AI Safety Overview
AI safety is not a single problem. It is a family of risk-control tasks that span training, inference, deployment, and governance. A more useful framing is to treat trustworthy AI as a combination of capability, risk, control, and governance rather than reducing the field to adversarial examples alone.
This page serves as the overview page for the AI Safety & Trustworthiness section. Its job is to establish the main frame: a unified threat model, four major risk surfaces, and a reading map. Detailed engineering controls such as permissions, isolation, and audit trails are intentionally pushed into AI Engineering Safety & Governance and LLM & Agent System Security.
1. What trustworthy AI means
Trustworthy AI means that a system is capable of performing useful tasks, does not fail catastrophically under realistic attack or misuse conditions, and remains interpretable, auditable, and governable.
graph TD
A[Trustworthy AI] --> B[Capability]
A --> C[Risk]
A --> D[Control]
A --> E[Governance]

Source: Tufts EE141 Trusted AI, Lecture 1, Slide 74. Image note: the slide juxtaposes policy pages and data-breach headlines. Why it matters: trustworthy AI is shaped by technical design and institutional control at the same time.
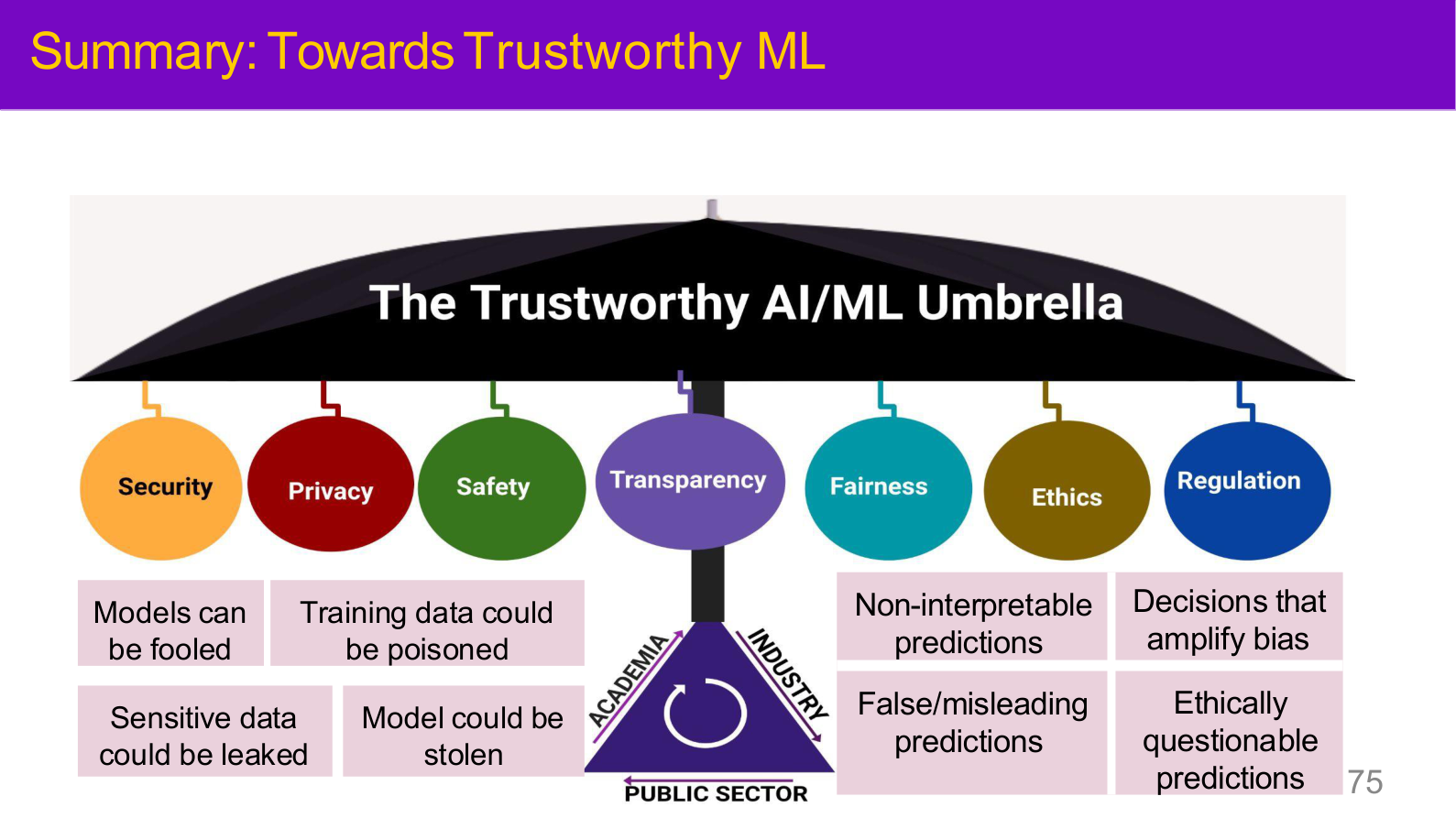
Source: Tufts EE141 Trusted AI, Lecture 1, Slide 75. Image note: an umbrella diagram places Security, Privacy, Safety, Transparency, Fairness, Ethics, and Regulation as seven co-equal pillars. Why it matters: AI safety is not just about resisting attacks — it spans privacy, fairness, transparency, and governance as a systemic concern.
1.1 Trustworthy does not mean absolutely secure
Because AI systems are probabilistic, the realistic goal is not perfect invulnerability but:
- explicit threat models
- layered controls
- clear trade-offs between accuracy, usability, and risk
- continuous evaluation and incident response
1.2 How AI safety differs from ordinary software security
| Dimension | Traditional software | AI systems |
|---|---|---|
| Behavior definition | explicit logic | implicit behavior learned from data and parameters |
| Failure mode | deterministic bugs | probabilistic failure, drift, shortcut learning, misalignment |
| Attack surface | input, protocol, permissions | plus data, representations, loss functions, prompts, and runtime context |
2. Minimal ML/DL background
This page keeps only the ML/DL background that matters for safety and links out to ML Basics and Supervised Learning for the rest.
2.1 Why learning systems expose attack surfaces
Supervised learning optimizes empirical risk:
Every part of this objective can become an attack surface:
- attack \(x\): adversarial examples
- attack labels or data distribution: backdoors
- attack the output interface: membership inference and model extraction
- attack the runtime context: LLM jailbreaks and system-level prompt injection
2.2 Why deep models are brittle
Deep models are vulnerable because:
- local linearity is often enough to change outputs in high dimensions
- training objectives do not perfectly match deployment objectives
- deployment distributions shift
- models frequently learn shortcuts rather than causal structure
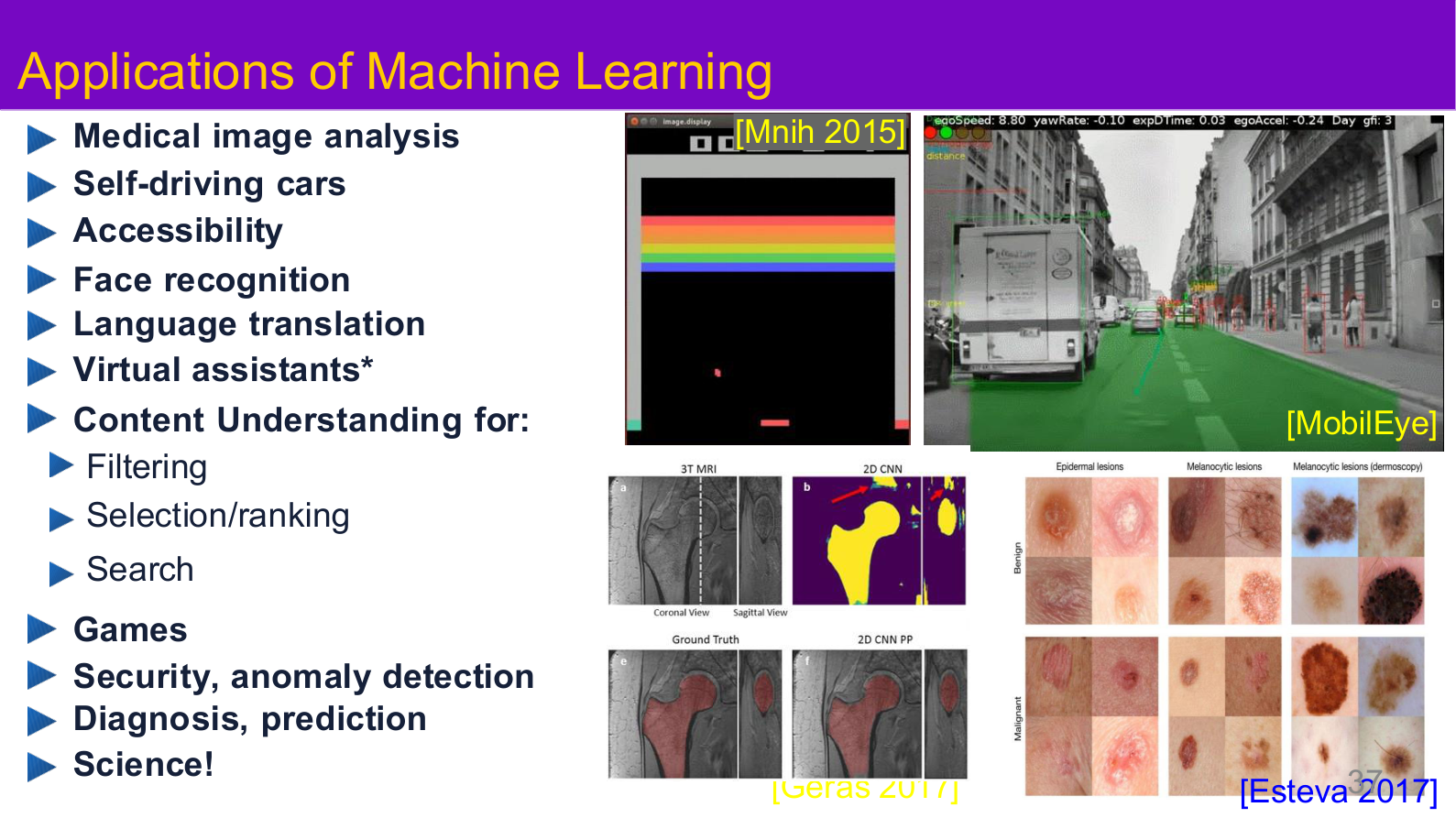
Source: Tufts EE141 Trusted AI, Lecture 1, Slide 37. Image note: the slide places medical imaging, autonomous driving, content understanding, and scientific use cases on the same map. Why it matters: attack surfaces become complex because the same learning machinery is reused in settings with very different risk tolerances.

Source: Tufts EE141 Trusted AI, Lecture 1, Slide 46. Image note: the page contrasts current strengths with current limits of deep learning. Why it matters: trustworthy deployment starts by acknowledging capability boundaries instead of assuming control layers can compensate for immature model abilities.
3. A unified threat-model view
3.1 By lifecycle stage
| Stage | Main risks | Examples |
|---|---|---|
| Data collection / training | poisoning, backdoors, privacy leakage | malicious examples, compromised pretraining sources |
| Evaluation | incomplete benchmarks, undisclosed dangerous capability | average accuracy without high-risk testing |
| Inference interface | adversarial examples, model theft, membership inference | black-box queries, evasion, API abuse |
| LLM orchestration | prompt injection, jailbreaks, tool misuse | indirect injection, refusal bypass |
| Infrastructure | side channels, secrets leakage, weak isolation | shared accelerators, cache bugs, logging leaks |
3.2 By attacker knowledge and capability
| Dimension | Values | Meaning |
|---|---|---|
| Knowledge | white-box / gray-box / black-box | how much the attacker knows |
| Capability | training-time / inference-time / system-level | where the attacker can intervene |
| Goal | integrity / privacy / availability / misuse | what the attacker wants to break or extract |
This unified view makes it easier to place adversarial ML, LLM jailbreaks, and system security on one map.
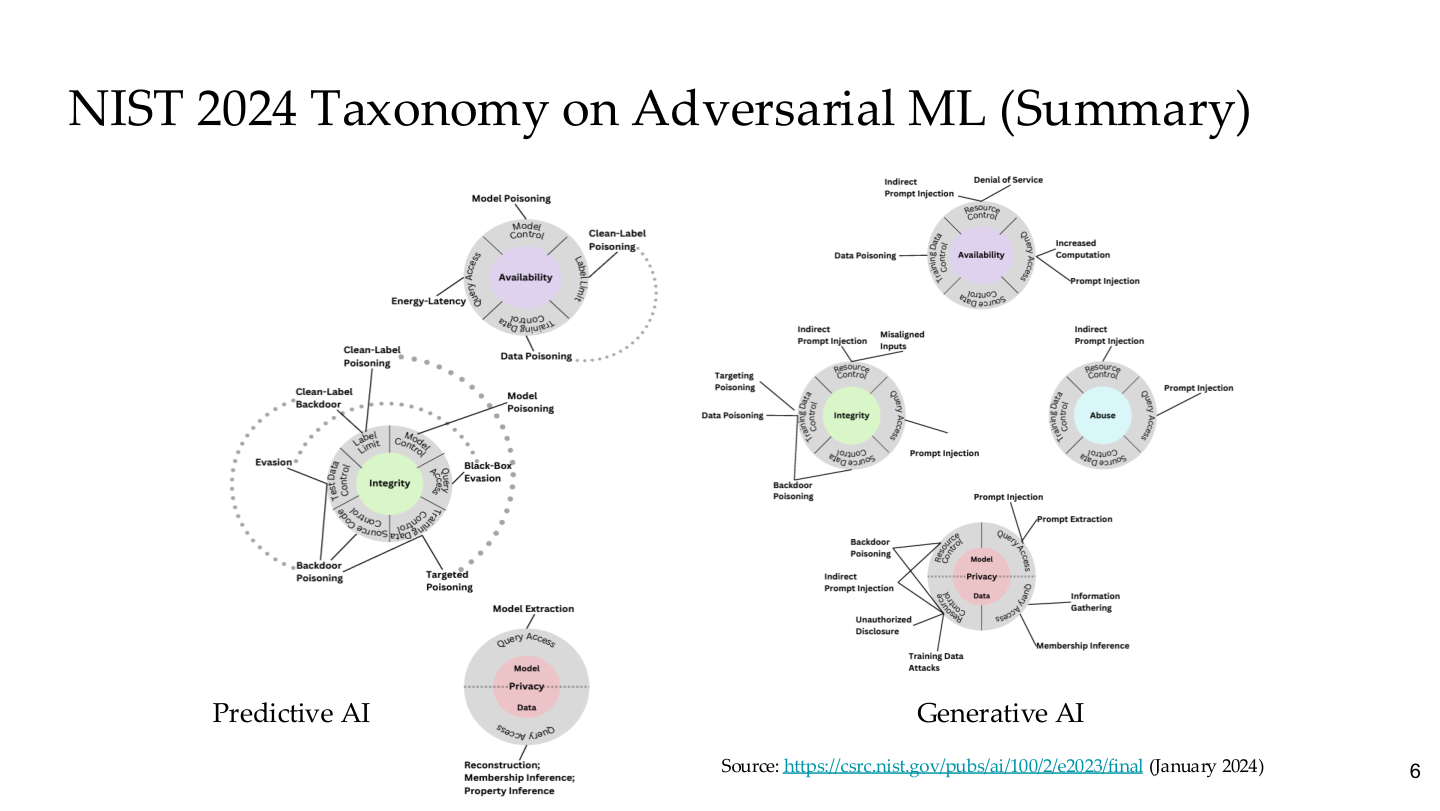
Source: Tufts EE141 Trusted AI, Lecture 6, Slide 6. Image note: side-by-side circular topology maps break down attack surfaces for Predictive AI and Generative AI across availability, integrity, and privacy. Why it matters: NIST places traditional ML attacks and LLM attacks in a single taxonomy — adversarial security is one unified discipline, not two isolated fields.
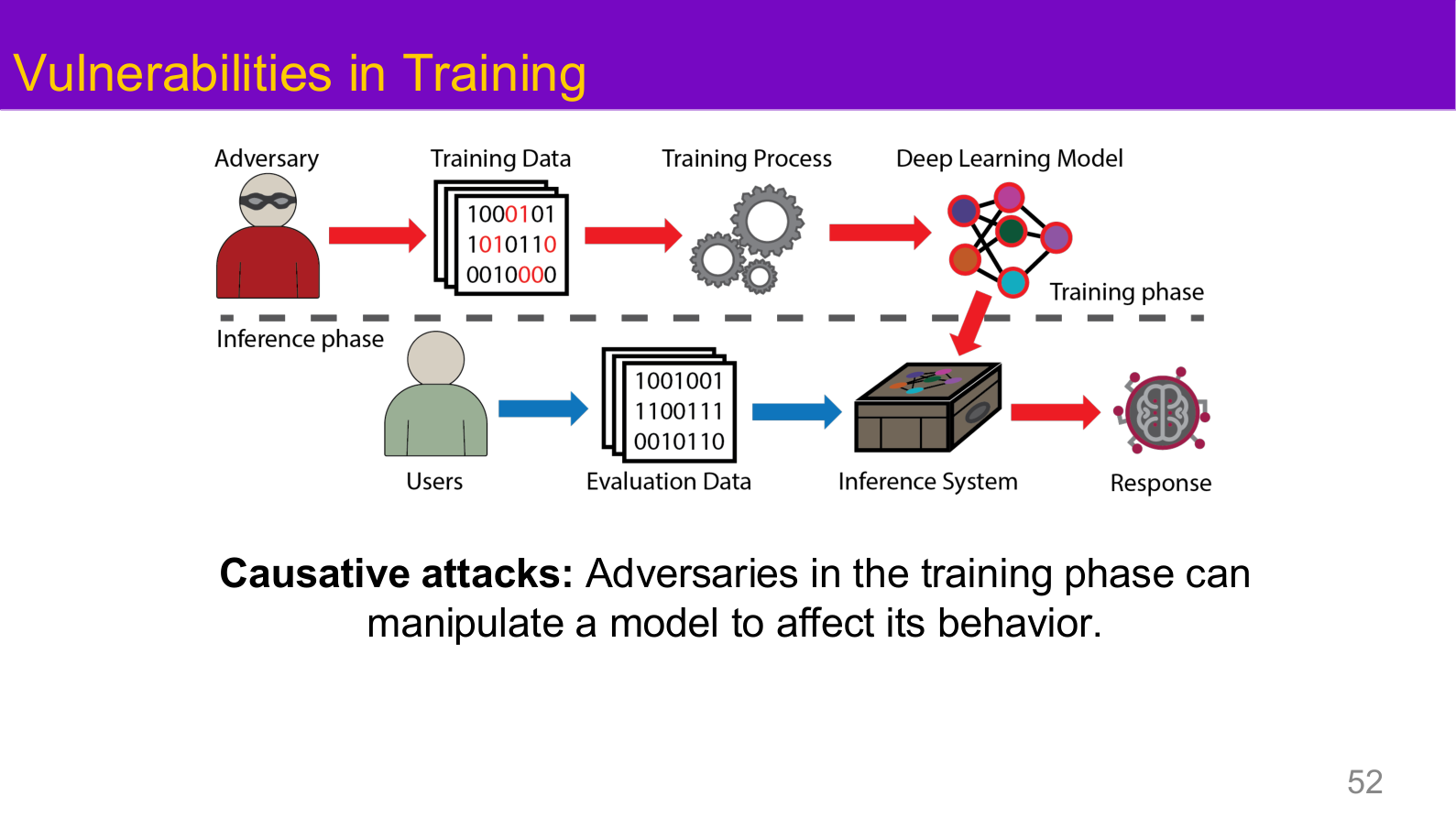
Source: Tufts EE141 Trusted AI, Lecture 1, Slide 52. Image note: the standard ML pipeline is annotated in red to show how an adversary injects malicious data during training. Why it matters: all backdoor attacks and data poisoning fall under this "training-phase attack surface" — understanding this is a prerequisite for layered AI security.
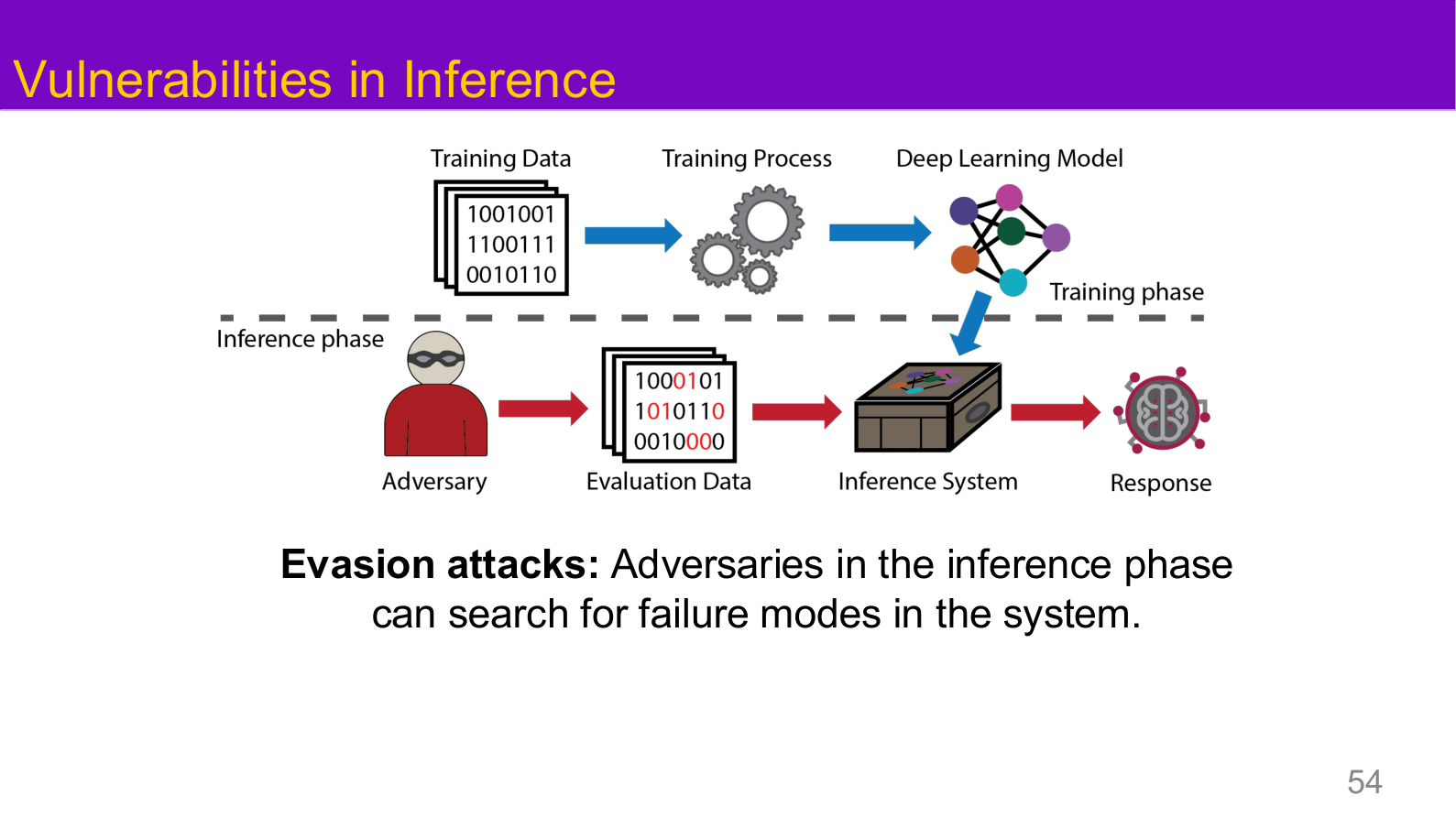
Source: Tufts EE141 Trusted AI, Lecture 1, Slide 54. Image note: the attacker is placed at inference time, manipulating inputs without altering the model itself. Why it matters: adversarial examples, jailbreaks, and prompt injection all belong to inference-phase attacks, forming the complementary half of the threat model alongside training-phase attacks.
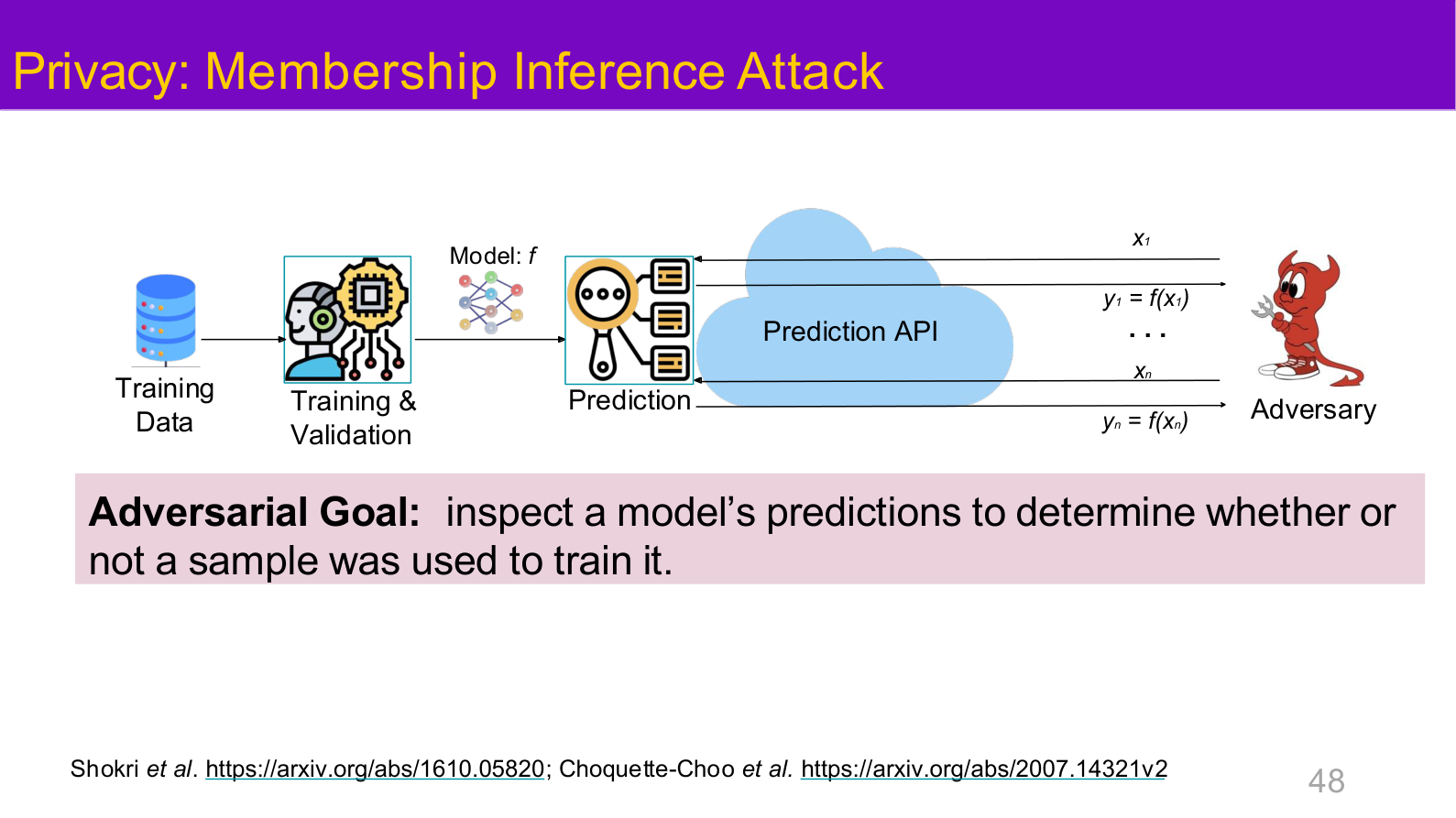
Source: Tufts EE141 Trusted AI, Lecture 1, Slide 48. Image note: the overview slide singles out membership inference as a representative privacy risk. Why it matters: privacy is not a side topic; it is a primary attack surface in a trustworthy-AI threat model.
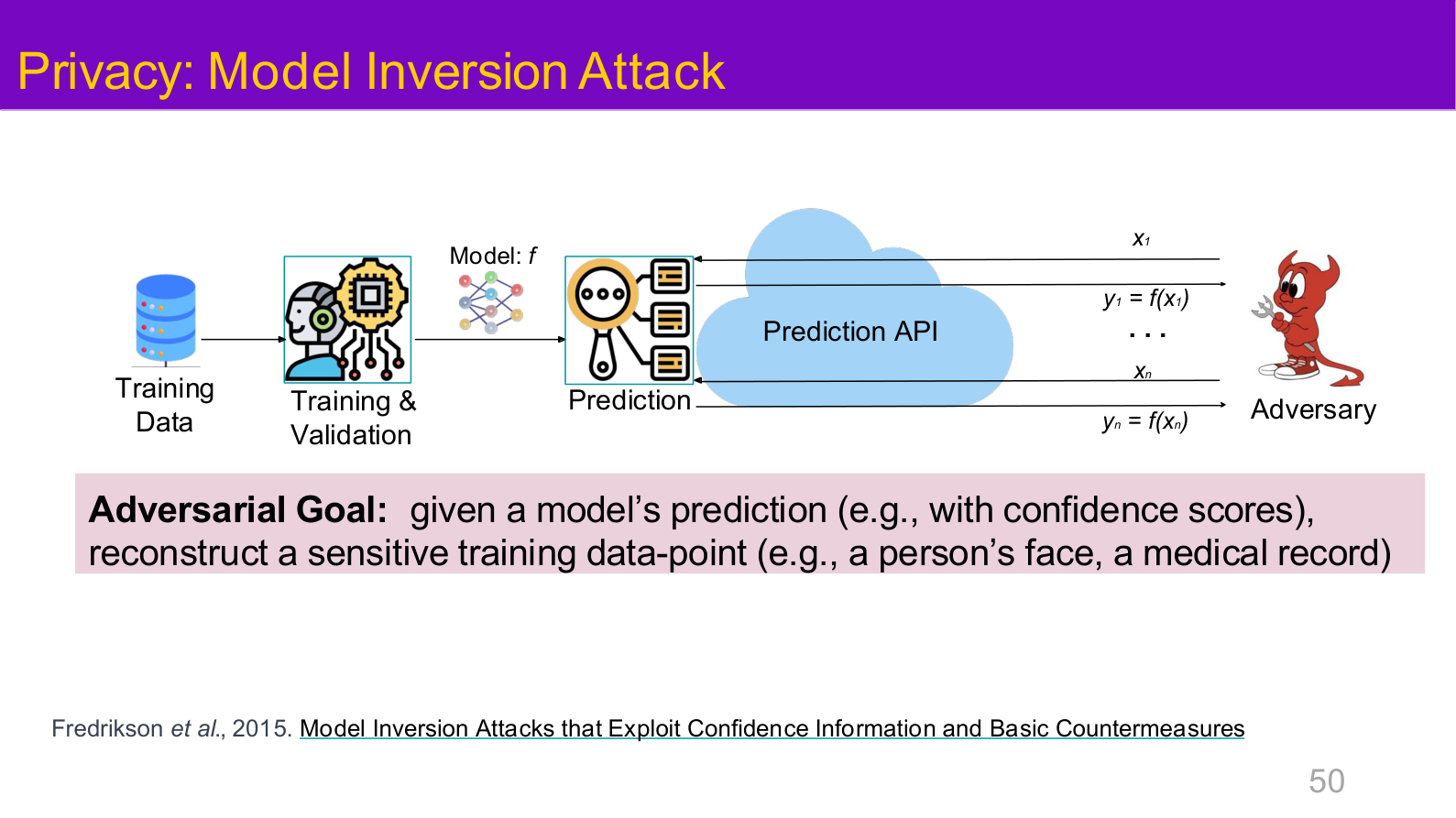
Source: Tufts EE141 Trusted AI, Lecture 1, Slide 50. Image note: the slide places model inversion directly in the high-level risk map. Why it matters: whether a model leaks training information should be treated as a core system property, not as an afterthought for compliance teams.
4. Main risk surfaces
4.1 Adversarial robustness
Adversarial attacks typically solve:
Key questions include:
- how white-box attacks construct worst-case perturbations
- how black-box attacks rely on transferability
- how physical attacks survive sensing and preprocessing
- whether a defense truly improves robustness or just hides gradients
See Adversarial Attack & Defense and FGSM & PGD.
4.2 Backdoors and poisoning
Backdoor attacks do not perturb inputs at inference time. They implant shortcut features during training so that the model behaves normally on clean inputs but misclassifies when a trigger appears.
See Backdoor Attacks.
4.3 Privacy and information leakage
Privacy risks in the course are usefully broken into:
- membership inference
- attribute inference
- model inversion
- model extraction and training-data extraction
See Privacy Attacks.
4.4 LLM security
LLM systems add new attack surfaces:
- system prompts versus user prompts
- retrieved documents and external tools
- memory, plugins, and code execution
- gaps between refusal policy and real-world capabilities
See:
4.5 Interpretability and alignment
Interpretability asks why a model behaves the way it does; alignment asks whether the model is pursuing the right objectives and boundaries in the first place.
See:
5. Defense is a layered system, not a single technique
flowchart LR
A[Data and supply chain] --> B[Training]
B --> C[Evaluation and red teaming]
C --> D[Application orchestration]
D --> E[Permissions and isolation]
E --> F[Monitoring and response]
A mature defense posture usually includes:
- data provenance and supply-chain review
- robust training, privacy protection, and alignment tuning
- dangerous-capability evaluation and red teaming before release
- logging, throttling, anomaly detection, and incident response after release
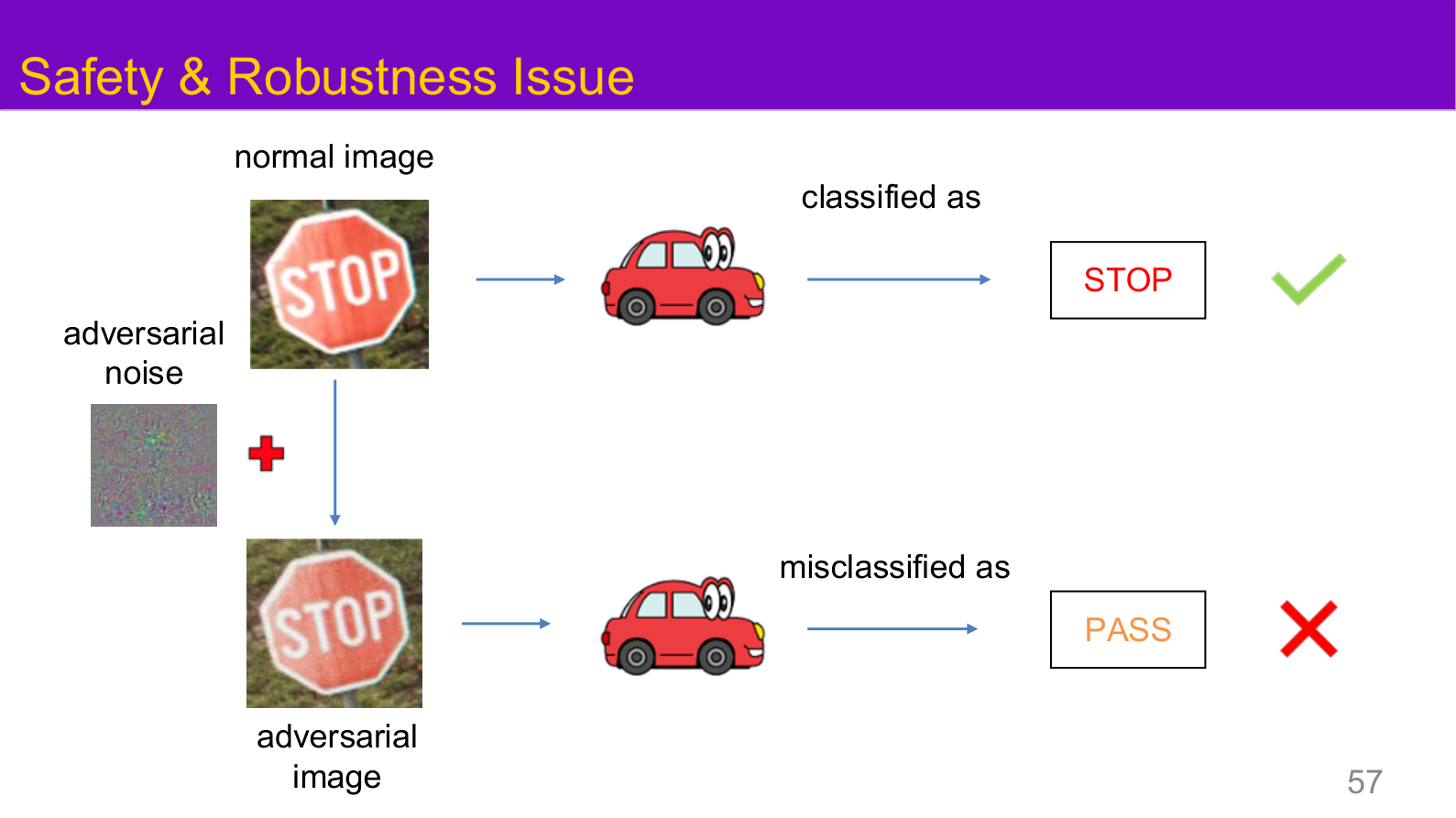
Source: Tufts EE141 Trusted AI, Lecture 1, Slide 57. Image note: the comparison shows the same scene producing opposite system conclusions under normal and adversarial inputs. Why it matters: average accuracy alone cannot capture this failure mode, so robust evaluation has to become explicit.
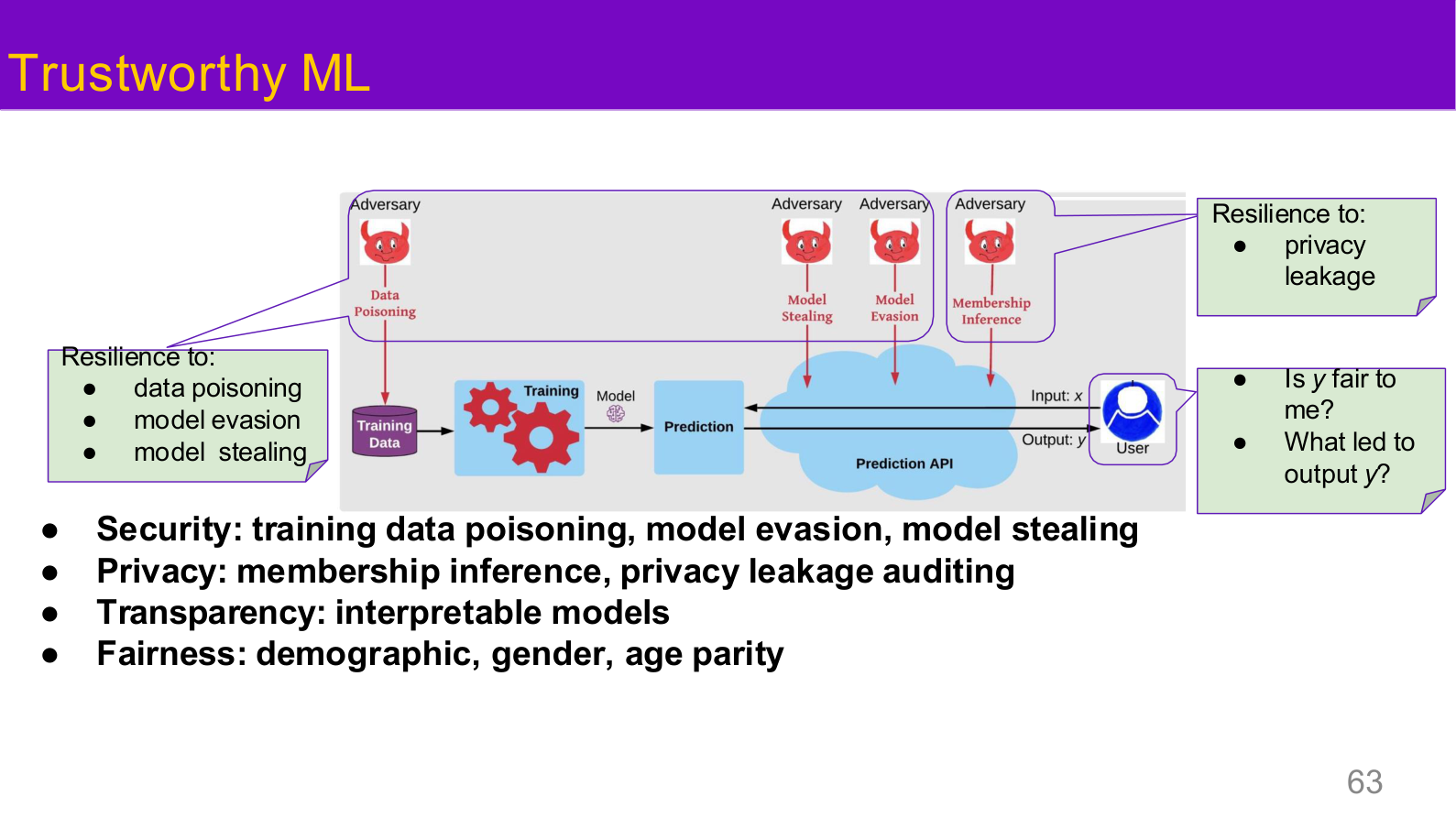
Source: Tufts EE141 Trusted AI, Lecture 1, Slide 63. Image note: the page places poisoning, evasion, theft, privacy leakage, fairness, and transparency in one diagram. Why it matters: trustworthy AI is a composite property made up of multiple interacting failure modes.

Source: Tufts EE141 Trusted AI, Lecture 1, Slide 66. Image note: the slide connects data collection, algorithm design, implementation, testing, and deployment to concrete accountability questions. Why it matters: governance is not a slogan; it is the assignment of responsibility across the system lifecycle.
6. Reading paths and knowledge map
If you care most about:
- correctness failures during training and inference, start with Adversarial Attack & Defense, FGSM & PGD, and Backdoor Attacks
- information leakage and deletion, start with Privacy Attacks
- large-model behavior bypass and trust boundaries, start with LLM Jailbreaking, Red Teaming, and LLM & Agent System Security
- interpretability, supervision, and governance, start with Explainability & Robustness, AI Alignment, and AI Ethics & Governance
Relations to other topics
- For ML foundations, see ML Basics and Supervised Learning
- For engineering deployment controls, see AI Engineering Safety & Governance and LLM & Agent System Security
- For specific attack surfaces, see Adversarial Attack & Defense, Backdoor Attacks, and Privacy Attacks
- For interpretability and alignment, see Explainability & Robustness and AI Alignment
References
- Tufts EE141 Trusted AI Course Slides, Spring 2026.
- Goodfellow et al., "Explaining and Harnessing Adversarial Examples", ICLR 2015.
- Amodei et al., "Concrete Problems in AI Safety", 2016.
- Carlini et al., "Extracting Training Data from Large Language Models", USENIX Security 2021.
- Mitchell et al., "Model Cards for Model Reporting", FAT* 2019.