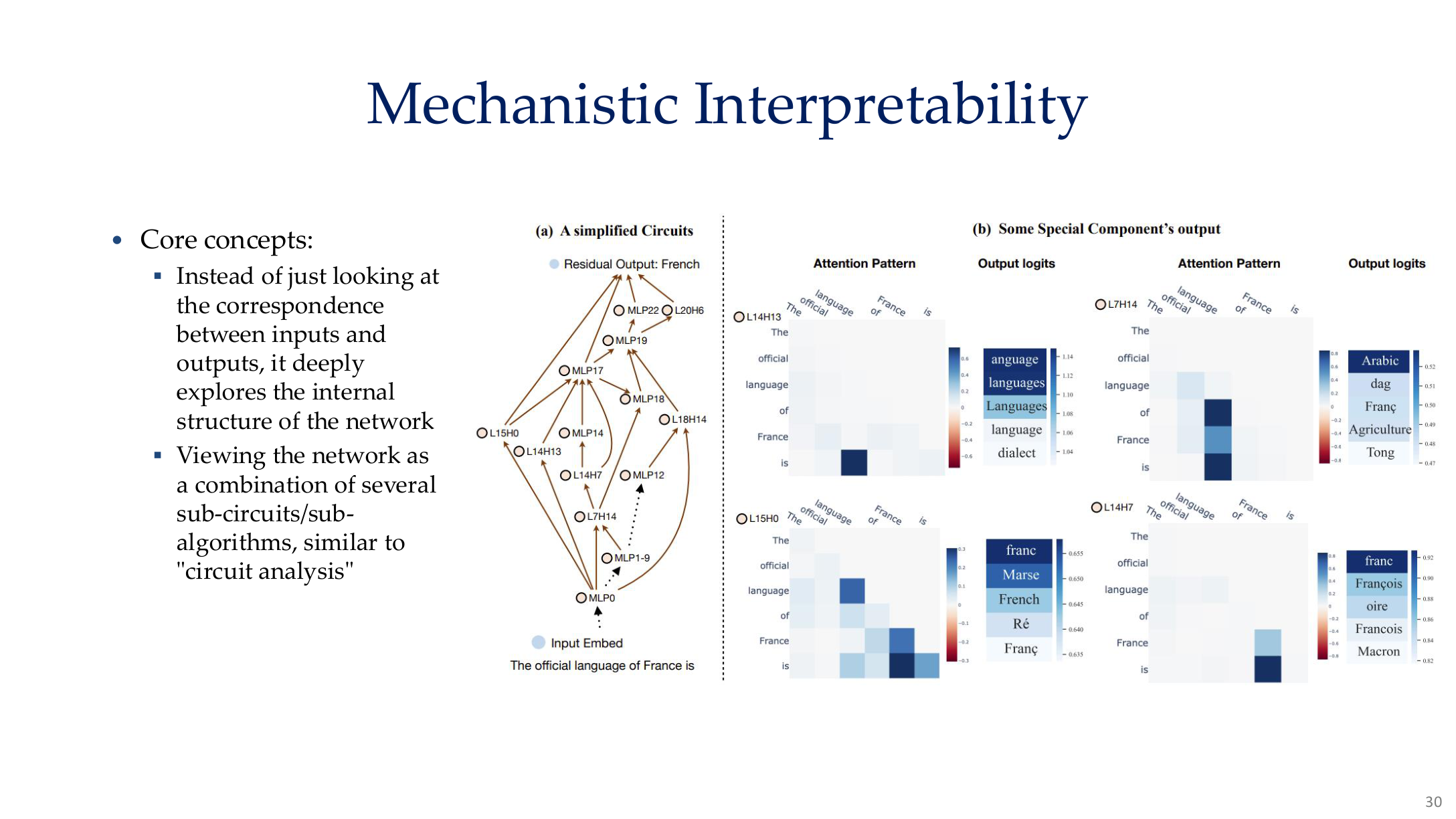
Source: Tufts EE141 Trusted AI, Lecture 8, Slide 30. Image note: the slide places features, attention paths, and internal subcomponents into a single view. Why it matters: mechanistic interpretability is about how computation is implemented, not just about attaching labels to outputs.

Source: Tufts EE141 Trusted AI, Lecture 8, Slide 32. Image note: the Transformer residual stream architecture shows how each layer reads and writes independently, with attention heads combining additively. Why it matters: the core assumption of mechanistic interpretability is that the Transformer residual stream is linearly superposable.
For large models, the most important mechanistic questions often are:
- which heads or layers encode certain concepts?
- which circuits support refusal, tool use, or factual recall?
- can activation interventions alter behavior in predictable ways?
- are there sparse features that align with safety-relevant concepts?
Common tools include:
- linear probes
- activation patching
- causal tracing
- sparse autoencoder feature discovery

Source: Tufts EE141 Trusted AI, Lecture 8, Slide 33. Image note: the slide suggests intermediate conceptual states rather than one-step answer generation. Why it matters: if we want to inspect deceptive behavior, hidden planning, or unsafe reasoning, we need to study intermediate representations rather than only final outputs.
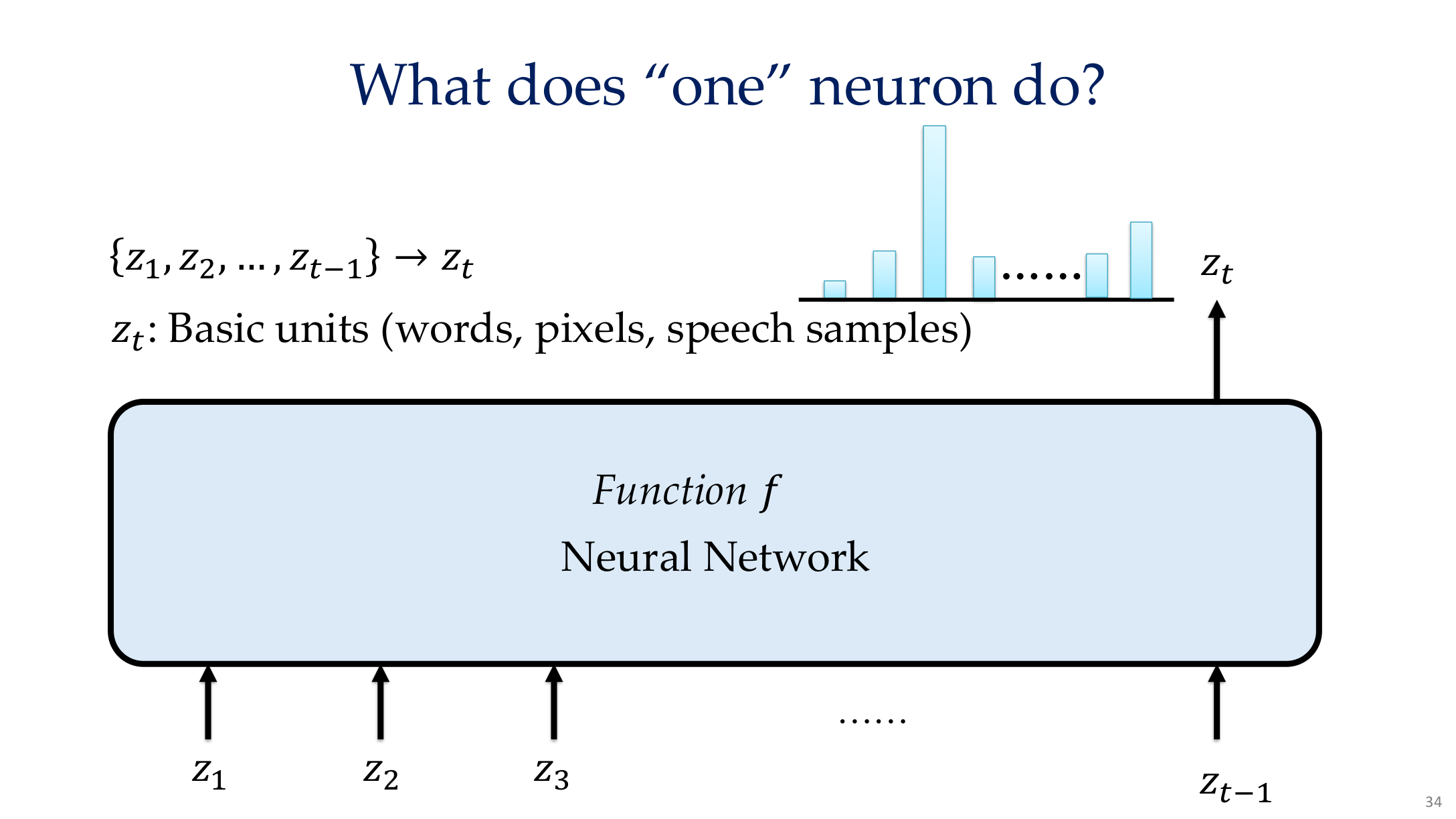
Source: Tufts EE141 Trusted AI, Lecture 8, Slide 34. Image note: the page shows one neuron responding across multiple examples. Why it matters: single neurons should not be naively equated with stable human concepts because many representations are distributed rather than local.
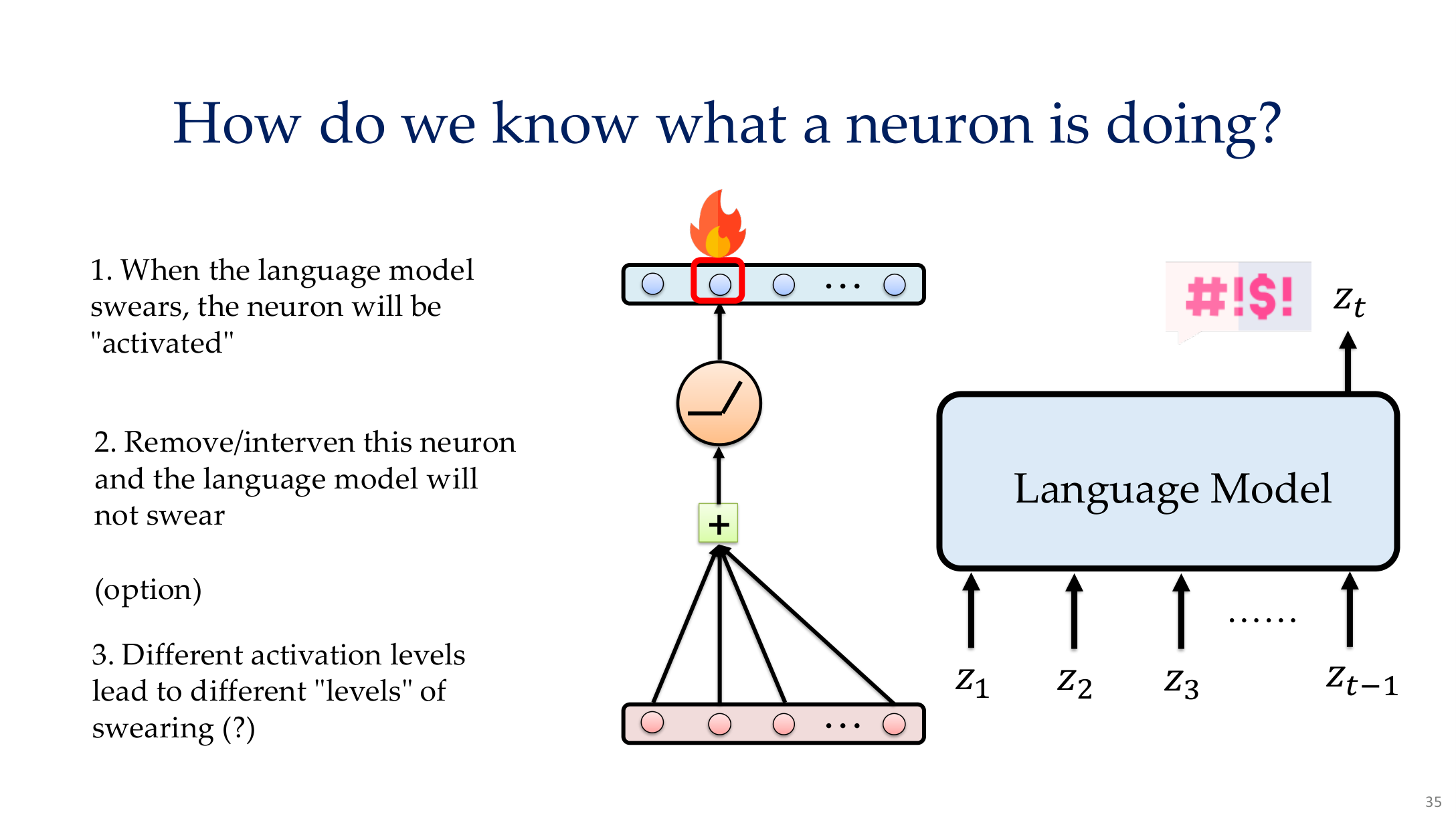
Source: Tufts EE141 Trusted AI, Lecture 8, Slide 35. Image note: the slide combines activation patterns, example stimuli, and visualization approaches for neuron analysis. Why it matters: mechanistic interpretation needs an evidence chain, not just one highly activating example.
6. Why interpretability matters for security
Interpretability helps reveal shortcut learning and unsafe internal strategies. If a model consistently relies on background artifacts, watermarks, or trigger regions, then:
- it is more likely to fail under shift
- it is more vulnerable to adversarial attacks
- it may be easier to detect backdoors or spurious correlations
That is why this page connects naturally to Backdoor Attacks and AI Alignment.
7. Robustness as the stability side of trustworthiness
7.1 Adversarial robustness
If very small perturbations can flip predictions, then attractive explanations alone do not make a model trustworthy:
See Adversarial Attack & Defense and FGSM & PGD.
7.2 Distribution shift and OOD
Real deployments fail under:
- sensor and formatting changes
- domain shift in language or user populations
- retrieval distributions that do not match training data
7.3 Uncertainty estimation
Uncertainty estimation links interpretability, robustness, and governance because it allows systems to defer, abstain, escalate, or request human review when the model is unsure.
Relations to other topics
- For the high-level safety frame, see AI Safety Overview
- For adversarial robustness, see Adversarial Attack & Defense and FGSM & PGD
- For alignment links, see AI Alignment
- For shortcut and trigger analysis, see Backdoor Attacks
References
- Tufts EE141 Trusted AI Course Slides, Interpretable AI Lecture, Spring 2026.
- Ribeiro et al., "Why Should I Trust You?", KDD 2016.
- Selvaraju et al., "Grad-CAM", ICCV 2017.
- Sundararajan et al., "Axiomatic Attribution for Deep Networks", ICML 2017.
- Nanda et al., mechanistic interpretability references, 2023.