LLM & Agent System Security
Once a model can retrieve documents, call tools, execute code, and keep long-lived state, security is no longer just about whether the model says unsafe things. It becomes a system-boundary problem: can the model cross trust boundaries and make the rest of the system do unsafe things?
This page covers prompt injection as a control-flow problem, tool boundaries, secret management, side channels, multi-tenant accelerators, logging, and incident response as one canonical engineering note.
1. AI security from a systems perspective
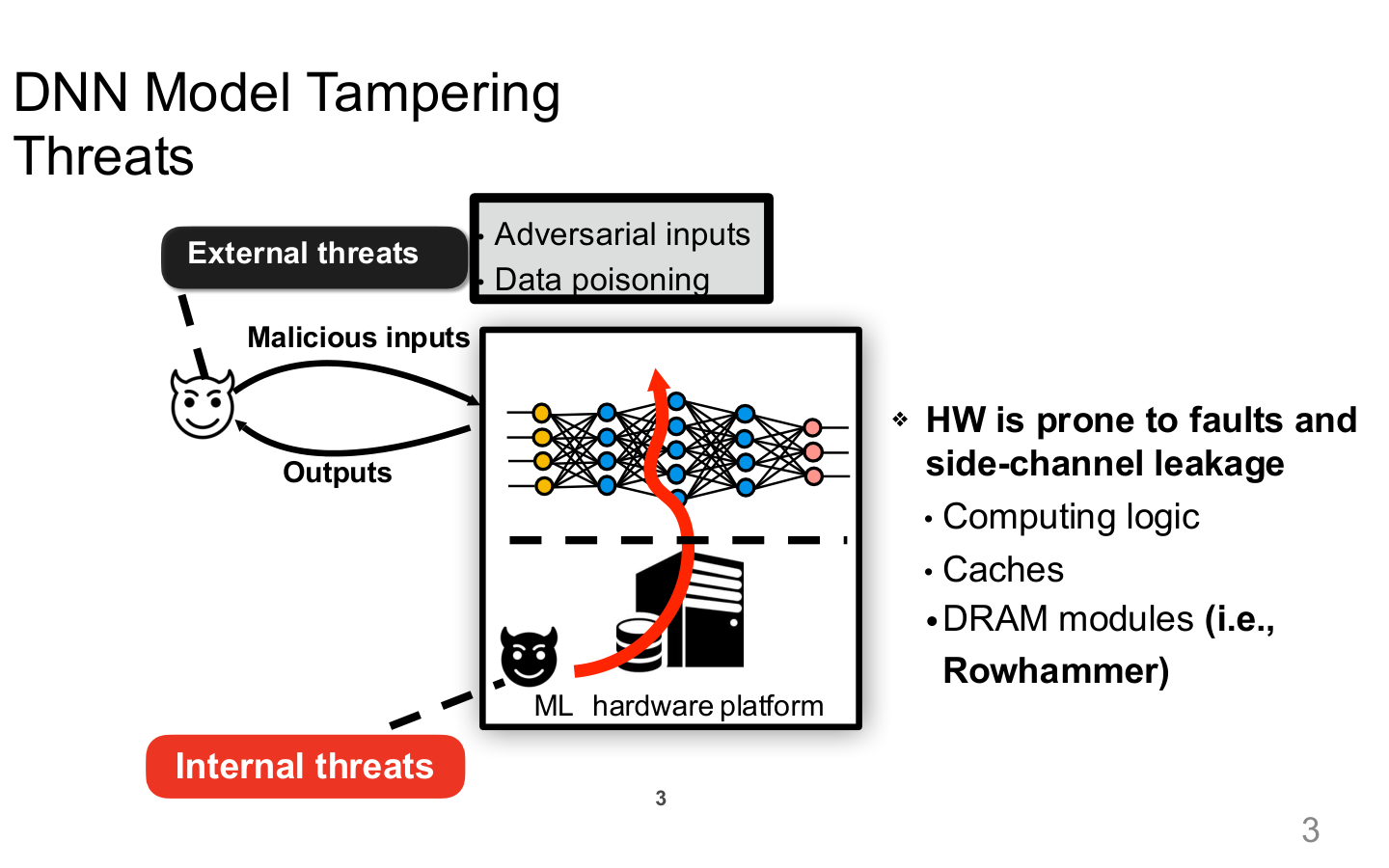
Source: Tufts EE141 Trusted AI, Lecture 7, Slide 3. Image note: the slide places malicious inputs, data poisoning, internal hardware platforms, and side-channel leakage inside one “model tampering” view. Why it matters: the trusted boundary of an AI system extends beyond the model API to training, runtime, and shared infrastructure.
1.1 Core boundaries
| Boundary | Typical objects | Failure modes |
|---|---|---|
| Prompt boundary | system prompts, user prompts, retrieved content | injection, policy override |
| Tool boundary | shell, database, browser, email | privilege escalation, unsafe execution |
| Data boundary | docs, memory, cache, logs | secret exfiltration, PII leakage |
| Runtime boundary | sandbox, container, VM, accelerator | breakout, unintended persistence |
| Org boundary | people, approvals, change flow | unclear ownership, weak auditability |
2. Prompt injection as a systems problem

Source: Tufts EE141 Trusted AI, Lecture 7, Slide 39. Image note: the slide argues that a model cannot reliably separate trusted from untrusted input and sketches a privileged / unprivileged split. Why it matters: the core issue is mixed trust domains, not just “bad prompts.”
2.1 A single model is not a trust boundary
If the same model both reads untrusted input and holds dangerous capabilities, prompt injection becomes a system-compromise path. The failure is architectural: trusted control and untrusted data share one execution context.
2.2 Split-trust patterns
More robust designs use split-trust patterns such as:
- privileged and unprivileged models
- a policy engine plus a model
- a parser / broker plus an executor
- human approval for high-risk actions
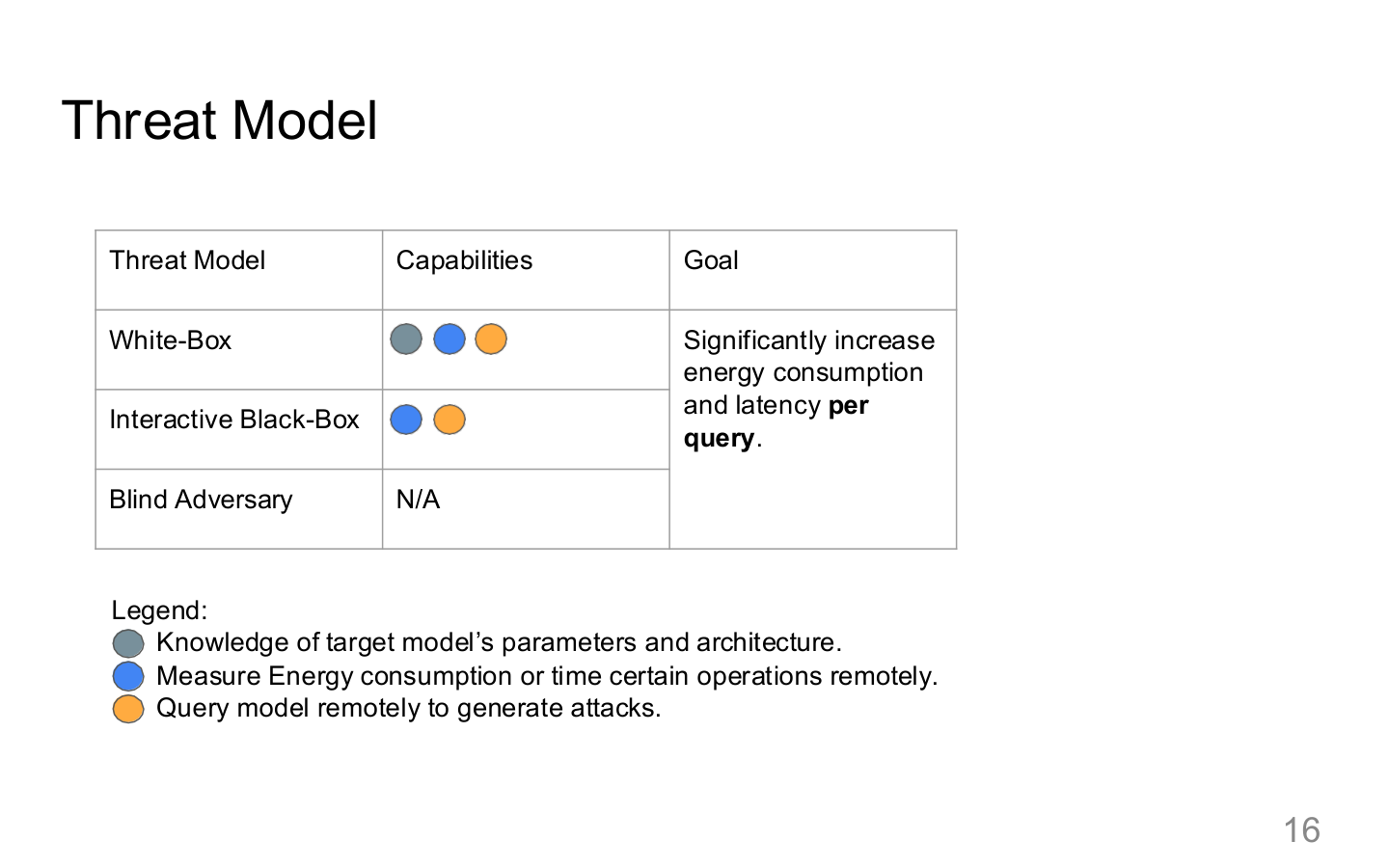
Source: Tufts EE141 Trusted AI, Lecture 7, Slide 16. Image note: the slide separates internal and external threat paths. Why it matters: the first step in agent security is not writing rules, but explicitly mapping inputs, executors, hardware, and shared resources into one threat model.
3. Tool security
3.1 Why every tool needs a broker
Tools should sit behind a broker or policy layer that enforces:
- capability allowlists
- parameter schema validation
- sensitive-field filtering
- dry-run or preview support
- approval workflows
3.2 Parameter-level restrictions
“The model can use the database” is not a real control. Real controls are:
- read-only vs write
- which tables or collections are allowed
- tenant filtering requirements
- network egress restrictions
The same applies to shell, browsers, and external APIs.
4. Secret management and exfiltration
Secrets can leak through more than config files. Common paths include:
- retrieved documents
- prompt templates
- tool output
- error traces
- logs and analytics pipelines
Good defaults include:
- never pasting secrets directly into prompts
- proxying sensitive actions through least-privilege tools
- redacting tool output before it goes back into model context
- constraining outbound domains and egress channels
5. Hardware and infrastructure risks
AI security extends beyond application logic into fault attacks and side-channel leakage.
5.1 Fault attacks
Examples include:
- bit-flip attacks
- rowhammer
- timing or voltage fault injection
These can perturb model parameters or intermediate states and produce systematic failures.

Source: Tufts EE141 Trusted AI, Lecture 7, Slide 6. Image note: the slide connects bit flips to parameter updates and model behavior. Why it matters: model parameters are not static truth; under specific hardware conditions they become attack surfaces themselves.

Source: Tufts EE141 Trusted AI, Lecture 7, Slide 12. Image note: the slide shows how disturbance between neighboring DRAM rows causes bit flips. Why it matters: low-level memory faults can propagate directly into model inference when deployments share hardware.
5.2 Side channels and multi-tenant accelerators
Shared hardware can leak information through:
- cache behavior
- memory timing
- accelerator contention
- debugging and profiling interfaces
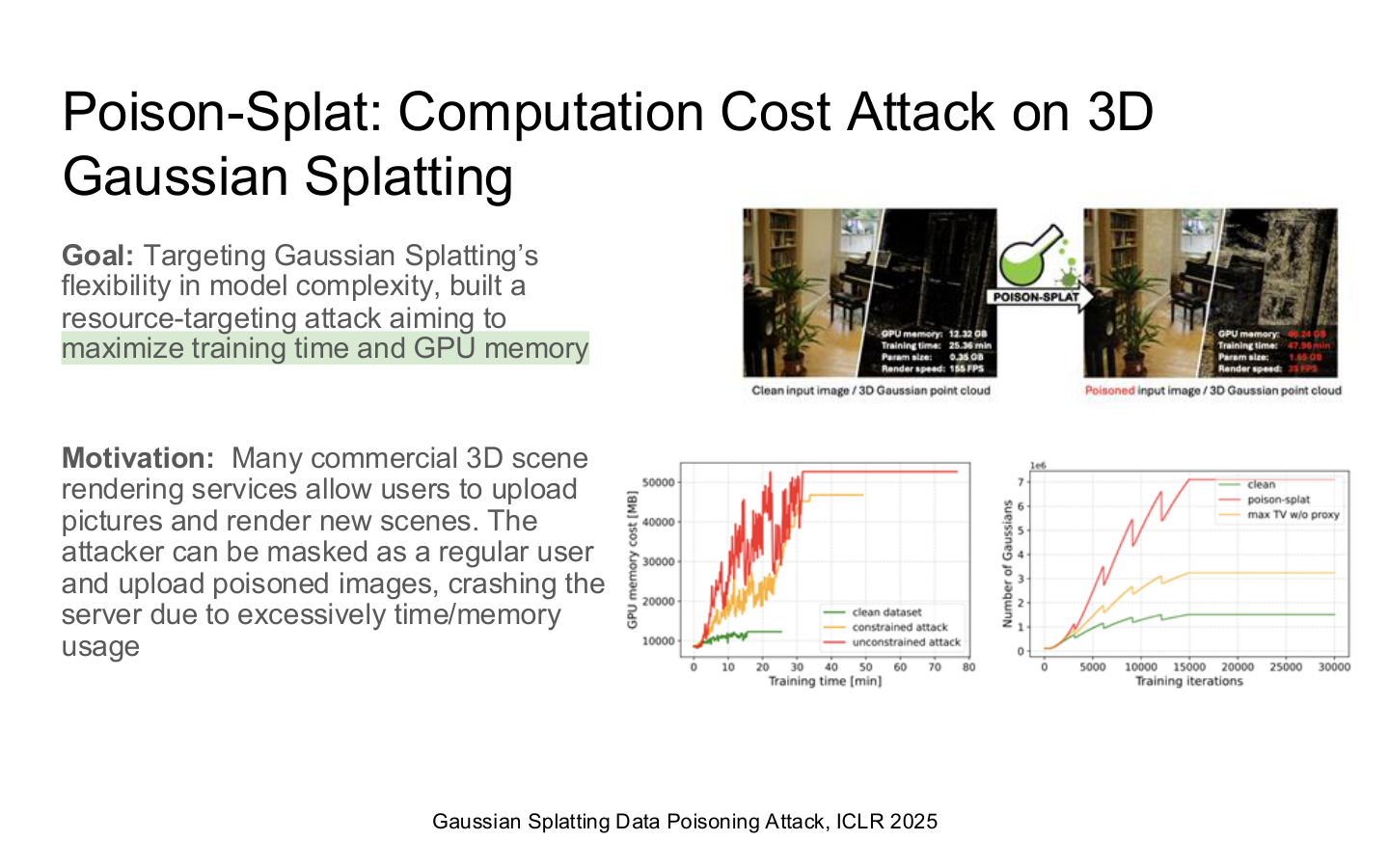
Source: Tufts EE141 Trusted AI, Lecture 7, Slide 23. Image note: the slide frames 3D Gaussian Splatting poisoning as a resource-exhaustion problem. Why it matters: system security is not only about confidentiality and integrity; attackers also target availability and GPU budget.

Source: Tufts EE141 Trusted AI, Lecture 7, Slide 25. Image note: the slide uses a red/blue teapot example to show how timing or power differences can reveal hidden state. Why it matters: side channels work by recovering information from secondary signals rather than by reading plaintext directly.

Source: Tufts EE141 Trusted AI, Lecture 7, Slide 29. Image note: the slide lists model extraction, architecture recovery, and input recovery as side-channel goals. Why it matters: attackers may recover high-value information even without touching the primary model API.
In multi-tenant FPGA/GPU/TPU environments, isolation mistakes can expose inputs, model structure, or artifacts even without direct model access.
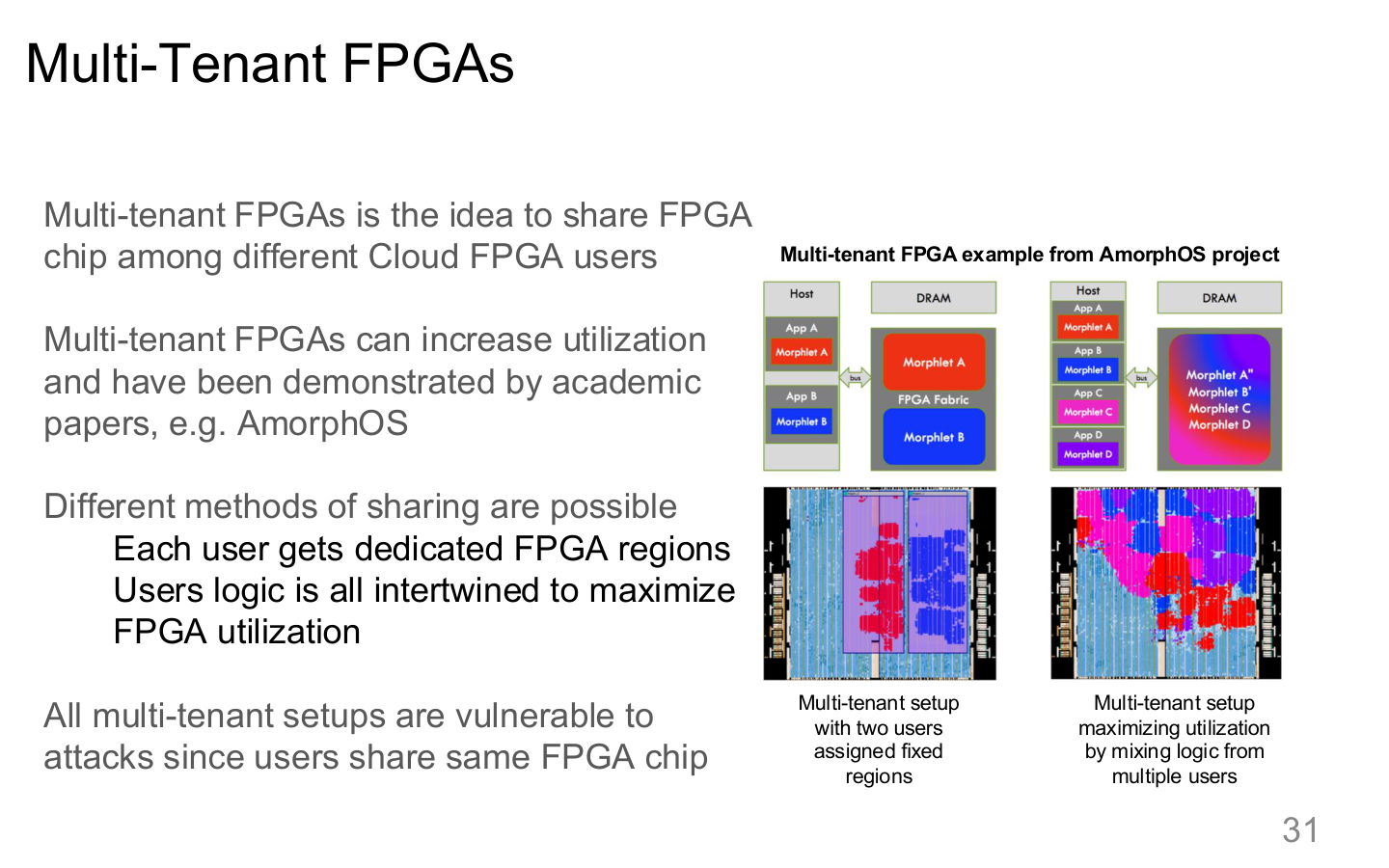
Source: Tufts EE141 Trusted AI, Lecture 7, Slide 31. Image note: the slide visualizes resource sharing across FPGA tenants. Why it matters: when resource boundaries are unclear, inference, monitoring, and debugging behavior can leak across tenants.

Source: Tufts EE141 Trusted AI, Lecture 7, Slide 32. Image note: the slide discusses information leakage from custom ML accelerators. Why it matters: dedicated hardware brings performance, but it also introduces attack surfaces not covered by generic cloud-security guidance.
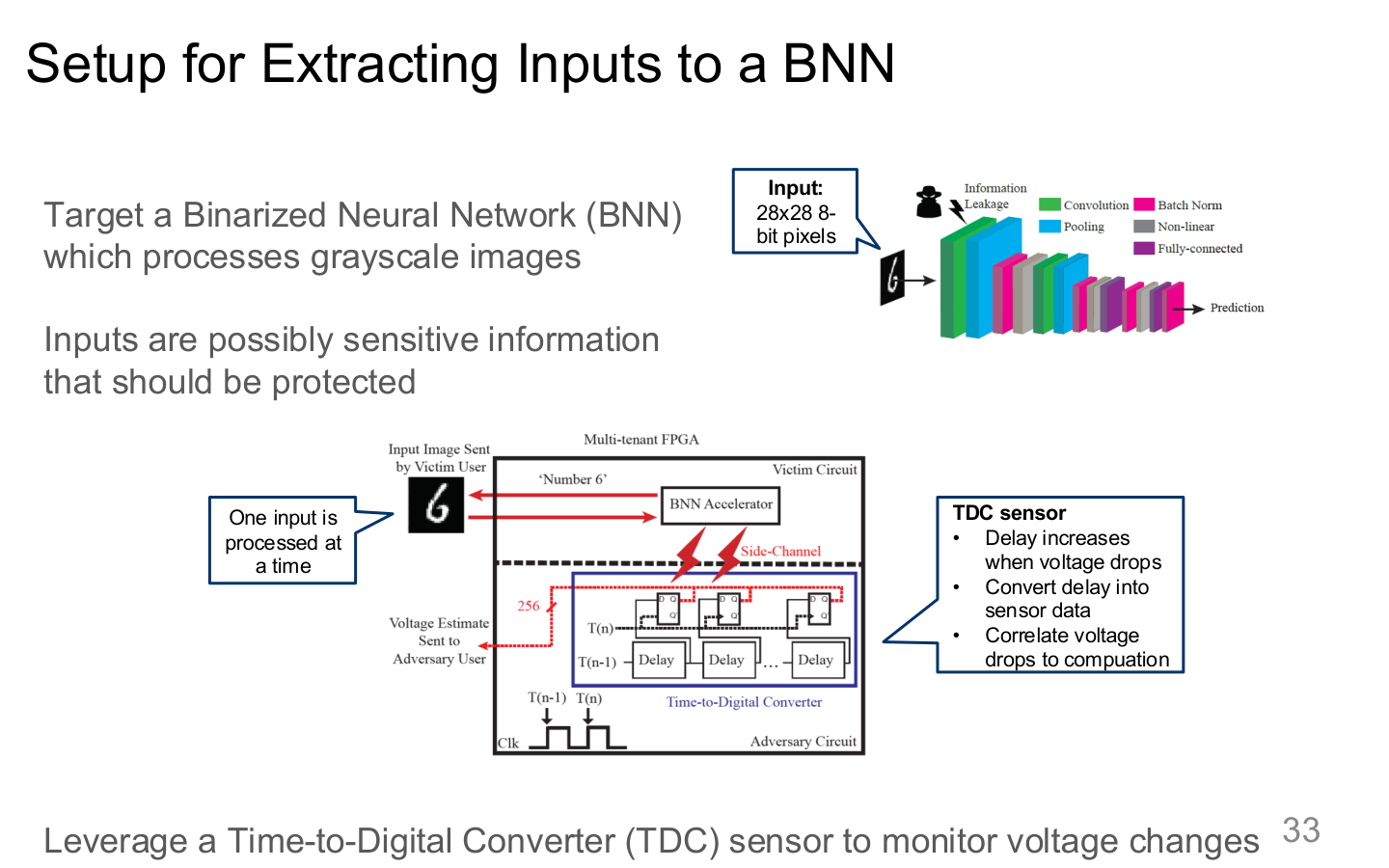
Source: Tufts EE141 Trusted AI, Lecture 7, Slide 33. Image note: the slide sketches an experimental setup for recovering inputs from accelerator side signals. Why it matters: input confidentiality depends not just on network controls, but also on what the runtime leaks while computing.
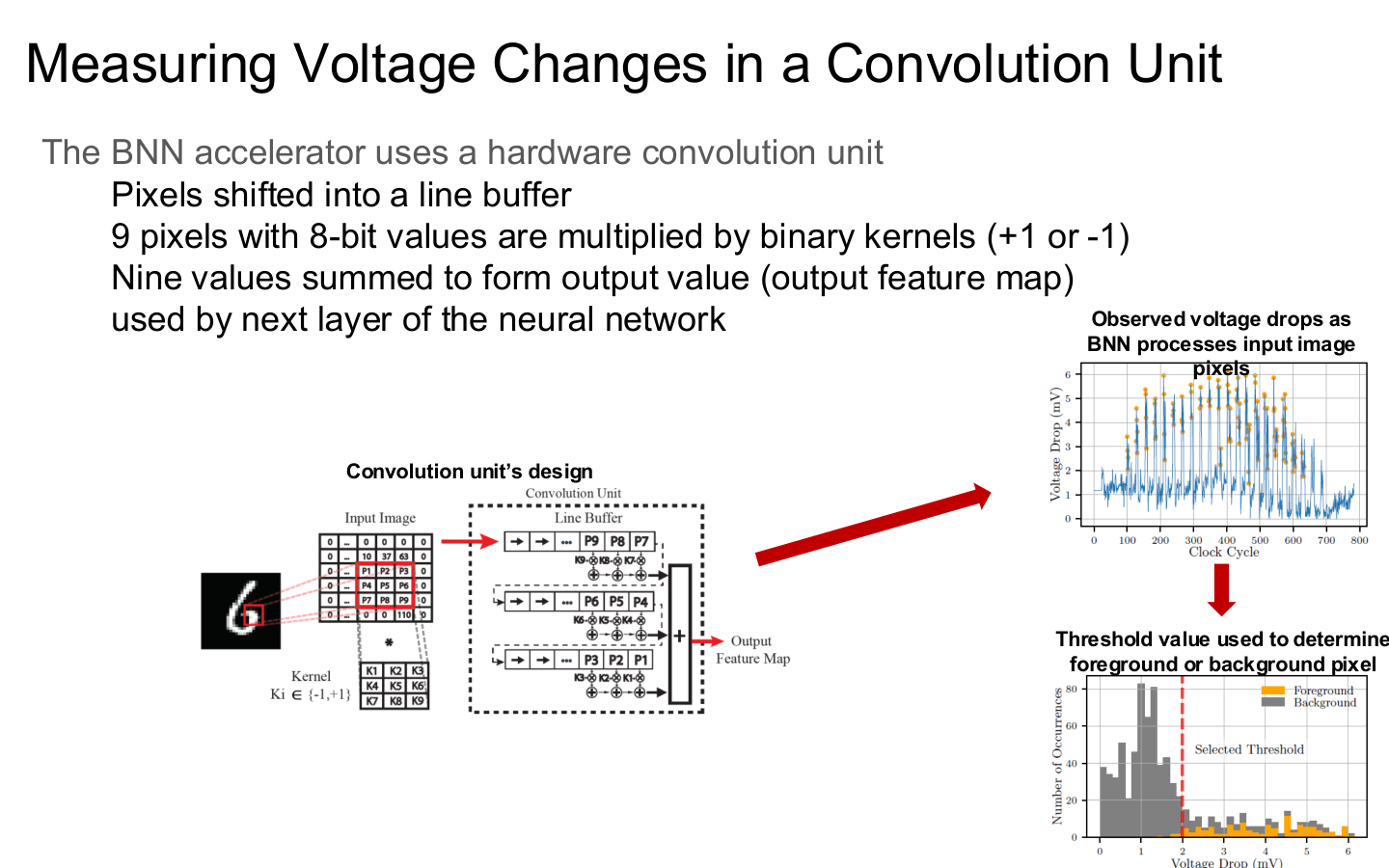
Source: Tufts EE141 Trusted AI, Lecture 7, Slide 34. Image note: the figure measures voltage changes in accelerator computation. Why it matters: many attacks need no software logs at all; stable physical observation windows can be enough.

Source: Tufts EE141 Trusted AI, Lecture 7, Slide 35. Image note: the slide compares original and reconstructed input images. Why it matters: once side signals are sufficient to reconstruct inputs, model serving can leak user and business data at the same time.
6. Runtime isolation and audit
6.1 Sandbox requirements
For high-risk tool use, a sandbox should define:
- visible filesystem scope
- network scope
- CPU / memory / token budgets
- timeout behavior
- cleanup of side effects
6.2 Minimum audit trail
| Layer | Minimum evidence |
|---|---|
| Input chain | user input, retrieved sources, memory hits |
| Inference chain | prompt template, model version, policy route |
| Tool chain | tool name, parameter summary, result summary, approver |
| Output chain | whether guards intervened, what was redacted |
| Security events | rule triggered, severity, response outcome |
6.3 Incident response
When prompt injection, secret leakage, or tool misuse happens, the baseline response is:
- suspend the affected capability or tenant
- rotate tokens and revoke compromised sessions
- inspect logs to determine blast radius
- patch the policy, schema, or isolation gap
- add the scenario to regression red-team suites
Relations to other topics
- For the overall framing, see AI Safety Overview
- For jailbreak and prompt-level attacks, see LLM Jailbreaking
- For privacy and data leakage, see Privacy Attacks
- For governance and compliance, see AI Engineering Safety & Governance
References
- Tufts EE141 Trusted AI Course Slides, System Security Lecture, Spring 2026.
- Simon Willison, "Prompt Injection Explained", 2023.
- OWASP, "Top 10 for Large Language Model Applications", 2025.