LLM Jailbreaking
LLM jailbreaking is the process of inducing a model to bypass its own safety boundaries and produce content it should refuse, restrict, or downgrade. Unlike classical adversarial examples, jailbreaks usually operate at the instruction, context, and policy level rather than through tiny pixel perturbations.
Jailbreaks are better understood as a family of prompt-based, token-based, multi-turn, and automated black-box attacks rather than as isolated prompt tricks.

Source: Tufts EE141 Trusted AI, Lecture 6, Slide 7. Image note: the figure places reliability, safety, fairness, counter-misuse, privacy, and alignment on one map. Why it matters: jailbreaks are only one subproblem inside a broader LLM-security landscape.
1. What a jailbreak is
1.1 Jailbreak vs prompt injection
These are related but not identical:
| Concept | Goal | Typical context |
|---|---|---|
| Jailbreak | bypass refusal or safety policy | unsafe answers from the model |
| Prompt injection | hijack system intent via untrusted input | RAG and agent control-flow compromise |
In simple chat settings they may look similar. In agent systems, prompt injection is more about control-flow hijacking, while jailbreaking is more about policy bypass.
1.2 Why LLMs are vulnerable
Alignment training makes models more likely to refuse, but it does not turn refusal into a formal hard constraint. Attackers only need to find prompts that are linguistically plausible yet shift the model into a less safe behavioral region.

Source: Tufts EE141 Trusted AI, Lecture 6, Slide 38. Image note: the slide defines jailbreaking as making a target LLM generate content it should refuse. Why it matters: the core issue is not quirky wording; it is that the model's behavior boundary can be reinterpreted or bent.
2. Attack classes
2.1 Prompt-based jailbreaks
Common families include:
- role-play and fictional framing
- “ignore previous instructions” patterns
- decomposition into seemingly harmless subproblems
- encoding, translation, or abstraction wrappers
2.2 Token-based attacks
These are closer to optimization-based adversarial attacks. Typical examples include:
- GCG
- AutoDAN-style token search
- suffix optimization against aligned models

Source: Tufts EE141 Trusted AI, Lecture 6, Slide 47. Image note: color-coded breakdown of GCG into Goal string (G), Target string (T), and Suffix (S) with the optimization objective. Why it matters: GCG turns jailbreaking into an optimizable discrete search problem — the fundamental difference between token-based and prompt-based attacks.
2.3 Multi-turn jailbreaking
Multi-turn attacks gradually establish context, test boundaries, and decompose harmful tasks across several dialogue turns. They are especially dangerous when systems have memory, planners, or tools.
2.4 Automated black-box attacks
Real-world closed models often do not expose gradients, but they do expose:
- an API
- a refusal/compliance signal
- enough retries for search
That makes black-box prompt optimization practical.
Source: Tufts EE141 Trusted AI, Lecture 6, Slide 44. Image note: the timeline places token-level and prompt-level jailbreak families on one axis. Why it matters: attacks are evolving from handcrafted templates toward programmatic search, so defenses have to target attack-generation mechanisms, not just specific strings.
Source: Tufts EE141 Trusted AI, Lecture 6, Slide 49. Image note: the figure turns “Engineer the prompt → model → response” into a closed-loop attack diagram. Why it matters: closed models without gradient access are still vulnerable as long as attackers get observable success/failure feedback.
Source: Tufts EE141 Trusted AI, Lecture 6, Slide 55. Image note: the slide contrasts single-turn and multi-turn dialogue structures. Why it matters: multi-turn attacks are dangerous precisely because each individual turn may look harmless while the full context drifts into unsafe behavior.
Source: Tufts EE141 Trusted AI, Lecture 6, Slide 58. Image note: the same dangerous prompt is fed to Qwen3 (weak-yet-unaligned) and Claude 3.7 (strong-yet-aligned), showing starkly different responses. Why it matters: decomposition attacks exploit the gap between capability and alignment — models that are capable but poorly aligned are most vulnerable.
3. Escalation and layered defense
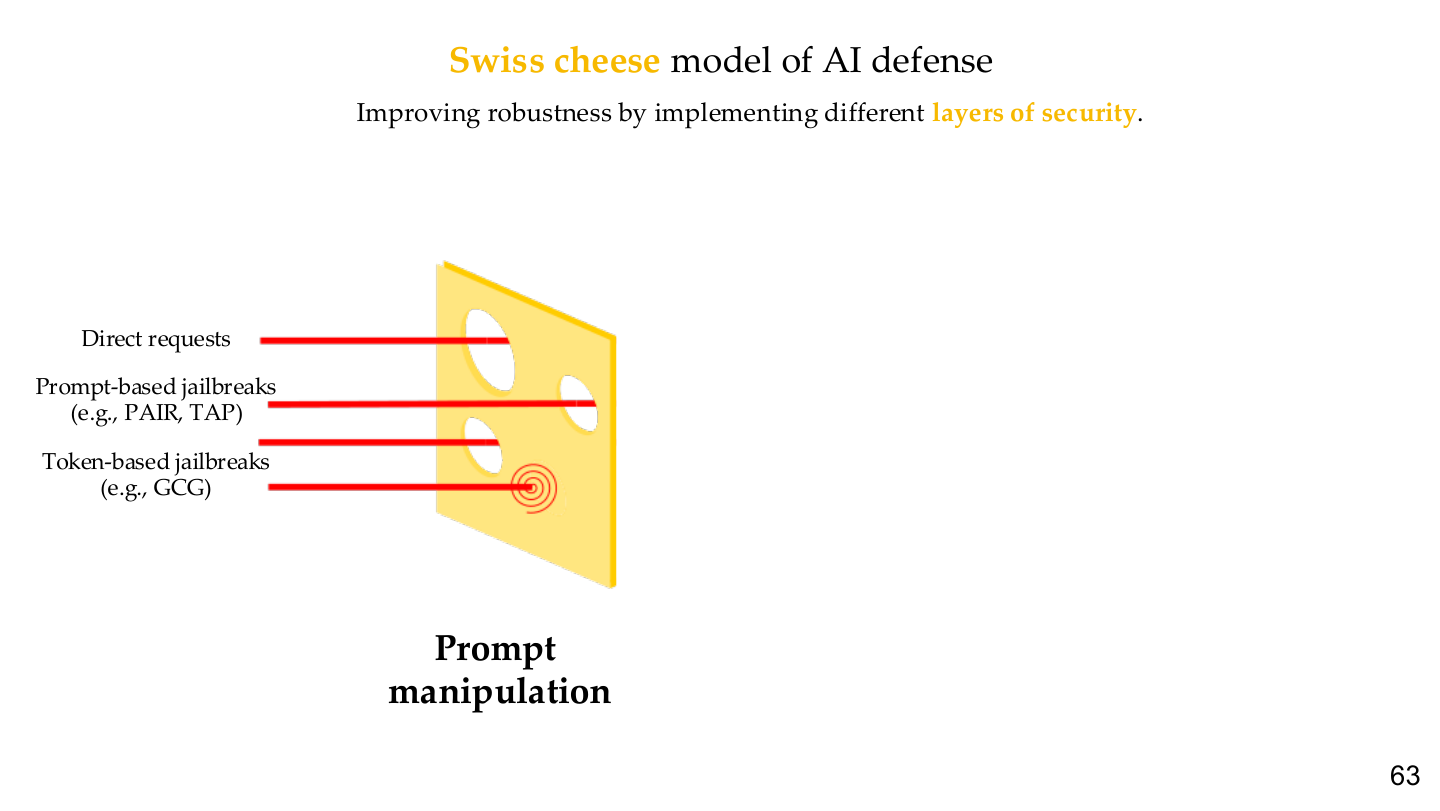
Source: Tufts EE141 Trusted AI, Lecture 6, Slide 63. Image note: the figure shows direct requests, prompt-based jailbreaks, and token-based jailbreaks as attacks that can pass through different “holes” in layered defenses. Why it matters: no single guardrail is enough.

Source: Tufts EE141 Trusted AI, Lecture 6, Slide 61. Image note: the slide puts black-box and white-box attack settings, mitigation, compatibility, and efficiency on one page. Why it matters: a useful defense is not just one that lowers attack success, but one that does so without destroying normal capability or deployment practicality.
4. Representative attack patterns
| Type | Mechanism | Risk |
|---|---|---|
| Role-play | places the model in an alternate persona | policy interpreted as fictional |
| Decomposition | breaks harmful intent into harmless-looking substeps | each substep may evade refusal |
| Encoding / transformation | hides intent behind format changes | bypasses surface-level filters |
| Indirect injection | embeds instructions in retrieved content | hijacks agents and RAG systems |
5. Why jailbreaks are hard to defend
5.1 Policy boundaries are not formal proofs
Refusal policies are learned behavioral tendencies, not cryptographic or formally verified constraints.
5.2 Attackers can retry indefinitely
In security, 99% success can still mean failure because attackers can keep trying. This is especially relevant when models expose cheap, repeated API access.
5.3 Stronger systems amplify consequences
If the model only chats, jailbreaks may produce unsafe text. If the model can also:
- read internal documents
- call tools
- execute code
- send messages
then jailbreaks quickly become system compromises.
6. Defense ideas
6.1 Training-time defenses
Typical training-time strategies include:
- safety fine-tuning
- adversarial data augmentation
- refusal-policy tuning
- Constitutional AI and critique-style training
- continuous regression against jailbreak benchmarks
6.2 Inference-time defenses
flowchart LR
A[User / Retrieved Content] --> B[Input guard]
B --> C[Risk classifier]
C --> D[Main model]
D --> E[Output guard]
E --> F[Tool gate / human approval]
Layered defenses typically combine:
- input filtering
- task/risk routing
- output review
- capability gating for dangerous tools
6.3 Why layered defense matters
The course’s “Swiss cheese” framing is important because it prevents a common mistake: assuming that a single moderation model or system prompt is a sufficient security boundary.
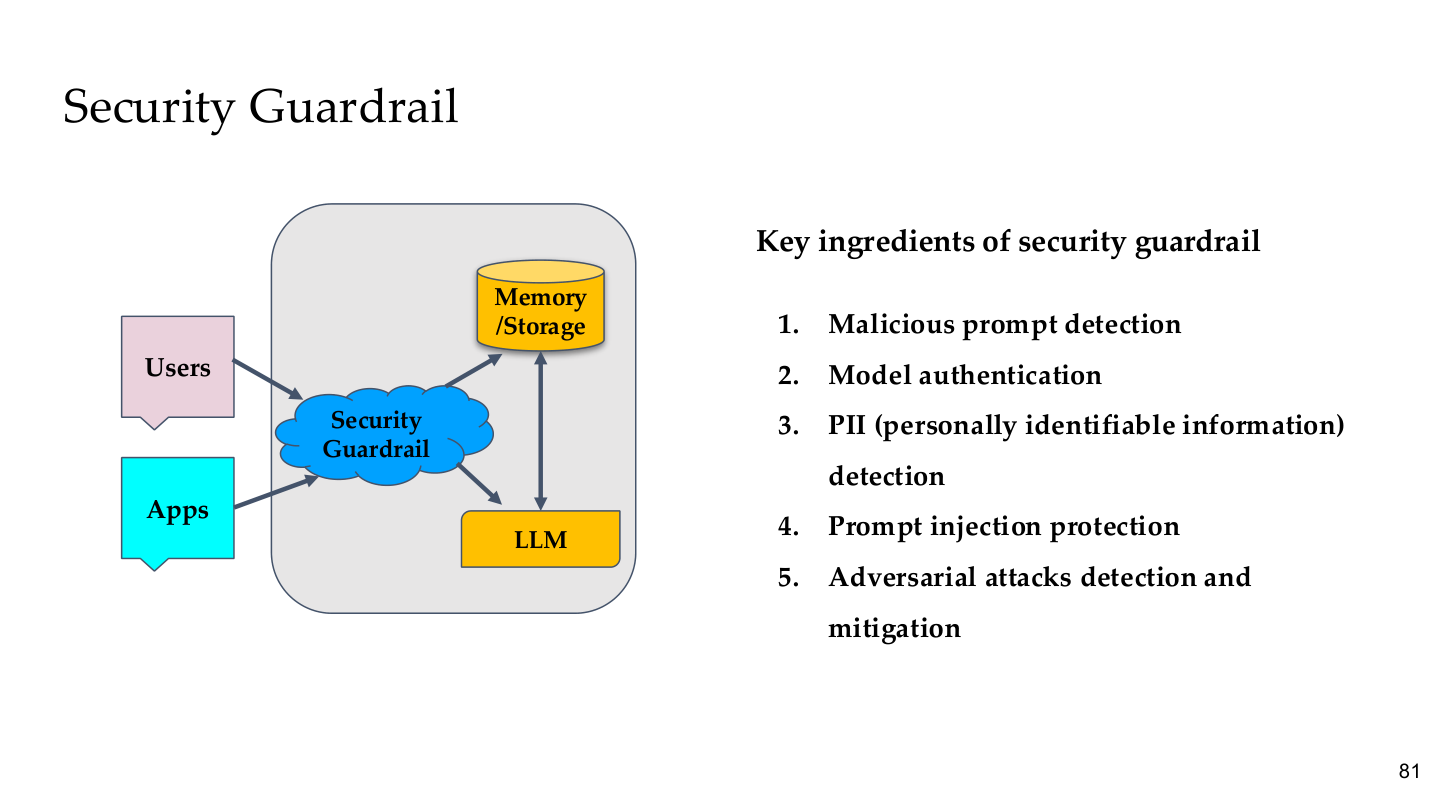
Source: Tufts EE141 Trusted AI, Lecture 6, Slide 81. Image note: the Security Guardrail sits between Users/Apps and LLM/Memory, with five core components listed. Why it matters: a guardrail is a system-level component independent of the model — even if the model itself is bypassed, the external guardrail can still intercept.
7. Links to red teaming, alignment, and system security
7.1 Red teaming
Jailbreak evaluation is one major component of Red Teaming, but not the whole story. Red teams also evaluate:
- prompt leakage
- tool misuse
- secret exfiltration
- memory contamination
- multi-stage attack chains
7.2 Alignment
Jailbreaks expose behavior-boundary failures; alignment is the broader question of whether the model has learned the intended objectives and values at all. See AI Alignment.
7.3 System security
The most dangerous jailbreak is not a compromised chatbot, but a compromised agent with access to system resources. See:
Relations to other topics
- For adversarial ML parallels, see Adversarial Attack & Defense
- For multimodal injection, see Visual Instruction Injection
- For deployment and governance controls, see AI Engineering Safety & Governance
- For value-level questions, see AI Alignment
References
- Tufts EE141 Trusted AI Course Slides, LLM Security Lecture, Spring 2026.
- Zou et al., "Universal and Transferable Adversarial Attacks on Aligned Language Models", 2023.
- Perez et al., "Red Teaming Language Models with Language Models", EMNLP 2022.
- Willison, "Prompt Injection Explained", 2023.
- OWASP, "Top 10 for Large Language Model Applications", 2025.