可解释性与鲁棒性
可解释性(interpretability / explainability)与鲁棒性(robustness)经常被放在同一章,但它们解决的问题并不相同:前者问“模型为什么这样做”,后者问“模型在输入扰动、分布偏移或系统噪声下是否还能稳定工作”。本页把重心明确调整到 XAI 主体内容,再把鲁棒性作为紧密相关的可信性问题处理。
在安全实践中,这两个方向会频繁相遇:解释信号可以帮助识别 shortcut、偏差和后门;鲁棒性分析可以反过来检验解释方法是否稳定可信。
1. 什么是可解释性
可解释性不是单一技术,而是一组问题:
- 人类能否理解模型给出这个结果的依据?
- 我们能否定位模型依赖了哪些输入区域、概念或内部电路?
- 这种解释是否稳定、可复现、与真实因果机制一致?

图示来源:Tufts EE141 Trusted AI, Lecture 8, Slide 3。图像说明:这一页把 interpretability 和 explainable ML 的定义、问题意识与黑盒模型困境放在同一页里。知识说明:解释性不是“顺手展示个可视化”,而是让人类能够理解和质疑模型决策依据。
1.1 透明模型与黑盒模型
| 类型 | 代表模型 | 可解释性特点 |
|---|---|---|
| 透明模型 | 线性回归、决策树、规则系统 | 结构本身可读,但表达能力有限 |
| 半透明模型 | GAM、稀疏模型、概念瓶颈模型 | 可读性与性能之间折中 |
| 黑盒模型 | 深度网络、Transformer、大语言模型 | 需要 post-hoc 或 mechanistic 方法解释 |

图示来源:Tufts EE141 Trusted AI, Lecture 8, Slide 8。图像说明:图中把透明模型和不透明模型的解释路径做了直接对比。知识说明:当模型本身不可读时,解释任务就必须从”阅读规则”转向”构造证据、概念和机制”。
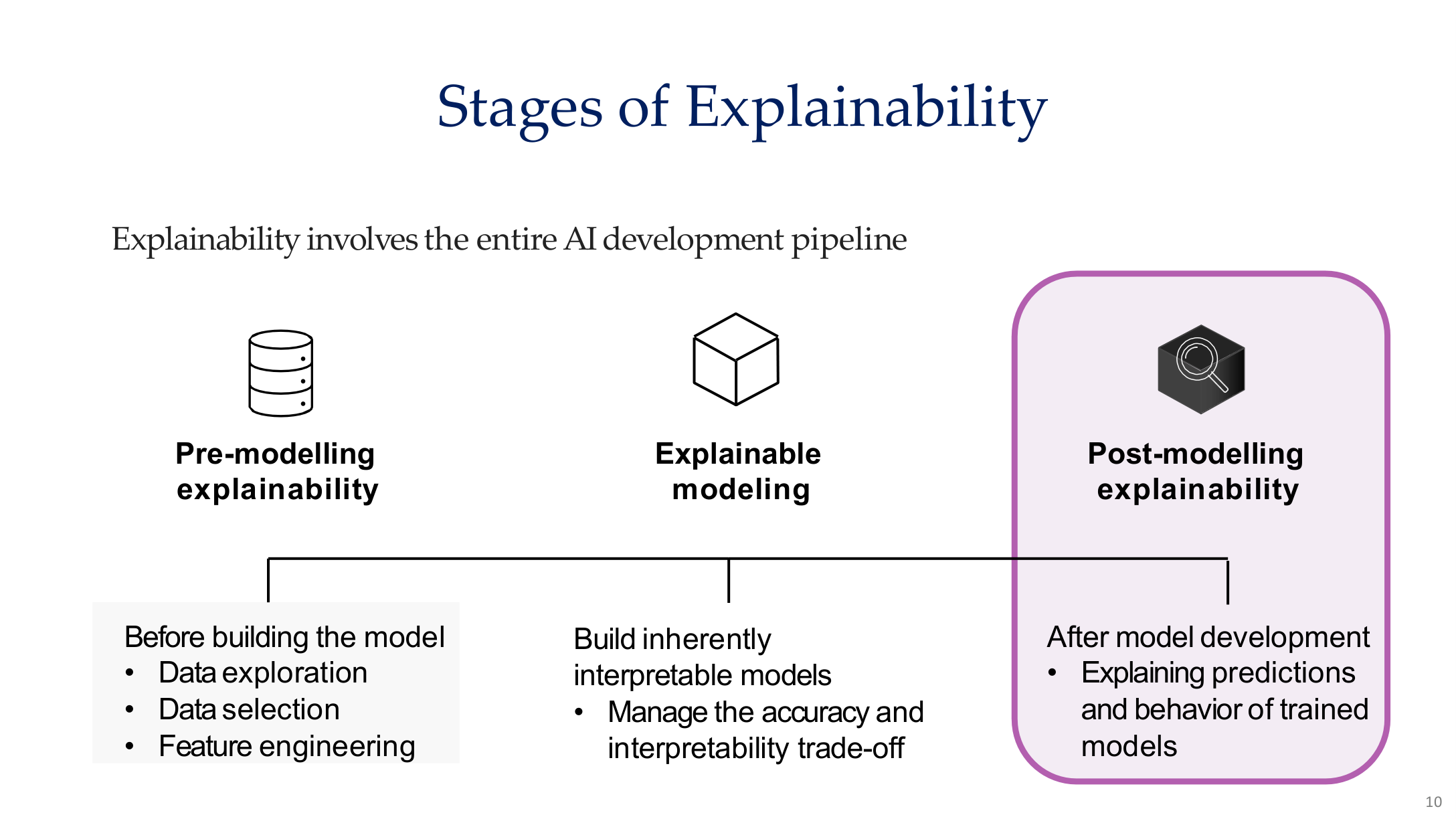
图示来源:Tufts EE141 Trusted AI, Lecture 8, Slide 10。图像说明:页面把可解释性分为建模前、建模中和建模后三个阶段。知识说明:可解释性不是训练完成后才加的功能,而是贯穿整个 AI 开发流程的设计原则。
1.2 解释不是等于”展示 attention”
简单可视化某个 attention head 或权重热力图,并不能自动说明因果作用。好的解释通常要回答三件事:
- 证据落在哪里?
- 模型内部是通过什么表示或机制处理这些证据?
- 当我们删除、替换或干预这些证据时,输出是否真的改变?
2. 可解释性方法的主要类型
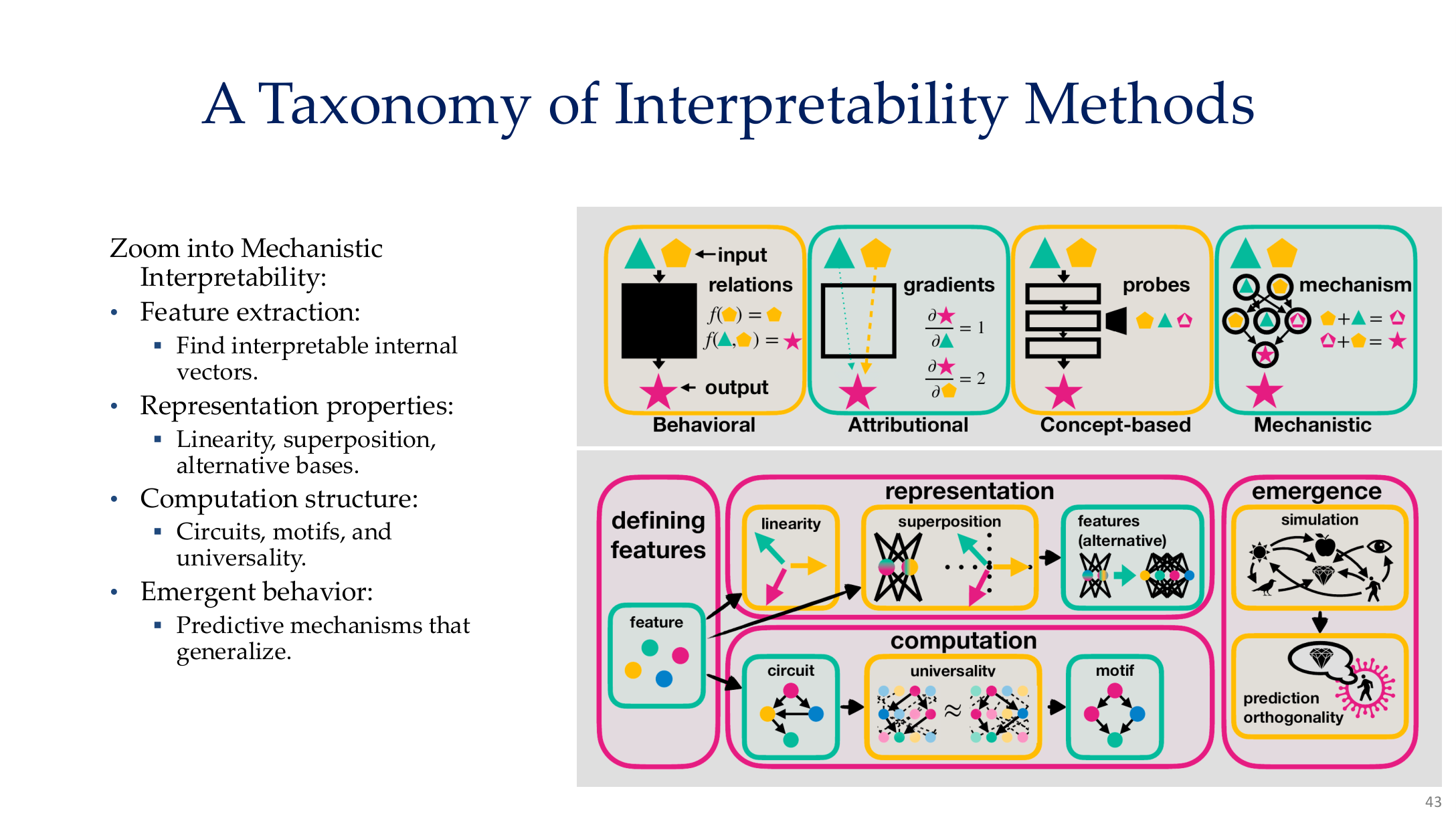
图示来源:Tufts EE141 Trusted AI, Lecture 8, Slide 43。图像说明:图中把 interpretability methods 分成 behavioral、attributional、concept-based 和 mechanistic 四大类,并继续细分 representation、computation 与 emergence。知识说明:这张图非常适合拿来当本页的总导航,因为它避免把 XAI 误解成单一的热力图工具。
2.1 Behavioral explanations
behavioral 方法把模型当作输入输出系统研究,关注:
- 输入变化如何影响输出
- 决策边界附近行为是否稳定
- 反事实输入会产生什么变化
典型方法包括:
- counterfactual explanations
- feature ablation
- sensitivity analysis
- behavioral tests / probing prompts
2.2 Attributional explanations
attributional 方法试图回答“哪些输入维度对当前输出最重要”,常见技术有:
- saliency map
- integrated gradients
- SHAP
- Grad-CAM
它们通常计算某种局部贡献分数:
但要注意:梯度大不一定代表真实语义重要,只说明局部扰动对输出敏感。
2.3 Concept-based explanations
这类方法不直接看像素或 token,而看人类可命名的概念:
- 颜色、纹理、形状
- “是否是猫耳朵”
- “是否包含医学器械”
- “是否触发仇恨语境”
典型工具包括 concept activation vector、TCAV 和 concept bottleneck models。
2.4 Mechanistic interpretability
mechanistic interpretability 研究模型内部线路如何实现计算。课程中强调的重点包括:
- feature extraction:找到可解释内部向量
- representation properties:如 linearity、superposition
- computation structure:circuit、motif、universality
- emergent behavior:复杂能力如何从局部机制中出现
这类方法与 AI对齐 关系非常紧密,因为它们可用于检查模型是否真的学到了我们想要的规则。
3. Grad-CAM 与反事实解释

图示来源:Tufts EE141 Trusted AI, Lecture 8, Slide 20。图像说明:原图、Grad-CAM 热力图和反事实区域抑制图并排出现,展示“支持当前预测的区域”和“若抑制某些区域会转向另一个类别的证据”。知识说明:这能帮助我们区分模型是在看真正对象,还是在利用背景、纹理或 shortcut。
3.1 Grad-CAM

图示来源:Tufts EE141 Trusted AI, Lecture 8, Slide 18。图像说明:图中比较原图、guided backprop 和 Grad-CAM 的热力图结果。知识说明:可解释性方法之间并不只是“图看起来不同”,它们编码的是不同层次的证据聚合方式。
Grad-CAM 通过目标类对中间特征图的梯度来计算通道重要性:
它适合回答:
- 图像中的哪些区域支持当前类别?
- 模型是否把注意力放在合理位置?
- 数据偏差或 spurious correlation 是否显而易见?
3.2 Counterfactual explanation
反事实解释并不只问“为什么是 A”,还问“怎样最小地改变输入,结果就会不是 A”。它更接近人类决策解释方式,因为我们常用“如果没有这个因素,就不会发生”来理解原因。
在图像里,这往往表现为:
- 删除支持当前预测的关键区域
- 增强某个替代类别证据
- 观察决策是否翻转
4. LIME、SHAP 与局部代理方法
4.1 LIME

图示来源:Tufts EE141 Trusted AI, Lecture 8, Slide 23。图像说明:页面用“局部线性近似黑盒模型”的方式解释 LIME。知识说明:LIME 的价值不在于提供全局真相,而在于给单个预测构造一个人类可读的局部解释。
LIME 的基本思想是在样本邻域内构造局部扰动点,然后用一个简单代理模型去逼近复杂模型的局部行为:
其中 \(g\) 是可解释代理模型,\(\pi_x\) 控制邻域权重。
优点:
- 模型无关
- 可直接解释单个预测
局限:
- 对邻域采样敏感
- 不一定稳定
- 解释的是局部近似,而不是全局真实机制
4.2 SHAP
SHAP 借用 Shapley value,把每个特征的贡献定义为在所有特征子集上的边际增益平均。它的优点是理论属性更强,但计算成本通常更高。
5. 机制可解释性与 LLM
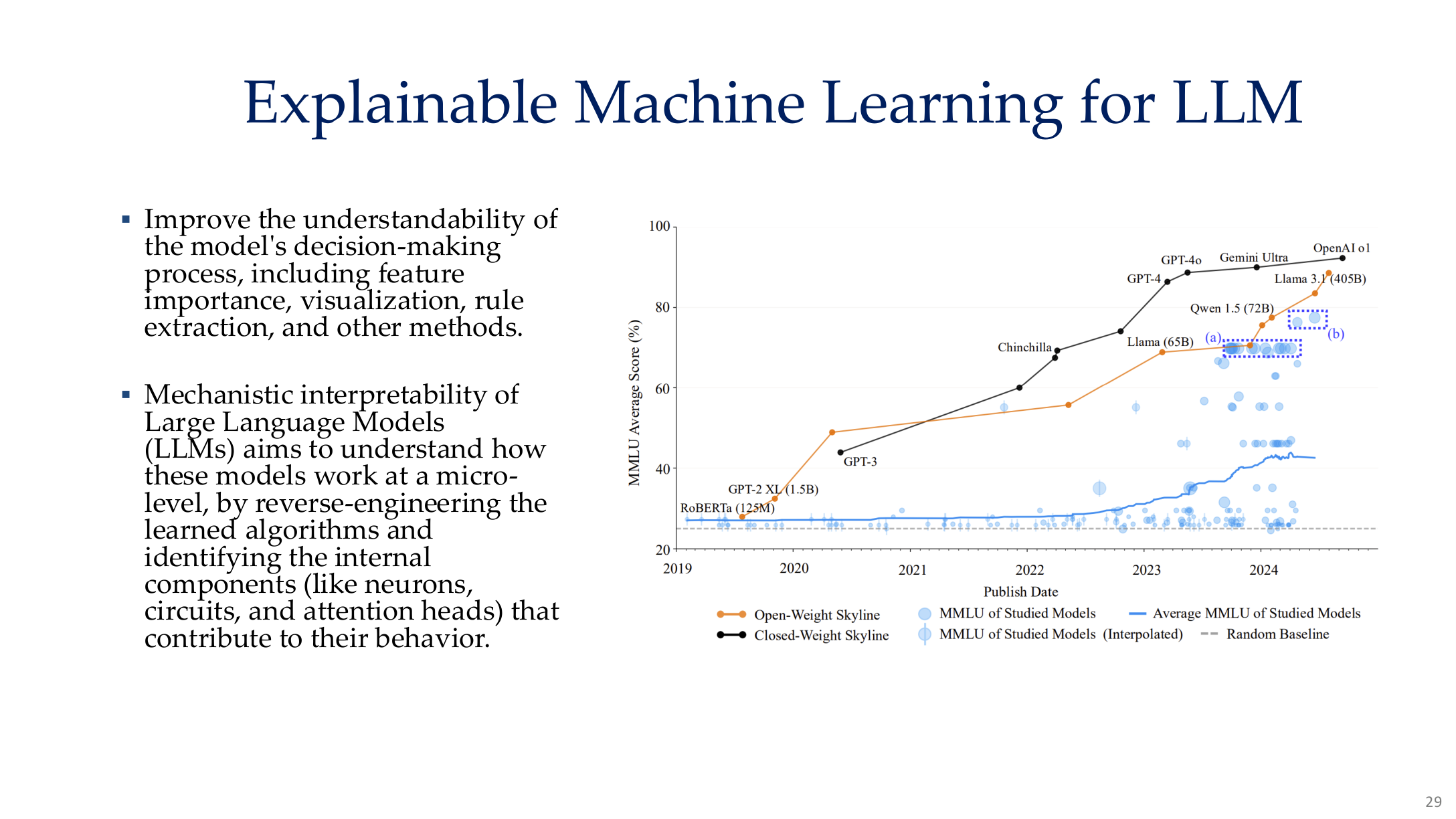
图示来源:Tufts EE141 Trusted AI, Lecture 8, Slide 29。图像说明:图中把更大参数规模、更多层和更复杂行为放到同一坐标里,说明 LLM 的解释需求和传统 CNN 不同。知识说明:对 LLM 来说,解释对象已从“哪一块像素最重要”转向“哪些子机制支撑了能力与失效”。
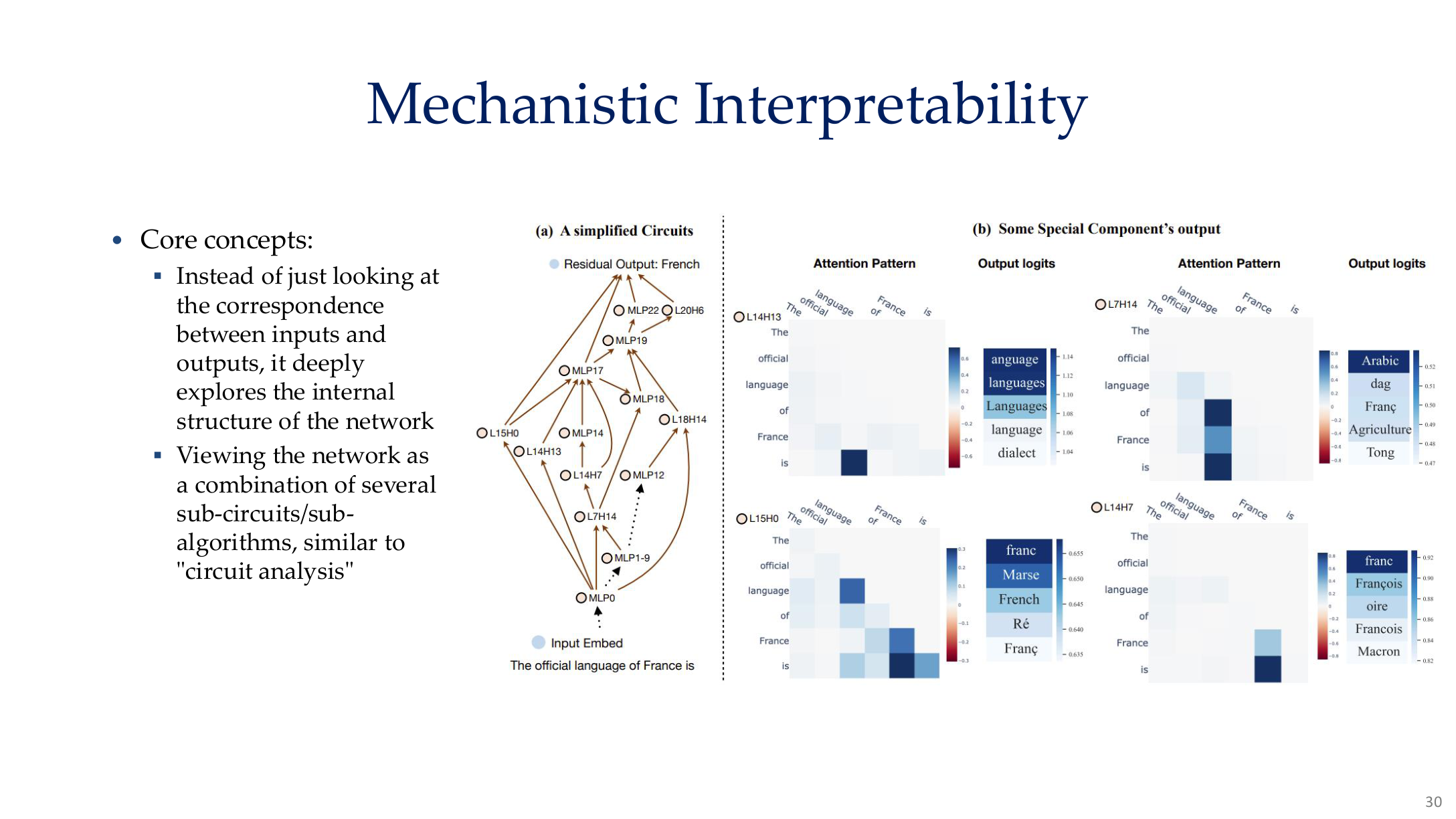
图示来源:Tufts EE141 Trusted AI, Lecture 8, Slide 30。图像说明:页面把特征、注意力路径与子组件激活放在一张图里。知识说明:mechanistic interpretability 关心的不是单个可视化,而是模型内部如何分工完成计算。

图示来源:Tufts EE141 Trusted AI, Lecture 8, Slide 32。图像说明:页面展示 Transformer 的残差流结构,说明每层独立读写、注意力头可加性组合的特性。知识说明:机械可解释性的核心假设是 Transformer 的残差流是线性可叠加的。
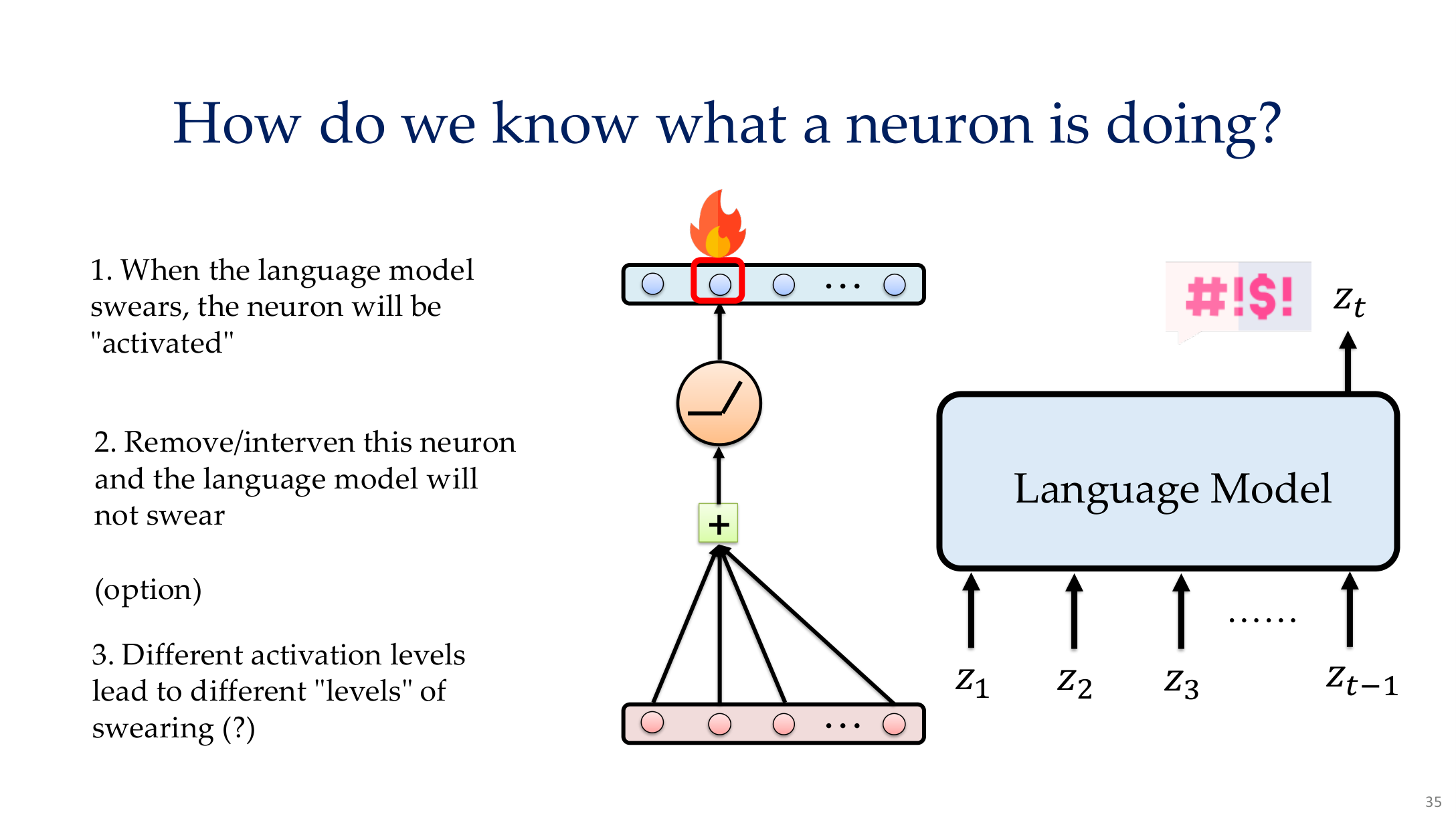
课程里一个重要更新,是把 explainable ML 扩展到了 LLM 和 mechanistic interpretability。对大模型而言,我们更关心:
- 某些 layer / head 是否编码了特定概念
- 模型是否在做 chain-of-thought style intermediate computation
- 某种错误行为能否追踪到一组稳定 circuit
- 安全拒绝、工具选择、事实回忆分别由哪些子机制支撑
这类问题的典型工具包括:
- linear probe
- activation patching
- causal tracing
- sparse autoencoder feature discovery

图示来源:Tufts EE141 Trusted AI, Lecture 8, Slide 33。图像说明:图中用中间状态和概念路径提示语言模型并不是一步到位地产生答案。知识说明:如果想检查 reward hacking、隐蔽偏差或危险规划,必须看中间表示而不是只看最终输出。
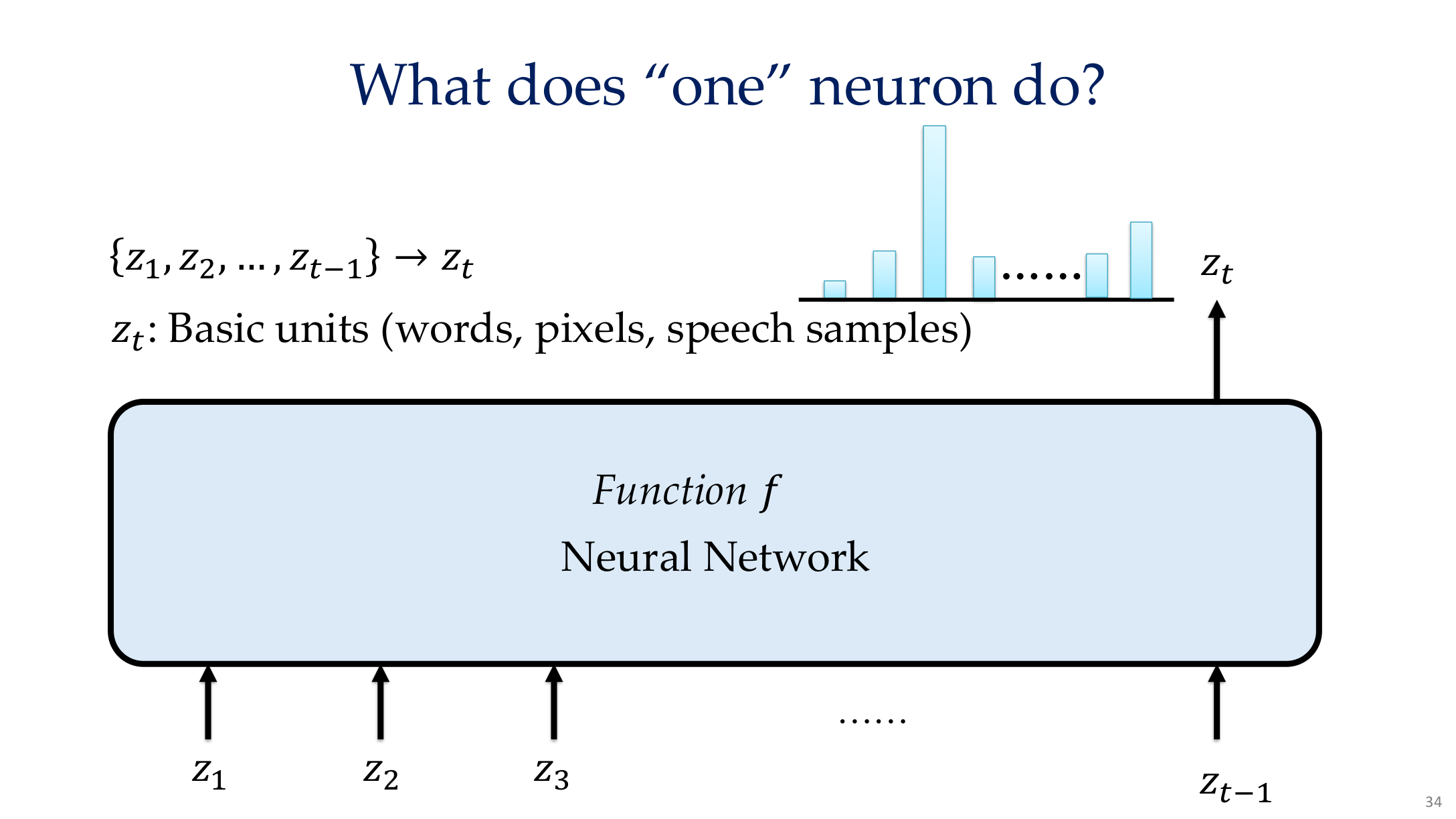
图示来源:Tufts EE141 Trusted AI, Lecture 8, Slide 34。图像说明:页面展示了单个神经元对多个样本的不同响应。知识说明:这提醒我们不要把单个 neuron 直接等同于稳定的人类概念,很多表示是分布式而非局部独占的。
图示来源:Tufts EE141 Trusted AI, Lecture 8, Slide 35。图像说明:图中展示了通过激活模式、刺激样本和可视化方法分析 neuron 的多种途径。知识说明:机制解释需要证据链,而不是看到一个高激活样本就宣布“这个神经元代表某概念”。
6. 为什么解释性与安全强相关
6.1 用解释性发现 shortcut
如果模型总是看背景、watermark 或边缘纹理而不是对象本身,那么:
- 它更可能在分布偏移下失效
- 更容易遭受对抗攻击
- 更可能在后门存在时“看见”触发器捷径
6.2 用解释性辅助后门检测
在后门研究中,热力图和激活异常常被用来判断:
- 模型是否过度依赖局部 patch
- 某个神经元群是否对触发器异常敏感
- 不同类别样本是否被强行拉向同一捷径特征
这也是 后门攻击 与本页经常交叉引用的原因。
7. 鲁棒性:解释之外的稳定性问题
虽然本页重心放在 XAI,但鲁棒性仍然是可信 AI 的基本支柱。
7.1 对抗鲁棒性
若模型只需很小扰动就会改变预测,解释图再漂亮也不能说明模型可信。形式化地说,若存在:
那么模型在该邻域内是不鲁棒的。对应攻击与防御参见 对抗攻击与防御 和 FGSM与PGD。
7.2 分布偏移与 OOD
真实部署中更常见的是:
- 摄像头、传感器、压缩格式变化
- 新领域文本、不同用户群体
- 检索语料和训练语料分布不一致
模型若在这些条件下表现骤降,说明它学到的解释和表示不够稳健。
7.3 不确定性估计
不确定性估计的价值在于:当模型本身知道自己“不知道”时,系统就能触发降级策略、人工复核或拒绝回答。这是连接解释性、鲁棒性与工程治理的桥梁。
8. 阅读建议
如果你的关注点是:
- 视觉解释:重点读 Grad-CAM、counterfactual、LIME
- 大模型内部机理:重点读 mechanistic interpretability
- 安全关联:同时阅读 AI对齐、后门攻击 和 对抗攻击与防御
- 工程落地:结合 AI工程安全与合规 理解解释结果如何进入审计和评测
与其他主题的关系
参考文献
- Tufts EE141 Trusted AI Course Slides, Interpretable AI Lecture, Spring 2026.
- Ribeiro et al., "Why Should I Trust You?", KDD 2016.
- Selvaraju et al., "Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization", ICCV 2017.
- Sundararajan et al., "Axiomatic Attribution for Deep Networks", ICML 2017.
- Nanda et al., "Progress Measures for Grokking via Mechanistic Interpretability", 2023.