String Algorithms
String algorithms frequently appear in competitive programming, so let's examine them separately.
Topics include:
- pattern matching
- string searching
- substring algorithms
- string hashing
- suffix array / suffix tree algorithms
Basic string algorithm: string reversal
Advanced string algorithms:
- KMP, Z-algorithm
- Aho-Corasick automaton (multi-pattern matching)
- Suffix array / suffix automaton related algorithms
- Boyer-Moore, Sunday algorithm, and other advanced string matching techniques
Manacher's Algorithm
Manacher's algorithm is designed specifically for the longest palindromic substring problem. Its essence is a space-for-time tradeoff: it records previously explored information and reuses it.
Problem: Given a string \(s\), find its longest palindromic substring. A brute-force approach takes \(O(n^2)\) or even \(O(n^3)\), while Manacher's algorithm achieves \(O(n)\).
Core idea: Maintain three key pieces of information:
- The palindrome radius \(p[i]\) for each explored position (exploration means expanding outward in both directions to check symmetry)
- The center \(c\) of the current rightmost palindrome
- The rightmost boundary \(r\) that the current known palindrome can reach
Preprocessing: To handle both odd- and even-length palindromes uniformly, insert a special character (e.g., #) between every pair of characters and at both ends, transforming the string to an odd length. For example, aba becomes #a#b#a#, and abba becomes #a#b#b#a#.
Algorithm steps:
- Preprocess the original string to obtain the new string \(t\)
- Maintain an array \(p[i]\) representing the palindrome radius centered at \(t[i]\) (excluding the center itself)
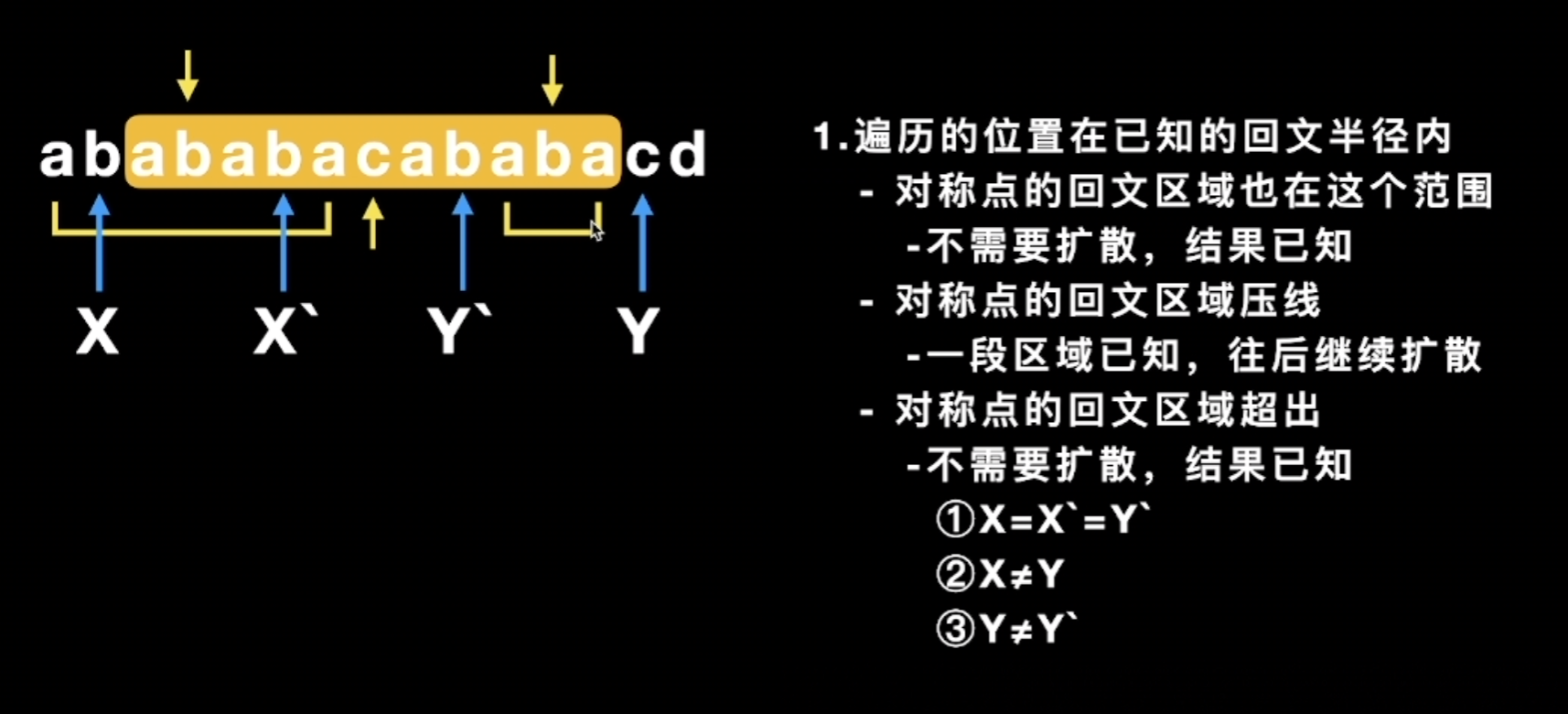
- Iterate over each position \(i\): - If \(i < r\) (within the range of the known rightmost palindrome), exploit symmetry: let \(i' = 2c - i\) (the mirror of \(i\) about \(c\)), and initialize \(p[i] = \min(p[i'], r - i)\) - Otherwise, set \(p[i] = 0\) - Then attempt to expand in both directions; if the characters on both sides are equal, increment \(p[i]\) by 1 - If \(i + p[i] > r\), update \(r = i + p[i]\) and \(c = i\)
- Find the maximum value in the \(p\) array, which gives the radius of the longest palindrome, and trace back to find the position in the original string
Key optimization: When \(i\) falls within the known palindrome range \([c - r, c + r]\), the palindrome information at the mirror point \(i'\) can be directly reused, avoiding a large number of redundant comparisons.
def manacher(s: str) -> str:
# 预处理:插入 '#'
t = '#' + '#'.join(s) + '#'
n = len(t)
p = [0] * n # p[i] = 以 t[i] 为中心的回文半径
c = r = 0 # 当前最右回文的中心和右边界
for i in range(n):
# 利用对称性初始化
if i < r:
mirror = 2 * c - i
p[i] = min(p[mirror], r - i)
# 尝试扩展
while (i + p[i] + 1 < n and i - p[i] - 1 >= 0
and t[i + p[i] + 1] == t[i - p[i] - 1]):
p[i] += 1
# 更新最右边界
if i + p[i] > r:
c, r = i, i + p[i]
# 找最大回文半径
max_len = max(p)
center = p.index(max_len)
# 从变换串的位置还原到原串
start = (center - max_len) // 2
return s[start : start + max_len]
Time complexity: \(O(n)\), as each character is visited by the expansion process at most once. Space complexity: \(O(n)\).
Single-Pattern Exact Matching
KMP
Problem: Find all occurrences of a pattern \(P\) (length \(m\)) in a text \(T\) (length \(n\)). The naive approach requires \(O(nm)\), while KMP optimizes this to \(O(n + m)\). It is the most classic single-pattern exact matching algorithm in theory.
Core idea: Prefix Function (also known as the Failure Function or next array)
When a mismatch occurs during matching, the naive algorithm shifts the pattern one position to the right and restarts the comparison from the beginning. The key insight of KMP is that the already-matched portion of the pattern contains useful information that can be exploited to skip alignment positions that cannot possibly succeed.
The prefix function \(\pi[i]\) is defined as follows: for the substring \(P[0..i]\) consisting of the first \(i+1\) characters of pattern \(P\), \(\pi[i]\) is the length of its longest proper substring that is simultaneously a prefix and a suffix.
For example, given $P[0..i] = $ ABCAB, the prefixes are A, AB, ABC, ABCA and the suffixes are B, AB, CAB, BCAB. The longest common prefix-suffix is AB, so \(\pi[4] = 2\).
Why does the prefix function avoid redundant comparisons?
When \(P[j]\) mismatches with \(T[i]\), we already know that \(P[0..j-1]\) matches \(T[i-j..i-1]\). The value \(\pi[j-1]\) tells us the length of the longest common prefix-suffix of \(P[0..j-1]\) is \(\pi[j-1]\), which means \(P[0..\pi[j-1]-1]\) is already aligned with the characters preceding the current position in \(T\). We can continue comparing from \(P[\pi[j-1]]\) directly, rather than restarting from \(P[0]\).
Algorithm for building the prefix function:
def build_prefix_function(pattern: str) -> list[int]:
"""构建 KMP 前缀函数(next数组)"""
m = len(pattern)
pi = [0] * m # pi[0] 始终为 0
length = 0 # 当前最长公共前后缀的长度
i = 1
while i < m:
if pattern[i] == pattern[length]:
length += 1
pi[i] = length
i += 1
else:
if length != 0:
# 回退:利用已有的前缀函数信息
length = pi[length - 1]
# 注意这里不递增 i
else:
pi[i] = 0
i += 1
return pi
Worked example of the construction process:
Taking the pattern $P = $ ABABAC as an example, we build the prefix table \(\pi\) step by step:
| \(i\) | \(P[0..i]\) | Longest common prefix-suffix | \(\pi[i]\) | Explanation |
|---|---|---|---|---|
| 0 | A |
(no proper substring) | 0 | Single character; \(\pi[0]\) is always 0 |
| 1 | AB |
No match | 0 | Prefix A differs from suffix B |
| 2 | ABA |
A |
1 | Prefix A = suffix A |
| 3 | ABAB |
AB |
2 | Prefix AB = suffix AB |
| 4 | ABABA |
ABA |
3 | Prefix ABA = suffix ABA |
| 5 | ABABAC |
No match | 0 | P[5]='C', fall back to pi[2]=1, compare P[1]='B' != 'C', fall back again to pi[0]=0, P[0]='A' != 'C', final result is 0 |
Final prefix table: \(\pi = [0, 0, 1, 2, 3, 0]\)
KMP search algorithm:
def kmp_search(text: str, pattern: str) -> list[int]:
"""KMP搜索:返回 pattern 在 text 中所有出现的起始位置"""
n, m = len(text), len(pattern)
if m == 0:
return []
pi = build_prefix_function(pattern)
result = []
j = 0 # pattern 中的指针
for i in range(n): # text 中的指针
while j > 0 and text[i] != pattern[j]:
j = pi[j - 1] # 利用前缀函数回退
if text[i] == pattern[j]:
j += 1
if j == m:
result.append(i - m + 1) # 找到一个匹配
j = pi[j - 1] # 继续搜索下一个匹配
return result
Complexity analysis:
- Building the prefix function: \(O(m)\)
- Search phase: \(O(n)\)
- Total time complexity: \(O(n + m)\)
- Space complexity: \(O(m)\) (for storing the prefix function array)
Boyer-Moore Family
Boyer-Moore (BM) and its variants Horspool and Sunday are the most commonly used single-pattern matching algorithms in engineering practice. Although their worst-case performance is not necessarily better than KMP, they are usually much faster than KMP on real-world text because they can skip more characters.
Boyer-Moore Core Idea
The BM algorithm compares in the opposite direction from KMP: it compares from the end (right side) of the pattern toward the beginning. When a mismatch occurs, it uses two rules to calculate how far the pattern can be shifted to the right:
1. Bad Character Rule:
When the text character \(T[i]\) mismatches with the pattern character \(P[j]\), look up the last occurrence of \(T[i]\) in the pattern at position \(k\):
- If \(T[i]\) does not appear in the pattern, the entire pattern can slide past \(T[i]\), with a shift distance of \(j + 1\)
- If \(T[i]\) appears in the pattern and \(k < j\), shift the pattern right to align \(P[k]\) with \(T[i]\), with a shift distance of \(j - k\)
- If \(k > j\), this rule yields a negative shift distance; in that case, shift by at least 1
2. Good Suffix Rule:
When a partial match \(P[j+1..m-1]\) has already succeeded but \(P[j]\) mismatches, search for another occurrence of the matched suffix within the pattern and align it. If no complete match is found, look for the longest suffix of the matched portion that equals some prefix of the pattern.
The actual shift distance is the maximum of the two rules.
Why is BM faster in practice?
For natural language text (with a large alphabet), the bad character rule can often skip many positions at once. BM's best-case complexity is \(O(n/m)\), i.e., sublinear -- it does not need to examine every character in the text.
Horspool Simplified Version
The Horspool algorithm is a simplified version of BM that uses only the bad character rule, always determining the shift distance based on the text character aligned with the rightmost position of the current window. It is simple to implement and achieves performance close to full BM in practice.
def horspool_search(text: str, pattern: str) -> list[int]:
"""Horspool算法:BM的简化版,只用坏字符规则"""
n, m = len(text), len(pattern)
if m == 0 or m > n:
return []
# 构建坏字符表:每个字符到模式串末尾的距离
# 默认移动距离为 m(字符不在模式串中)
bad_char = {}
for i in range(m - 1): # 注意:不包括最后一个字符
bad_char[pattern[i]] = m - 1 - i
result = []
i = 0 # 窗口左端在 text 中的位置
while i <= n - m:
j = m - 1 # 从模式串末尾开始比较
while j >= 0 and text[i + j] == pattern[j]:
j -= 1
if j < 0:
result.append(i) # 完全匹配
# 移动窗口
i += bad_char.get(text[i + m - 1], m)
else:
# 根据窗口最右端对应的文本字符决定移动距离
i += bad_char.get(text[i + m - 1], m)
return result
Sunday Algorithm
The Sunday algorithm goes one step further than Horspool: on a mismatch, instead of looking at the character within the current window, it looks at the first character after the current window (i.e., \(T[i + m]\)) to determine the shift distance.
- If \(T[i + m]\) does not appear in the pattern, the window jumps forward by \(m + 1\) positions
- If \(T[i + m]\) appears in the pattern, align the rightmost occurrence of that character in the pattern with \(T[i + m]\)
The Sunday algorithm is extremely simple to implement and performs exceptionally well when the alphabet is large and the pattern is long.
Complexity Comparison
| Algorithm | Best | Average | Worst | Space | Characteristics |
|---|---|---|---|---|---|
| KMP | \(O(n)\) | \(O(n)\) | \(O(n)\) | \(O(m)\) | Theoretical guarantee; never backtracks the text pointer |
| Boyer-Moore | \(O(n/m)\) | \(O(n)\) | \(O(nm)\) | \(O(m + \|\Sigma\|)\) | Fastest in practice; dual rules |
| Horspool | \(O(n/m)\) | \(O(n)\) | \(O(nm)\) | \(O(\|\Sigma\|)\) | Simplified BM; bad character rule only |
| Sunday | \(O(n/m)\) | \(O(n)\) | \(O(nm)\) | \(O(\|\Sigma\|)\) | Looks one position past the window; simplest implementation |
Here \(\|\Sigma\|\) denotes the alphabet size. In worst-case scenarios (e.g., $T = $ aaa...a, $P = $ aaa...ab), the BM family degrades to \(O(nm)\), while KMP consistently maintains \(O(n)\). However, in practical applications, the BM family is typically 3--5 times faster than KMP.
Two-Way
The Two-Way algorithm is the preferred choice for industrial-strength string searching. Many standard library implementations use this algorithm under the hood, including glibc's strstr, Python's str.find / in operator, and Rust's string search.
Core idea: combining the strengths of KMP and BM
The Two-Way algorithm was proposed by Crochemore and Perrin in 1991. Its key idea is to split the pattern into two parts (Critical Factorization), and then:
- Compare the right half from left to right (similar to KMP's direction)
- Compare the left half from right to left (similar to BM's direction)
The right half is compared first; once it matches, the left half is verified. If the right half mismatches, information similar to KMP's prefix function is used to determine the shift distance.
Why do standard libraries choose Two-Way?
| Property | KMP | BM | Two-Way |
|---|---|---|---|
| Time complexity | \(O(n + m)\) | Worst case \(O(nm)\) | \(O(n + m)\) |
| Space complexity | \(O(m)\) | \(O(m + \|\Sigma\|)\) | \(O(1)\) |
| Practical performance | Average | Very fast | Fast |
The greatest advantage of Two-Way is that it requires only \(O(1)\) extra space (no need to pre-allocate an \(O(m)\) prefix table as in KMP), while maintaining a worst-case time complexity guarantee of \(O(n + m)\). This makes it ideal for memory-sensitive system libraries -- a standard library cannot assume the pattern is short, and the \(O(m)\) space overhead may be unacceptable when the pattern is very long.
Algorithm overview (conceptual description):
- Critical factorization: Find a split point \(\ell\) in the pattern, dividing \(P\) into \(P[0..\ell-1]\) and \(P[\ell..m-1]\), such that the split satisfies the conditions of the "Critical Factorization Theorem"
- Right-half matching: Compare character by character starting from \(P[\ell]\) against the text
- Left-half verification: If the right half matches entirely, verify \(P[0..\ell-1]\) by comparing leftward
- Shift rule: On a mismatch, compute the shift distance based on the periodicity properties of the pattern, ensuring efficient jumps with \(O(1)\) space
Since the implementation details involve the Critical Factorization Theorem and period analysis of the pattern, the code is rather complex and is not presented in full here. Interested readers may refer to str-two-way.h in the glibc source code.
Multi-Pattern Matching
Consider, for example, searching for 100,000 sensitive keywords simultaneously within a single text.
Aho-Corasick
The Aho-Corasick (AC) automaton is the undisputed champion of multi-pattern matching.
Problem: Given a set of patterns \(\{P_1, P_2, \ldots, P_k\}\) and a text \(T\), find all occurrences of every pattern in \(T\) simultaneously. If we use KMP to search for each pattern individually, the time is \(O(k \cdot (n + m_i))\), which is very inefficient when the number of patterns is large. The AC automaton can find all pattern matches in a single scan of the text.
Core idea: Trie + Failure Links
The AC automaton is essentially KMP applied on a Trie. KMP's prefix function operates on a single pattern, while the AC automaton generalizes this idea to a Trie:
- The Trie organizes the prefix structure of all patterns
- Failure links are analogous to KMP's prefix function; they point from the current state to the state corresponding to the longest proper suffix that is also a prefix of some pattern
Construction process:
- Build the Trie: Insert all patterns into the Trie one by one
- Build failure links (BFS): Starting from the root of the Trie, perform BFS. For each node \(u\), the failure link of its child node \(v\) (with edge character \(c\)) points to the node reached by following \(u\)'s failure link and then taking edge \(c\). All direct children of the root have their failure links pointing to the root
- Search: A pointer traverses the AC automaton following the characters of the text. At each node, follow the failure link chain to check whether any pattern ends at the current state
Time complexity: \(O(\sum|P_i| + |T| + \text{number of matches})\), i.e., the sum of all pattern lengths (building the Trie) + the text length (searching) + the number of output matches.
Typical applications:
- Sensitive word filtering: In internet content moderation, tens of thousands of sensitive words are built into an AC automaton, and a single scan of each user input detects all sensitive words
- Virus signature matching: Antivirus software uses the AC automaton to simultaneously search for a large number of virus signatures in files
- Genomic sequence analysis: Searching for multiple known gene fragments simultaneously in DNA sequences
- Intrusion Detection Systems (IDS): Matching attack signatures in network traffic
Python implementation:
from collections import deque, defaultdict
class AhoCorasick:
def __init__(self):
# goto 函数:goto[state][char] -> next_state
self.goto = [{}]
# 失败指针
self.fail = [0]
# 输出函数:每个状态对应的模式串列表
self.output = [[]]
self.state_count = 0
def _new_state(self):
self.state_count += 1
self.goto.append({})
self.fail.append(0)
self.output.append([])
return self.state_count
def add_pattern(self, pattern: str, index: int = 0):
"""将一个模式串插入 Trie"""
state = 0
for ch in pattern:
if ch not in self.goto[state]:
self.goto[state][ch] = self._new_state()
state = self.goto[state][ch]
self.output[state].append((pattern, index))
def build(self):
"""BFS 构建失败指针"""
queue = deque()
# 根节点的直接子节点,失败指针指向根
for ch, s in self.goto[0].items():
self.fail[s] = 0
queue.append(s)
# BFS
while queue:
u = queue.popleft()
for ch, v in self.goto[u].items():
queue.append(v)
# 沿着 u 的失败指针找到能接受 ch 的状态
f = self.fail[u]
while f != 0 and ch not in self.goto[f]:
f = self.fail[f]
self.fail[v] = self.goto[f].get(ch, 0)
# 如果失败指针指向自己就修正为根
if self.fail[v] == v:
self.fail[v] = 0
# 合并输出:继承失败指针对应状态的输出
self.output[v] = self.output[v] + self.output[self.fail[v]]
def search(self, text: str) -> list[tuple[int, str]]:
"""在文本中搜索所有模式串,返回 (位置, 模式串) 列表"""
results = []
state = 0
for i, ch in enumerate(text):
# 沿失败指针寻找能接受 ch 的状态
while state != 0 and ch not in self.goto[state]:
state = self.fail[state]
state = self.goto[state].get(ch, 0)
# 收集当前状态的所有输出
for pattern, idx in self.output[state]:
pos = i - len(pattern) + 1
results.append((pos, pattern))
return results
# 使用示例
if __name__ == "__main__":
ac = AhoCorasick()
patterns = ["he", "she", "his", "hers"]
for i, p in enumerate(patterns):
ac.add_pattern(p, i)
ac.build()
text = "ahishers"
matches = ac.search(text)
for pos, pat in matches:
print(f"位置 {pos}: '{pat}'")
# 输出:
# 位置 1: 'his'
# 位置 3: 'she'
# 位置 4: 'he'
# 位置 4: 'hers'
AC automaton vs. naive multi-pattern search:
Suppose there are \(k\) patterns with total length \(M = \sum|P_i|\), and the text has length \(n\):
| Method | Time Complexity | Notes |
|---|---|---|
| Individual KMP | \(O(k \cdot n + M)\) | Requires scanning the text \(k\) times |
| AC automaton | \(O(M + n + z)\) | Scans the text only once; \(z\) is the number of matches |
When \(k\) is large (e.g., 100,000 sensitive keywords), the advantage of the AC automaton is overwhelming.