Introduction to Classical RL
Reinforcement Learning
The Sutton/Barto Classic Textbook
The following summarizes key points from the preface of the first edition, which recounts the origins of reinforcement learning research:
- In late 1979, the two authors were working at UMass on an early project that sought to revive the idea that networks composed of neuron-like adaptive units could provide a promising pathway toward artificial adaptive intelligence. The project examined and critically discussed Klopf's Heterostatic Theory of Adaptive Systems.
- Over the following twenty years, Sutton never stopped investigating this idea. The core concept had long been taken for granted, yet had never received serious computational attention: a learning system that wants something adjusts its own behavior to maximize a particular signal received from the environment. This is the so-called Hedonistic learning system — what we now call a reinforcement learning system.
- Initially, Sutton and Barto assumed that reinforcement learning had already been thoroughly explored. Upon deeper investigation, they discovered it had hardly been studied at all. Most researchers had only briefly examined reinforcement learning before moving on to other directions such as Pattern Classification, Supervised Learning, and Adaptive Control — or they abandoned the study of learning problems altogether. As a result, when the two authors first began their research, they found that the problem of learning how to obtain beneficial outcomes from the environment had received woefully inadequate attention, leaving the field of reinforcement learning largely unexplored with no real progress from a computational standpoint.
- The authors noted that, although the question of "how to achieve goals through interactive learning" was far from fully resolved by the time of the first edition, their understanding had deepened considerably. Temporal-difference learning, dynamic programming, function approximation, and other ideas could now be integrated into a coherent, unified perspective.
- The purpose of writing this book was to provide a clear and concise textbook that systematically introduces the key ideas and algorithms of reinforcement learning. The book adopts the perspective of artificial intelligence and engineering.
- The first edition also mentioned that the book does not provide a rigorous formal treatment of reinforcement learning, as the authors do not pursue the highest level of mathematical abstraction nor use a strict theorem-proof format. They maintain a balance between conciseness and theoretical generality, avoiding distraction for the general reader while helping mathematically inclined readers pursue deeper understanding.
- In the 1998 first edition, the authors noted that they had already been working on the book for thirty years. (Reader's note: This spirit of scientific exploration is truly inspiring.)
- Reader's note: In the acknowledgments of the 1998 first edition, there is a Chinese person named Wei Zhang; I was unable to find out who this person is. Today, as we study reinforcement learning — now renowned worldwide — it is hard to imagine that thirty to fifty years ago, many pioneers had already conducted extensive explorations. I sometimes marvel at the fact that a world-class AI research institute is situated in a place as remote and quiet as Alberta. The starting points of these great scientific achievements were remarkably "modest" — as of 1998, Sutton's papers had only been cited about a thousand times, yet he and his collaborators had already devoted thirty years of deep thought and research. I recently watched several interview videos of Sutton, and he continues to think deeply about the future of artificial intelligence and reinforcement learning. Compared to those who rest on their laurels, he is more like a philosopher: perpetually pondering the fundamental question of "what intelligence really is."
The reader summarized the key points from the second edition preface as follows:
- The first edition was published in 1998. In the twenty years since its publication, artificial intelligence has made tremendous progress, driven by more powerful computing and new theories and algorithms.
- The book does not provide a strict formal definition of reinforcement learning, nor does it generalize it to the most general form. The entire book remains introductory in nature, with a focus on Online Learning Algorithms.
- The second edition requires a higher level of mathematical exposition compared to the first edition. Mathematical content placed in gray boxes is skippable for readers without a mathematical background.
- The second edition has optimized its notation for easier learning and comprehension. Random Variables are denoted by capital letters — for example, St, At, Rt represent the state, action, and reward at time step t — while their specific values are denoted by lowercase letters, such as s, a, r.
- Value functions are denoted by lowercase letters, e.g., v pi; tabular estimates use capital letters, e.g., Qt(s, a). Approximate value functions are deterministic functions, so their parameters also use lowercase letters; bold uppercase letters are used for matrices.
- The second edition reduces excessive use of superscripts and subscripts, adopting more convenient notation such as p(s', r | s, a).
- The book's content is recommended to be studied over two semesters; if only one semester is available, covering the first ten chapters is recommended. (Reader's note: No wonder my RL course essentially covered up to about chapter ten before moving into the final project — so that's where it came from.)
- Sutton (in this series of notes, "Sutton" refers to both Sutton and Barto; this will not be repeated hereafter) expressed gratitude to scientist A. Harry Klopf and dedicated the second edition to him. Professor Klopf proposed a vision for the brain and artificial intelligence that brought the two authors together. Through Klopf's introduction, Sutton — then still an undergraduate at Stanford — joined the research group of the newly established UMass Amherst project. Klopf was instrumental in securing funding for the project.
- Sutton expressed gratitude to the Reinforcement Learning and Artificial Intelligence laboratory at the University of Alberta.
- Klopf was an important early figure in the field of machine intelligence who proposed theories that had a significant impact on artificial intelligence. He believed that maximizing some internal objective — whether concrete or abstract — is the core of intelligent systems, rather than merely maintaining system stability. In other words, the goal of an intelligent agent is not just to maintain equilibrium but to actively explore the environment, predict the future based on experience, and select actions to maximize long-term returns or internal rewards. This philosophical viewpoint directly inspired later reinforcement learning theory: an agent not only responds to environmental changes but also optimizes long-term objectives through active behavioral choices; an agent does not imitate fixed rules or maintain states but rather learns to maximize cumulative reward through trial and error. Sutton and Barto explicitly stated that this idea was the intellectual starting point of their reinforcement learning research journey.
The Bitter Lesson
In addition to the preface above, I would also like to share an article Sutton wrote in 2019 called "The Bitter Lesson." The article is not long, but it summarizes some of his important reflections and views on seventy years of artificial intelligence development. I have compiled some of the most important points:
- The biggest lesson from seventy years of AI research is this: general-purpose methods that leverage computation are ultimately the most effective — and by a wide margin. The fundamental reason is Moore's Law, or more broadly, the long-term exponential decline in the cost per unit of computation. However, most AI research has been conducted under the implicit assumption that the computational resources available to an agent are constant. Under this assumption, incorporating human knowledge seems like the only way to improve performance. But in reality, computational capabilities far exceeding current resources will emerge given only a modest extension of time. Therefore, although researchers tend to use their domain expertise for short-term breakthroughs, in the long run, only one thing truly matters: whether computation can be effectively leveraged as it continues to grow.
- Relying on human knowledge and relying on computational scaling are not necessarily opposed in theory, but in practice they often are. On the one hand, researchers can only invest their time in one or the other; on the other hand, people develop psychological attachment to a particular approach. Moreover, the human-knowledge path often leads to increasingly complex algorithms that become unsuitable for combination with large-scale general-purpose computational methods.
- In 1997, the system that defeated world champion Kasparov was based on massive deep search. The mainstream computer chess research community was generally dismayed, as they had long worked to build systems based on human understanding of chess positions, yet what ultimately prevailed was a relatively "simple" search-based system relying on specialized hardware and software optimization. Many researchers hoped that methods incorporating human wisdom would win, but when reality proved otherwise, they were disappointed by the overwhelming victory of brute-force search.
- A similar story unfolded in Go. Initially, researchers invested enormous effort in avoiding search, instead leveraging human knowledge or special properties of the game itself, but these efforts were ultimately proven irrelevant or even counterproductive. Search and learning can be considered the two most important computational scaling techniques in modern AI. Just as in chess, Go research initially tried to leverage human understanding to reduce the need for search, but it was not until the end that researchers realized true success comes from embracing and thoroughly exploiting search and learning.
- In the 1970s, the U.S. Department of Defense organized a speech recognition competition, and the winner used more statistical and computational models, defeating methods that relied heavily on human knowledge. The victory of statistical methods triggered a long-term shift in the entire field of natural language processing; over the following decades, statistical and computational approaches gradually became dominant. In recent years, deep learning has further advanced speech recognition, relying even more on computation and almost entirely independent of human knowledge.
- Researchers often try to make systems think the way they themselves think, hard-coding their own knowledge into systems — an approach that has almost always been proven harmful in the end. Because as computational power grows exponentially, systems that depend on human input become inefficient and obsolete, ultimately wasting vast amounts of researcher time.
- In computer vision, modern deep neural networks have replaced hand-designed abstract representations. The basic structures of convolutions and invariance far outperform earlier models.
- We are still repeating similar mistakes today. To recognize and resist these mistakes, we must first understand their allure: building into systems what we think we know about "how we think" seems natural, yet it is a shortcut that fails in the long run. (Reader's note: In a recent interview, someone asked Sutton about his views on RLHF. He expressed skepticism. He did not elaborate on his specific reasons, but one can refer to this passage for context.)
- The bitter lesson derives from historical observation and can be summarized as follows: AI researchers constantly try to hard-code knowledge into their systems. This works in the short term and gives researchers psychological satisfaction. But in the long run, such approaches hit bottlenecks and even impede progress. Truly breakthrough advances ultimately always come from the opposite direction: relying on search and learning, scaling up computation, rather than increasing knowledge injection.
- This success is "bitter" because it defeats the humanistic path into which people have poured their passion and conviction.
- The first thing we should learn: general-purpose methods with universality (those that scale with computational power) are the fundamental source of strength.
- Another lesson: stop fantasizing about "simply understanding the brain." The contents of the mind are inherently and irreducibly complex. We should stop trying to find simple ways to describe the contents of the mind — what space is, what objects are, how symmetry works — these are all part of the arbitrarily complex external world itself. We should not try to presuppose these complexities as merely built-in; instead, we should build meta-methods that can discover these complexities on their own. The key to these methods is that they can find good approximations, but the process of finding those approximations should be carried out by the system itself, not pre-constructed by humans.
- What we want is: agents that can discover as we do, not systems that contain what we have already "discovered." Because hard-coding our discoveries into systems actually hinders our understanding of how the process of "discovery" itself is possible.
Reader's note: The preface left me profoundly moved — one could say the authors distilled decades of research and reflection into these pages. I originally just wanted to take advantage of the ample time this summer to carefully read through this classic textbook, but I did not expect to be so deeply struck right from the start. Recently, I have been developing an AI Agent that incorporates a great deal of financial knowledge, and after reading this, I realized that approach is not viable. In fact, I had already noticed many inelegant aspects during early development, so for the final project in my machine learning course, I created a pure LLM layer on top, with my own tools or tool systems like LangChain and OpenManus placed in the layer below. In the reflection section of my project report, I proposed my view on AI Agents: I believe that AI Agents ultimately will not need any human-constructed tool chains or PROMPTS — all tasks can be completed directly through the LLM's own understanding of the task. I call this the "Tool-Free AI Agent." If an LLM possesses sufficient contextual understanding, programming ability, and memory capacity, then complex tool chains are unnecessary — the LLM can simply write code and dynamically invoke APIs to accomplish tasks. After reading Sutton's "The Bitter Lesson" while organizing these notes today, I am now confident that my earlier thinking was correct. The future of AI Agents will surely follow the same pattern as all previous bitter lessons — RLHF, PROMPT ENGINEERING, and the like will eventually be swept into the dustbin of history. I feel fortunate to have returned to school to study computer science. Every day of learning now is a process of pure enjoyment and contemplation — not for job hunting, not for exams, not for graduate school admissions. Perhaps this is the ultimate joy that comes from growing up in China's exam-oriented education system, working for several years, and then returning to school to pursue the purity of learning itself.
What Is Reinforcement Learning?
When we think about "the nature of learning," the first thing that comes to mind is learning through interaction with the environment — for example, a baby playing, waving its arms. This sensorimotor connection produces a wealth of information about cause and effect, consequences of actions, and what actions should be taken to achieve goals.
This kind of interaction persists throughout our lives and is an important source of our understanding of the environment and self-awareness. This book explores a computational approach to learning from interaction — an idealized learning scenario. The book does not explore how humans and animals learn, but instead takes the perspective of artificial intelligence and engineering. We design machines that effectively solve learning problems in scientific or economic contexts, and evaluate these designs through mathematical analysis or computational experiments. The approach we explore is called reinforcement learning. Compared to other machine learning methods, it is more focused on goal-directed learning through interaction.
(Reader's note: In "The Bitter Lesson," Sutton once again emphasized this point — that computer scientists need not be overly concerned with human experience, and that starting from computation itself can lead to intelligence; moreover, over-reliance on human experience is harmful.)
Note that this chapter will explore the nature of reinforcement learning from multiple perspectives, and the authors have already mentioned in the preface that this book will not give a general formal definition of reinforcement learning.
(1) Reinforcement learning is about learning "what to do"
Reinforcement Learning is about learning "what to do" — that is, mapping situations to actions so as to maximize a numerical Reward Signal. The key point is that the learner must discover which actions yield the most reward through trial, rather than being explicitly told which actions to take. In some situations, an action may affect not only the immediate reward but also the next situation, thereby influencing all subsequent rewards. These two features — trial-and-error search and delayed reward — are the two most important distinguishing characteristics of reinforcement learning.
Like many topics ending in "-ing," Reinforcement Learning is simultaneously a problem, a class of solution methods, and an academic field that studies these problems and methods. However, we need to distinguish the use of this term between "the problem itself" and "the solution methods."
We formalize the reinforcement learning problem using ideas from Dynamical Systems Theory — specifically, the problem of Optimal Control of an incompletely known Markov Decision Process (MDP). This is elaborated in detail in Chapter 3. The basic idea is: to have an agent interact with its environment over time to achieve a goal, the agent must be able to sense the state of the environment to some degree and take actions that affect the state. Mathematically, the agent must have a goal or objective function related to the environmental state.
MDPs are designed to capture, in the simplest possible form, three aspects:
- Sensation
- Action
- Goal
Any method suitable for solving this class of problems can be considered an RL method.
(2) Reinforcement learning is the third machine learning paradigm
RL differs from Supervised Learning, which is currently the most widely used machine learning method. Supervised learning proceeds from a set of labeled training examples provided by a knowledgeable external supervisor. Each example represents a situation along with its corresponding label, which can also be understood as a situation and its corresponding action. The goal of supervised learning is to Extrapolate or Generalize its responses so that it can make correct decisions even in situations not present in the training set.
However, supervised learning cannot satisfy the need for learning from interaction, because it is very difficult to obtain training examples of desired behavior that are both correct and representative of all the situations in which the agent must act.
Reinforcement learning also differs from Unsupervised Learning, which typically refers to the process of finding hidden structure in unlabeled datasets. Although it might seem that supervised and unsupervised learning together cover all of "machine learning," this is actually not the case. Some view reinforcement learning as a type of unsupervised learning because it does not rely on examples, but this view is rather one-sided. The goal of reinforcement learning is to maximize a reward signal, not to find hidden structure. While discovering structure in the agent's experience may be helpful for RL, this alone cannot solve the core problem of maximizing the reward signal.
Therefore, we consider reinforcement learning to be distinct from the above two machine learning paradigms, and regard reinforcement learning as representing a third machine learning Paradigm.
(3) Reinforcement learning faces the trade-off between exploration and exploitation
There is a challenge in reinforcement learning that does not arise in other types of learning: the Trade-off between Exploration and Exploitation.
To obtain more reward, a Reinforcement Learning Agent must prefer actions that it has tried in the past and found to be effective. But exploitation alone cannot get the job done — the agent must also explore and gradually favor actions that appear to work better. In a Stochastic Task, each action must be tried many times to obtain a reliable estimate of its expected reward.
The Exploration-Exploitation Dilemma has long been an intensively studied topic among mathematicians and remains unsolved. It is emphasized here because, in the purest forms of supervised and unsupervised learning, this trade-off problem simply does not exist.
(4) Reinforcement learning explicitly addresses the complete problem
Another notable difference between reinforcement learning and other approaches is that reinforcement learning explicitly considers the whole problem of a goal-directed agent interacting with an uncertain environment, rather than merely studying a subproblem.
For example, supervised learning does not address how its capabilities ultimately help achieve a goal; some research develops Planning theory but does not explore the role of decision-making in implementation or where predictive models come from. These studies are isolated within subproblems, and this limitation is evident.
Reinforcement learning starts from a complete, interactive, goal-seeking agent. All agents have explicit goals, can sense their environment, and can choose actions to influence the environment.
When planning is involved, it must address the relationship between planning and real-time action selection, as well as how the environment model is acquired and improved.
An agent is not necessarily a complete robot. It can be a component of a larger system — for instance, an agent responsible for monitoring a robot's battery level, in which case its environment consists of the robot and the robot's environment.
(5) A Return to Simple General Principles
Reinforcement learning is part of a trend in artificial intelligence toward a return to Simple General Principles. Since the late 1960s, many AI researchers have believed that there are no unified principles underlying intelligence, but rather that it consists of a large collection of specialized tricks and Heuristics. It was once believed that amassing enough factual information — millions or billions of data points — would be sufficient to create intelligence. At that time, methods based on general principles (such as search or learning) were called weak methods, while methods based on specific knowledge were called strong methods. This view is no longer common today. In the authors' opinion, too little effort was invested in studying general principles, and their existence was prematurely dismissed. Modern AI has renewed its focus on general principles, especially in learning, search, and decision-making. Although it is unclear how far this pendulum can swing back, reinforcement learning research has clearly become an important force driving AI back toward simpler and more general principles.
Illustrative Examples
To facilitate understanding, the authors present several iconic reinforcement learning examples and application scenarios as introductory illustrations.
- A chess grandmaster makes a move. This decision is influenced both by planning and by immediate intuitive judgments about specific positions and moves.
- An adaptive controller adjusts parameters in real time during refinery operations, balancing yield, cost, and quality based on specified marginal costs, rather than strictly following the engineer's original targets.
- A newborn gazelle struggles to stand up, yet within half an hour it can run at 20 miles per hour.
- A mobile robot must decide whether to enter a new room to search for more trash or attempt to return to its battery charging station. It makes this decision based on its current battery level and its past experience with how easy or difficult it was to find the charger.
- A person is preparing breakfast. This seems ordinary, but upon close examination, the process involves a network of conditional behaviors and goal-subgoal relationships: walking to the cabinet, opening the door, selecting the cereal box, reaching up to grab it... For each action sequence needed to obtain a bowl, spoon, and milk, visual input, body coordination, and motor planning are required. Throughout this process, the person must continually make quick judgments — for instance, whether to carry multiple items to the table at once or in batches. Each step is guided by a goal, such as grabbing a spoon or opening the refrigerator, and these goals serve a larger goal: preparing breakfast and obtaining nutrition. While acting, the person also adjusts based on state information — for example, whether they are already full, still hungry, or have taste preferences.
All these examples share a common feature: they all involve an actively decision-making agent interacting with its environment, attempting to achieve a goal under uncertainty about the environment. The agent's actions can affect future states of the environment — for example, the next board position, the oil level in the refinery, or the robot's next charging state — and thereby influence future available actions and their outcomes. Making correct decisions requires considering the indirect and delayed consequences of actions, sometimes even requiring foresight or planning.
At the same time, the effects of actions cannot be fully predicted, so the agent must frequently sense the environment and respond appropriately. For example, the person eating breakfast needs to watch whether they are pouring too much milk to prevent overflow. In these examples, the goal is explicit: the agent can directly assess its progress toward the goal through perception — the chess player knows whether they have won, the refinery controller knows the yield, the gazelle knows whether it has fallen, the robot knows whether its battery is low, and the person eating breakfast knows whether they enjoy their meal.
In all these examples, the agent can use its experience to gradually improve its performance. When the agent first encounters a task, its knowledge may come from prior experience with related tasks, may be pre-built through design, or may have been shaped through evolution. These factors determine what is easy or valuable to learn, but what truly enables the agent to adapt to the specific demands of a task is its interaction with the environment — this is essential for adjusting behavior to exploit key task characteristics.
Components of Reinforcement Learning
This section introduces the general components of reinforcement learning. In the preceding discussion, we have already repeatedly mentioned the following two elements:
- Agent
- Environment
In addition, we can decompose a reinforcement learning system into four main sub-elements:
- Policy
- Reward signal
- Value function
- Model of the environment
Reader's note: The specific roles and functions of these elements are addressed repeatedly throughout the book, so I will not elaborate here. Over-emphasizing their definitions at this stage would only constrain our thinking. I believe it is better to summarize or generalize these concepts after completing the entire book, rather than fixing their definitions before we begin studying. For now, just remember that these elements exist — treat them as puzzle pieces to be assembled later.
Scope and Limitations of Reinforcement Learning
Reinforcement learning is highly dependent on the concept of state: state serves as both the input to the policy and value function and the input and output of the model. The authors emphasize that this book will rarely discuss how to construct, modify, or learn state signals, because the book primarily focuses on the decision-making problem itself — that is, the book is not concerned with how to design state signals, but rather with what actions the agent should take given existing state signals.
Most reinforcement learning methods discussed in this book center on estimating the value function. However, estimating value functions is not strictly necessary for solving reinforcement learning problems. Genetic algorithms, genetic programming, simulated annealing, and other optimization methods never estimate value functions. These methods typically employ multiple static policies, each interacting independently with the environment over multiple episodes. The policies that accumulate the most reward are then selected and mutated to generate the next generation of policies, and this process is repeated. These methods are generally called evolutionary methods because their operation resembles biological evolution: adaptation to the environment occurs primarily through generational changes.
Evolutionary methods can be highly effective when the policy space is small and it is easy to find high-quality policies. They also have certain advantages for tasks where the agent cannot perceive the complete state of the environment. However, this book focuses on learning while interacting with the environment — a characteristic that evolutionary methods lack. Evolutionary methods ignore the details of individual interactions with the environment and do not concern themselves with which states an individual experienced or which actions it chose during its lifetime.
There are many aspects of evolutionary methods that resemble reinforcement learning methods, but this book does not explore them.
Tic-Tac-Toe
This section introduces a highly simplified version of a reinforcement learning strategy: solving Tic-Tac-Toe through value function updates.
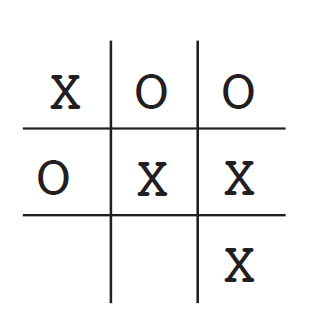
In this game, we all know (and if we don't, it is easy to figure out) the optimal strategy: the first player can never lose. In game theory, the minimax solution assumes the opponent always plays optimally. Under minimax, a player would never enter a state that could lead to defeat. To make this problem more realistic, we assume here that the opponent is an imperfect player (one whose strategy sometimes errs, giving us opportunities to win).
Now, let us introduce the reinforcement learning approach. We use a value function method to solve this problem. First, we build a numerical table where each entry corresponds to a game state, and the value represents our latest estimate of the probability of winning from that state. This estimate is called the value of the state. The entire table constitutes the learned value function. If state A has a higher value than state B, then state A is "better" than state B.
For example:
- If we are player X, then a state with three X's in a row has a value of 1 (we have already won).
- If the board is full with no three-in-a-row X, or if three O's are in a row, the value is 0 (we cannot win).
- All other states are initialized to 0.5, indicating an initial guess of a 50% win probability.
We then play many games against the opponent. Before each move, we examine the values of the states that each legal move would lead to and select the move with the highest value — that is, the move with the highest expected win probability. Most of the time we follow this greedy strategy, selecting the move with the maximum value. But occasionally, we randomly select a move instead — this is called an exploratory move, whose purpose is to expose us to states we would not otherwise encounter (to discover potentially higher-valued moves).
During the game, we need to continually update state values to bring them closer to the true win probabilities. The specific procedure is: whenever a greedy move is executed, we shift the current state's value toward the next state's value, as illustrated below:
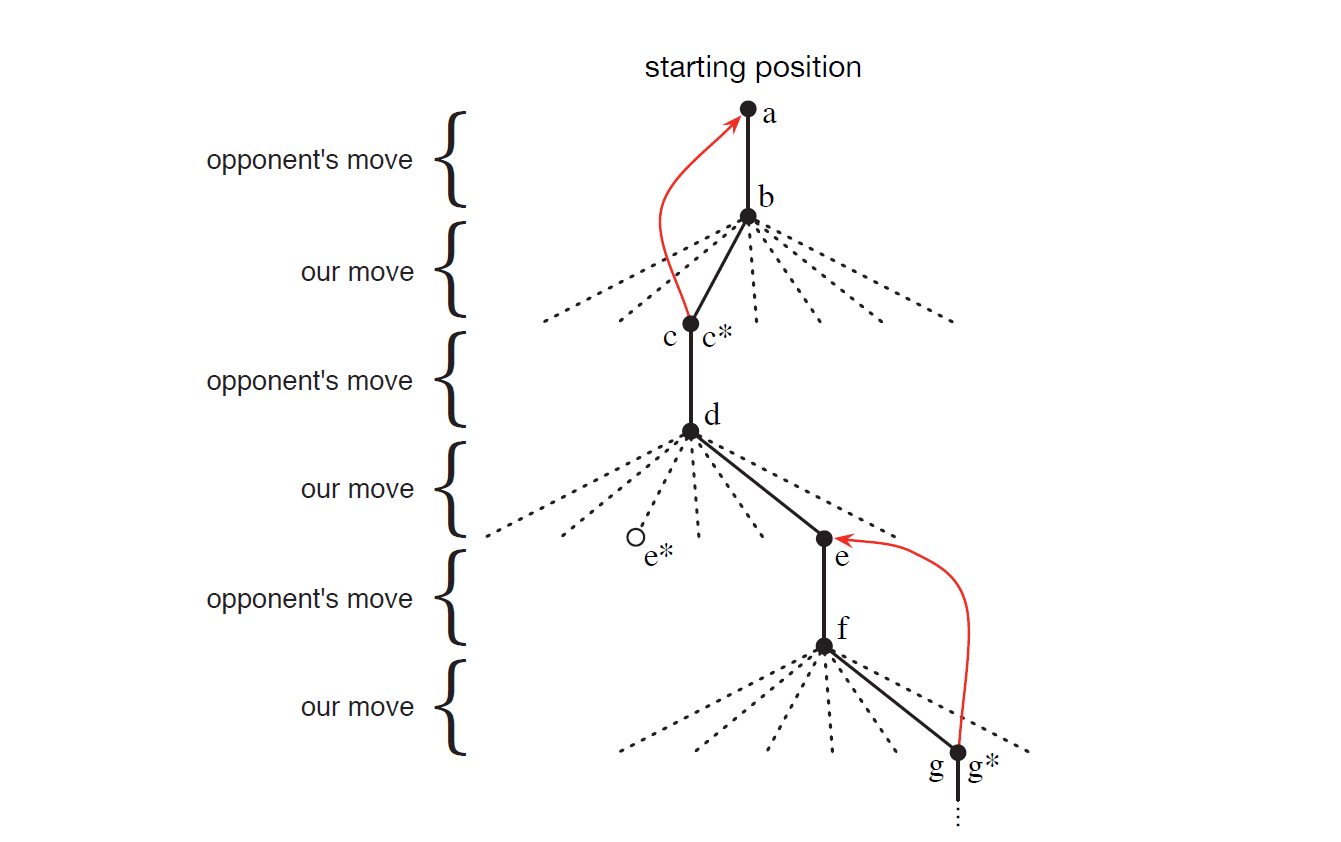
This diagram shows a Tic-Tac-Toe game played using a reinforcement learning strategy. Points a through g represent different state nodes. Solid black lines represent actual moves taken (state transitions), dashed lines represent alternative moves that were considered but not executed, and red lines represent the direction of value updates (explained in detail below).
We begin at node a. The transition from a to b represents the opponent's move. The multiple lines emanating from b represent multiple possibilities; the solid line b-c represents the action ultimately taken, while the dashed lines represent other possible actions that were considered but not chosen. In short, remember that solid black lines represent actions, dashed lines represent considered but unchosen actions, and the asterisk (*) indicates that the corresponding action is optimal according to the current value estimates.
Let me explain this with a concrete example:
(1) State a
Assume the board positions are labeled as follows:
1 2 3 4 5 6 7 8 9
Before the game begins, the board is empty — this is the situation at state a, representing an empty board:
···
···
···
(2) State a -> State b
The opponent moves first — the solid black line from a to b — placing X in the center at position 5:
· · ·
· X ·
· · ·
Once the opponent's piece is placed, a new board state is formed — this is state b. From a state perspective, a transition from state a to state b has occurred. During this transition, we do not learn, because it was the opponent's move.
(3) State b -> State c*
At state b, we evaluate all possible moves — every position except position 5. Each possible move corresponds to a new state. Suppose we have the following table:
| Move Position | Successor State | Estimated Value |
|---|---|---|
| 1 | c1 | 0.5 |
| 2 | c2 | 0.6 |
| 3 | c3 | 0.5 |
| 4 | c4 | 0.5 |
| 5 | Cannot place | N/A |
| 6 | c6 | 0.5 |
| 7 | c7 (c*) | 0.8 |
| 8 | c8 | 0.5 |
| 9 | c9 | 0.5 |
In this hypothetical table, the values correspond to the values already recorded for the new states. We can see that position 7's successor state c7 has the highest estimated value, so c7 is c*. Following the greedy strategy — choosing the action with the highest value — the board becomes:
· · ·
· X ·
O · ·
Here, we have chosen the optimal strategy. Let us introduce a new concept: the agent has made a decision and selected the optimal one. We will tentatively consider a greedy operation — one that is not the opponent's move and selects the action with the highest value function — as a genuine decision.
After this decision, there is a red arrow from c pointing back to a, representing a value update. In the process just described, we experienced a transition from state a to state c, where state c was reached via the greedy strategy. We now perform a value update on a, moving state a's estimate toward state c's estimate:
This is essentially a TD update, which we will discuss in detail in the chapter on TD methods. The purpose of this example is to demonstrate a reinforcement learning way of thinking — using new information from state c to update the value estimate of state a. In other words, through interaction with the environment, the agent has "learned" something here, and this "learning" is the value function update.
α is the learning rate, which determines the magnitude of the update. Mathematically, it controls how much the difference between the values of c and a affects the original value of a.
If α is 0.1, we can compute the new V(a) using the table above. In this process, state c — being a state that follows state a — has influenced a. This is a form of value backup.
(4) State c* to State d
The opponent makes a move. Suppose the opponent plays as follows:
X · ·
· X ·
O · ·
(5) State d to State e
As shown in the diagram, this is an exploratory move, since the optimal value was not selected.
In this case, no value update is performed for an exploratory move. This is actually an on-policy learning strategy, meaning the agent evaluates and improves its value function only through the policy it is currently executing. At the same time, the agent does not need to know the opponent's strategy or state transition probability model in advance — it gains experience through gameplay and continuously updates its value table. This makes it a model-free strategy as well. In later chapters, we will learn about strategies and paradigms that differ from this one; here, this serves only as a conceptual demonstration of the reinforcement learning way of thinking.
X · ·
· X ·
O · O
(6) State e to State f
X · X
· X ·
O · O
(7) State f to State g*
X · X
· X ·
O O O
The game is now over. Since the optimal strategy was selected here, a value update is performed on e. Let us summarize the value update formula:
Because this method is based on the difference between estimated values at two successive time points, it is called temporal-difference learning, or TD for short. If the step-size parameter α is appropriately decreased over time, the formula will converge; the converged value represents the optimal play against this imperfect opponent. Once we obtain a fully converged table, playing according to the table values constitutes the optimal policy against this opponent.
If the opponent's strategy changes slowly, then α should not be reduced to zero, so the agent can continually adapt to the opponent.
We can imagine that, because the agent has an explicit goal, it will ultimately learn a strategy with foresight and planning ability — a strategy that accounts for the delayed effects of its own actions. In short, if the opponent is a short-sighted player, the agent will learn to set multi-step traps. This is a prominent feature of reinforcement learning: even without a model of the opponent or explicit search over future states and action sequences, it can still achieve the effects of planning and foresight.
Let us summarize the key features of this game:
- Learning through interaction with the environment — in this game, the environment is the opponent player.
- There is an explicit goal: winning the game.
- Delayed reward is realized through the backup mechanism, yielding planning and foresight.
- Exploration vs. exploitation: sometimes less certain moves must be tried to discover better strategies.
- Experience-driven learning without needing a model of the opponent. (Of course, a model can also be used, as we will see later.)
In summary, through this example, the authors simply wish to demonstrate the characteristics of reinforcement learning. This Tic-Tac-Toe game has relatively few states, so it is easy to maintain values for all states. In practice, however, when reinforcement learning is combined with artificial neural networks, it can learn effectively even in games with enormous state spaces. Neural networks provide the program with the ability to generalize from experience, enabling it to choose appropriate moves in previously unseen states because these new states resemble ones the network has encountered before.
Supplementary Discussion: Evolutionary Algorithms
In the discussion above, the authors briefly mentioned evolutionary algorithms and noted that reinforcement learning and evolutionary algorithms are different. To compare these two approaches, I had Claude write a Q-Learning vs. Genetic Algorithm comparison, running 10 million games. The result was that the evolutionary algorithm won:
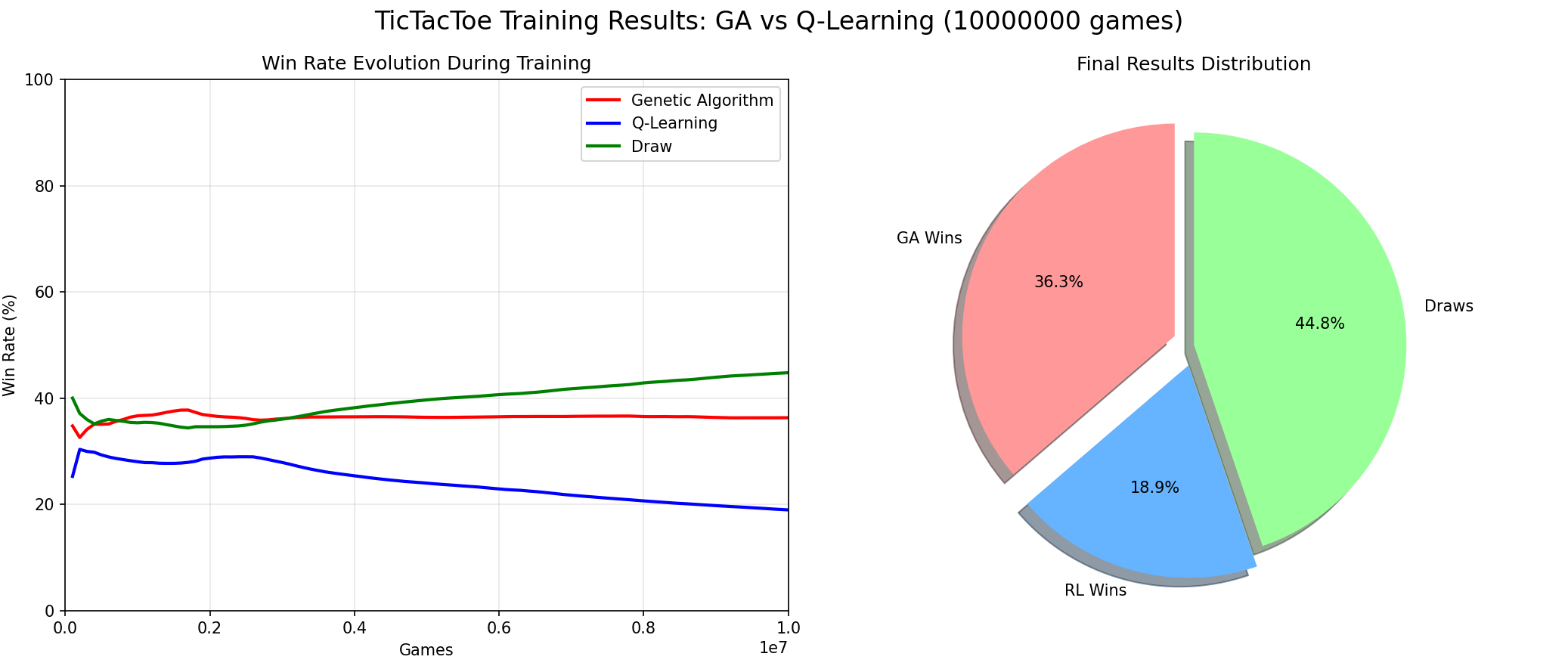
For Tic-Tac-Toe, because the state space is limited and the game is not complex, GA does not need generalization ability and can quickly find winning patterns. Reinforcement learning, facing a rapidly converging evolutionary algorithm, is suppressed over the long term and cannot cope. This shows that reinforcement learning is not invincible, and evolutionary algorithms are not useless.
It is worth noting that, with the integration of neural networks and reinforcement learning, RL has acquired the ability to handle more complex, high-dimensional state-space games (such as Gomoku, Go, StarCraft, etc.) — precisely the domains where evolutionary algorithms struggle. Therefore, reinforcement learning is primarily used to solve complex problems, while in simple environments, evolutionary algorithms remain an efficient and interpretable baseline method.
Note that this book mainly introduces traditional reinforcement learning methods and does not elaborate on neural network aspects (especially in the first half), but understanding these traditional methods is crucial for subsequent study of deep reinforcement learning (such as DQN, PPO, AlphaZero, etc.).
Summary
A summary of the key points of reinforcement learning. Because the first sentence resists convenient translation, I preserve the English here for readers to appreciate on their own:
- Reinforcement learning is a computational approach to understanding and automating goal-directed learning and decision making.
- What distinguishes RL from other computational approaches is that it learns directly through interaction with the environment, without requiring demonstrative supervision or a complete environment model.
- RL uses the formal framework of Markov decision processes to define the interaction between agent and environment, expressed in terms of states, actions, and rewards.
- Values and value functions are central to most reinforcement learning methods discussed in this book. The authors believe that value functions are essential for efficiently searching the policy space.
- RL's use of value functions distinguishes it from evolutionary algorithms, which search directly in the policy space.
A Brief History of Reinforcement Learning
The early history of reinforcement learning comprises two independently developed threads that later intersected and merged in modern reinforcement learning. The following historical summary has been reordered and refined from the original text.
(1) Thread One: Optimal Control
The first thread concerns optimal control problems and their solution through value functions and dynamic programming. To a large extent, this thread does not involve learning. The term "optimal control" appeared in the late 1950s to describe a problem: designing a controller that minimizes or maximizes the behavior of a dynamical system over a period of time. This problem was primarily developed by Richard Bellman and others in the mid-1950s, using two core concepts — the state of a dynamical system and the value function (or optimal return function) — to formulate what is known as the Bellman Equation. This class of problems is now called Dynamic Programming. Bellman also introduced the discrete stochastic version of optimal control problems, namely Markov Decision Processes (MDPs). Ronald Howard proposed policy iteration methods for MDPs in the 1960s — all of these are core foundations of modern reinforcement learning theory and algorithms.
Dynamic programming is now considered the only feasible approach for solving general stochastic optimal control problems. Its main drawback is what Bellman called the curse of dimensionality — computational requirements grow exponentially with the number of state variables. Nevertheless, DP is more efficient and broadly applicable than other general methods, and since the 1950s it has been extensively developed and extended to partially observable MDPs, many applications, approximation methods, and asynchronous methods.
Prior to Chris Watkins's 1989 work, DP had never been connected with the learning process. The reason for this disconnect remains unclear, but Watkins's reinforcement learning methods based on MDPs are now widely adopted. Since then, this connection has been extensively developed.
The authors argue that optimal control methods such as dynamic programming should also be considered part of reinforcement learning methods, since many DP algorithms possess an incremental and iterative nature similar to learning methods: gradually approaching the correct answer through successive approximation.
(2) Thread Two: Trial-and-Error Learning
The second thread originates from animal psychology, learning primarily through trial and error. This thread runs through some important early AI research and drove the revival of reinforcement learning in the early 1980s.
The idea of trial-and-error learning can be traced back to Alexander Bain's 1850s descriptions of "groping and experiment." The first person to articulate this idea concisely was psychologist Edward Thorndike, who proposed the Law of Effect: the consequences of behavior influence the likelihood of that behavior recurring. This view describes the effect of reinforcing events on behavioral selection.
The term "Reinforcement" in the context of animal learning first appeared in the 1927 English translation of Pavlov's work on conditioned reflexes. Pavlov described reinforcement as the strengthening of behavioral patterns exhibited by an animal after receiving a stimulus (the reinforcer), given an appropriate temporal relationship between that stimulus and another stimulus or response.
Some psychologists further expanded the concept of reinforcement to include not only the strengthening of behavior but also its weakening; not only the application of stimuli but also their removal or termination. Only when the strengthening or weakening of behavior persists after the reinforcer is removed can it be considered reinforcement; a stimulus that merely attracts attention without producing lasting behavioral change does not qualify as a reinforcer.
In 1948, Alan Turing proposed a "pleasure-pain system" in a report that essentially followed the Law of Effect. Turing's diary entries can be summarized as follows: when the system faces an unknown situation and does not know what to do, it first randomly tries some actions. If the attempt results in pain (negative feedback), the system abandons those attempts. If it results in pleasure (positive feedback), the system remembers and continues using those attempts.
Many ingenious electromechanical machines were built to demonstrate trial-and-error learning — for example, Thomas Ross's maze-running machine in 1933, W. Grey Walter's mechanical tortoises in 1951, and Claude Shannon's maze-navigating mouse machine "Theseus" in 1952.
In 1954, Farley and Clark described a neural network-based digital simulator that could learn through trial and error, though their interests subsequently shifted to generalization and pattern recognition. This also initiated a trend of confusing learning types — many researchers thought they were studying reinforcement learning when they were actually studying supervised learning. To this day, some textbooks still downplay or blur the differences between these two types of learning. For instance, some use "trial and error" to describe artificial neural networks that learn from training examples. This confusion is understandable, since these networks also use error signals to update connection weights, but it overlooks the essence of trial-and-error learning: selecting actions based on evaluative feedback, rather than relying on explicit correct answers.
In the 1960s, Minsky's paper "Steps Toward Artificial Intelligence" discussed several important issues related to trial-and-error learning, including Prediction, Expectation, and what he called the Basic Credit-Assignment Problem — the problem of distributing credit for success among the many decisions that contributed to it.
Although trial-and-error learning received relatively little attention, there were some notable exceptions. New Zealand researcher John Andreae developed a system called STeLLA that learned through trial-and-error interaction with the environment. The system included an internal model of the world and later incorporated an internal monologue mechanism to handle hidden states. Andreae later placed greater emphasis on learning from a teacher but retained the trial-and-error learning characteristic. A notable feature of his work was the use of "leakback" to implement a credit assignment mechanism similar to the backup updates in this book. Unfortunately, his work did not reach most researchers.
More influential was the work of Donald Michie, who developed a system called MENACE for learning to play Tic-Tac-Toe. He later developed, with Chambers, a system called GLEE and a controller called BOXES for training a cart-pole balancing task. The pole-balancing task had a profound influence on subsequent research. Michie insisted that trial-and-error and learning are central to artificial intelligence.
In the 1970s, Widrow, Gupta, and Maitra introduced selective bootstrap adaptation and demonstrated its application to the game of blackjack. The term "critic," which we use in reinforcement learning today, originated from their paper.
Learning automata are simple, low-memory machines used to increase the probability of obtaining reward in such problems. Learning automata originated from the 1960s work of Soviet scientist M. L. Tsetlin and colleagues, and were extensively developed in the engineering field, leading to research on stochastic learning automata.
The ideas behind stochastic learning automata can be traced back to William Estes's statistical learning theory in psychology, which was later adopted by economics researchers and gave rise to a line of reinforcement learning research in economics. One goal of this direction was to study AI agents that behave more like humans, rather than the idealized agent models of traditional economics. This approach subsequently extended to game theory.
In 1975, John Holland proposed a general theory of adaptive systems based on selection principles and later developed his classifier systems more fully — these were genuine reinforcement learning systems incorporating the concepts of association and value functions.
The person who subsequently rekindled the trial-and-error learning thread in artificial intelligence was Harry Klopf, to whom this book is dedicated. Klopf pointed out that, as researchers had become almost exclusively focused on supervised learning, key aspects of adaptive behavior were being neglected. Klopf believed that what was being missed was the hedonic drive in behavior: the drive to obtain certain outcomes from the environment, to control the environment to achieve desired goals and avoid undesired outcomes. This is precisely the core idea of trial-and-error learning.
Klopf's views profoundly influenced Sutton and Barto — the two authors of this book — making them aware of the distinction between supervised learning and reinforcement learning, and ultimately leading them to focus on reinforcement learning. Much of the authors' and their colleagues' early work was devoted to demonstrating that reinforcement learning and supervised learning are fundamentally different. Other research showed how reinforcement learning could address key problems in artificial neural network learning, especially learning algorithms for multi-layer neural networks.
(3) Thread Three: Temporal-Difference Learning
The third thread is the method used in the Tic-Tac-Toe example above, related to temporal-difference methods. This thread converged with the two earlier threads in the late 1980s to form the modern reinforcement learning field presented in this book.
The key characteristic of temporal-difference learning methods is that they are driven by prediction errors of the same quantity at different time points. This seemingly minor point has not been as broadly influential as the two threads above, yet it plays an important role in reinforcement learning, partly because it is unique to and exclusive to reinforcement learning.
Arthur Samuel (1959) was the first to introduce a learning method incorporating temporal-difference ideas in his famous checkers program. Although he did not cite Minsky or psychological theory, his inspiration may have come from Claude Shannon's (1950) concept of using evaluation functions for self-improvement.
Klopf (1972) was the first to explicitly combine trial-and-error learning with temporal-difference ideas. He proposed the concept of "generalized reinforcement," suggesting that every unit in a system can interpret its input as reward or punishment, thereby performing local reinforcement learning.
Sutton (1978) further developed this idea, proposing learning rules driven by changes in temporally successive predictions, and together with Barto proposed a classical conditioning psychological model based on temporal differences (Sutton and Barto, 1981, 1982). Subsequently, an increasing number of psychological models and even some neuroscience models were incorporated into this theoretical framework.
Although the development path of temporal-difference learning was somewhat obscure, its emergence marked the true maturation of reinforcement learning methods and laid the foundation for subsequent algorithmic developments (such as TD(λ), Q-learning, and Actor-Critic methods).
In the 1980s, the combination of temporal-difference learning and trial-and-error learning gave rise to the Actor-Critic architecture, which was successfully applied to reinforcement learning tasks such as the pole-balancing problem. Sutton (1988) proposed the TD(λ) algorithm, further advancing the theoretical refinement of this approach.
Meanwhile, Witten's (1977) work was found to be among the earliest published research incorporating TD ideas. His TD(0) method provided a foundation for subsequent control in MDPs, spanning both the trial-and-error learning and optimal control directions, making it an important milestone in the early development of TD learning.
Watkins's (1989) Q-learning method ultimately brought temporal-difference learning and dynamic programming ideas together, thoroughly merging the three main threads of reinforcement learning. This development greatly advanced progress across the entire field.
In the 1990s, the success of Tesauro's TD-Gammon program brought TD learning into the mainstream.
Since then, the connection between reinforcement learning and neuroscience has grown increasingly close. Research has found that the activity of dopamine neurons in the brain closely matches the prediction errors in TD learning algorithms. This discovery has sparked a great deal of interdisciplinary research, making temporal-difference learning not only an important tool in artificial intelligence but also a key model for understanding learning mechanisms in the brain.
(4) Extension: Modern Developments (Deep Reinforcement Learning)
This section is contributed by the reader:
Driven by the convergence of the three threads described above, several of the most important reinforcement learning algorithms were proposed and widely disseminated in the 1990s: Q-learning in 1992, SARSA in 1996, and REINFORCE in 1999. All three algorithms were influenced by Sutton and Barto's early research on TD learning and the Actor-Critic architecture.
Entering the 21st century, with the rapid development of deep learning, reinforcement learning achieved new breakthroughs. In recent years, several milestone deep reinforcement learning algorithms have been proposed, further expanding the boundaries of reinforcement learning applications. Representative achievements include: Deep Q-Network (DQN) in 2013, the first to achieve end-to-end policy learning from high-dimensional perceptual inputs; A3C (Asynchronous Advantage Actor-Critic) in 2016, which effectively improved training efficiency and convergence speed; PPO (Proximal Policy Optimization) in 2017, which balances stability and computational efficiency in policy optimization; and TD3 and SAC in 2018, which addressed value estimation bias and exploration in continuous action spaces, respectively. Together, these algorithms have propelled reinforcement learning into the era of deep intelligence.
During this phase, reinforcement learning gradually formed a unified learning framework centered on policy evaluation and policy improvement, and evolved into three mainstream approaches according to different policy update methods: value-function-based methods (such as DQN), policy-based methods (such as REINFORCE, PPO), and Actor-Critic hybrid methods (such as A3C, DDPG, SAC). This phase also established the basic distinction between on-policy and off-policy learning mechanisms, as well as paradigms for handling discrete and continuous action spaces, providing the theoretical and practical foundation for the systematization and scalability of the reinforcement learning algorithm ecosystem.
As of 2025, reinforcement learning has widely permeated numerous research fields and industrial application scenarios, including but not limited to autonomous driving, intelligent manufacturing, quantitative finance, game AI agents, and robotic control. Simultaneously, reinforcement learning has cross-pollinated with many related fields, giving rise to a series of emerging research directions such as meta-learning (Meta-RL), multi-agent reinforcement learning (MARL), transfer and continual learning, imitation learning, model-based reinforcement learning (Model-based RL), world models, Sim-to-Real policy transfer, and more. These directions continuously expand the capability boundaries of reinforcement learning and steer it toward more general, interpretable, efficient, and safe intelligent decision-making systems.
Robot Learning
What Is Robot Learning?
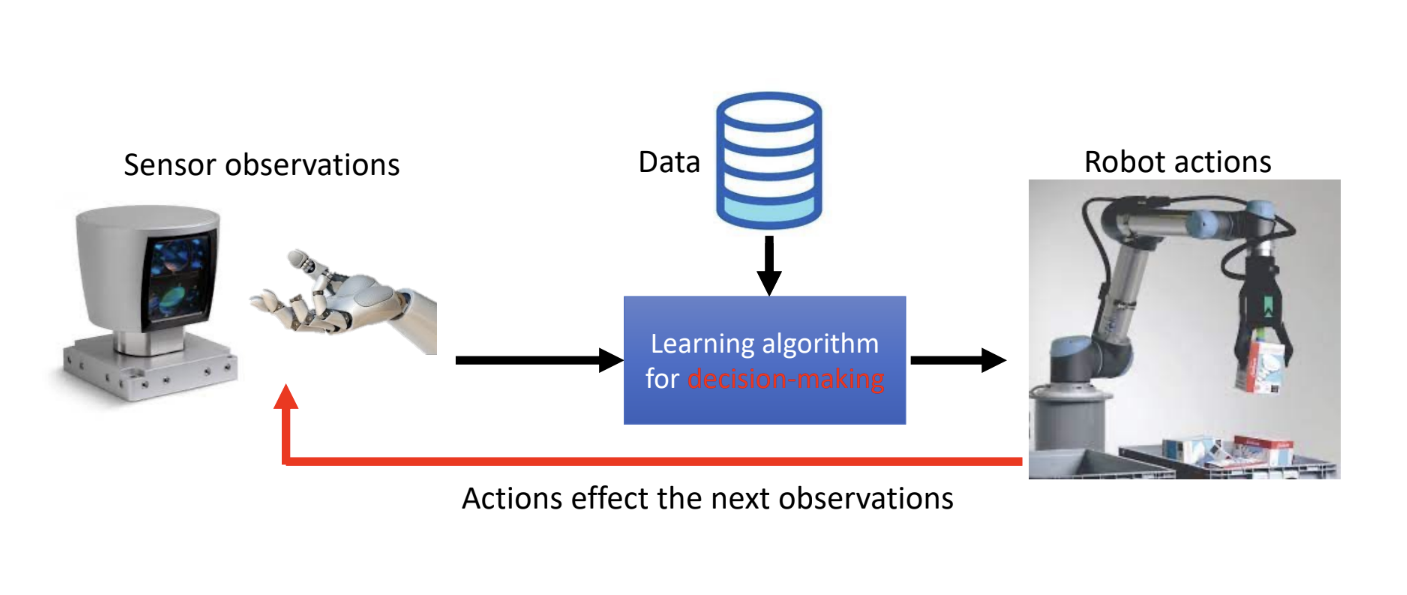
Robot Learning is distinct from Robotics. It is an interdisciplinary field at the intersection of artificial intelligence, machine learning, and robotics, with the goal of enabling robots to learn through experience and interaction rather than through manual programming.
If we were to define robot learning as a research direction or course, we could put it this way:
Robot learning is about enabling robots to learn how to make sequential decisions in the physical world. (Learning to make sequential decisions in the physical world)
In Chapter 2, I will review some classical robot control methods. In many high-demand scenarios, classical control and optimization remain mainstream and do not necessarily require machine learning. However, traditional robotics separates perception and control — an approach that is both difficult and inconsistent with the principles of biological intelligence. For example, traditional robotic systems are typically designed as a modular linear pipeline:
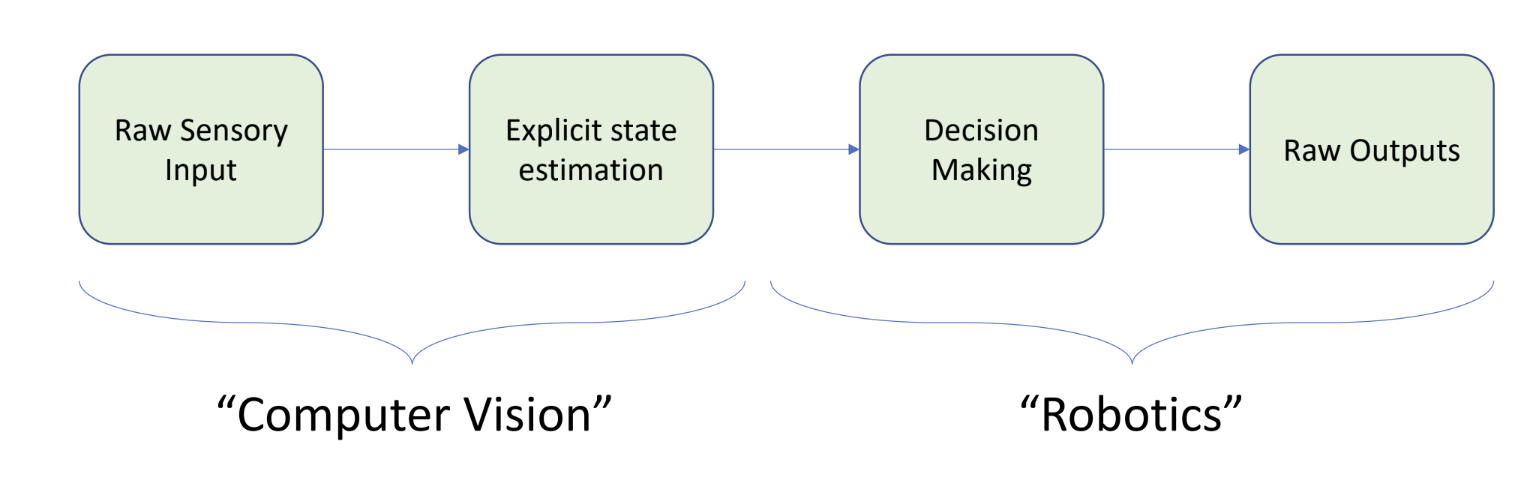
This pipeline is artificially divided into two independent domains:
- Computer vision: responsible for converting sensor data into meaningful information
- Robotics: making decisions based on sensor data and computing high-dimensional control commands (such as inverse kinematics)
The cleaning robot project I worked on in 2024 is a classic example of the pipeline described above:
- First, the robot builds a map through SLAM.
- After building the map, it converts the map into a cleaning path through a series of operations.
- AMCL is used to localize the robot so it knows where it is.
- The robot then cleans by following the cleaning path.
- If an obstacle appears, the sensor identifies it and marks it on the cleaning path, and the robot navigates around it.
However, both cognitive science and current AI development are pursuing end-to-end input and output. In other words, Perception and Action are coupled — inseparable.
Yet perception processing itself is very difficult, and control is also very difficult. Connecting these two difficult, complex, high-dimensional spaces to achieve end-to-end high-dimensional input and high-dimensional output is even more challenging. Thus, the interdisciplinary field of robot learning was born:
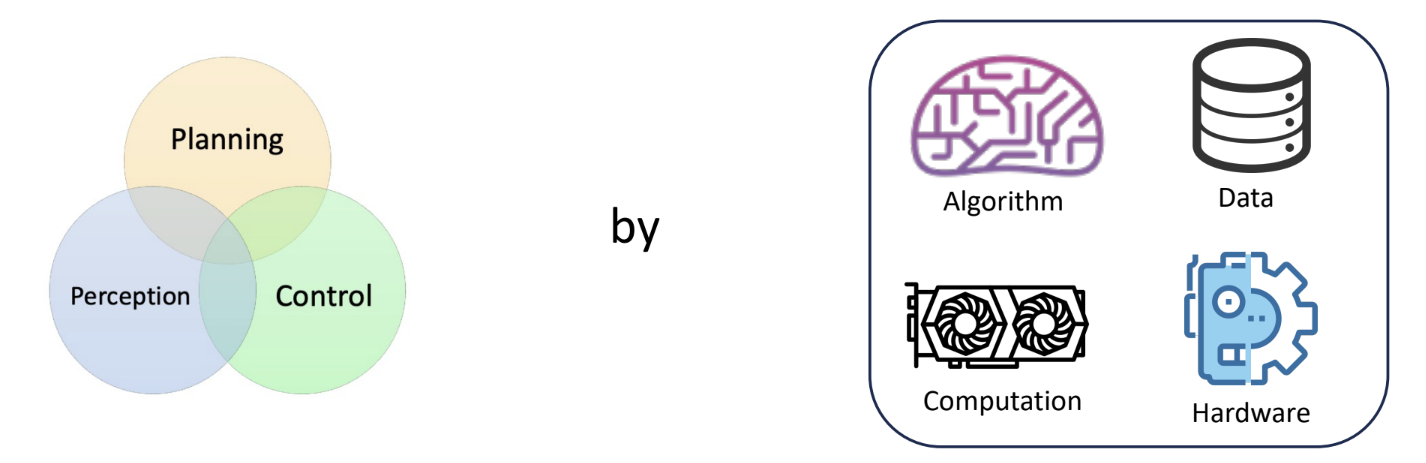
The goals of robot learning are:
- Unify Modules: Break down the barriers between planning, perception, and control, merging them into a single, end-to-end system. This unification is achieved through the combination of algorithms, data, compute, and hardware.
- Improve individual modules: Through embodied intelligence, robots learn from real physical-world interactions, significantly improving the performance of each individual module. We have made far more progress on this point than on module unification.
Generally speaking, the ultimate goal of robot learning is:
To build general-purpose embodied intelligence.
This is a direction that history has validated as correct, but we still face numerous difficulties and challenges.
Over the past decade or so, the development of deep learning and large language models has been nothing short of an epoch-making technological revolution. Deep learning's performance has eclipsed all expert systems. Looking at the overall direction, the future development of robots will rely more on self-learning systems rather than hand-crafted designs, continuously enhancing robots' general capabilities and self-improvement abilities. In Sutton's "The Bitter Lesson," Sutton reflects on his decades of AI research and explicitly states that presumptuous human intervention is the wrong path, while computational power and algorithms are the right path.
Taking LLMs as an example, their performance is far beyond the reach of expert systems. Their working principles mainly include:
- Architecture: Transformer
- Data: Massive amounts of web text, books, Wikipedia, etc.
- Loss: Next token prediction.
- Optimization: Stochastic Gradient Descent (SGD).
- Generation: Autoregressive — generating tokens one at a time.
However, the success of LLMs depends on the virtually unlimited text data available on the internet. Robot learning cannot obtain such massive amounts of high-quality physical interaction data. Furthermore, LLMs learn general language patterns by predicting the next word — can robot learning also find a similar "next action" prediction model that unifies different tasks? This is an open and important research direction.
Encouragingly, current robot learning has already demonstrated performance exceeding "expert systems" in many areas:
- In specific domains, it has surpassed traditional manual control or rule-based systems, such as robotic arm grasping, delivery robots, autonomous driving, and surgical robots.
- However, it is still very far from generality, as current robots are highly dependent on human-defined tasks, carefully curated data collection, and sim-to-real transfer after training in simulation. They cannot yet flexibly learn and transfer knowledge in arbitrary environments the way humans can.
Using deep reinforcement learning's performance in games as an example, let us examine the differences between robot learning and deep reinforcement learning:
| Characteristic | Game AI (e.g., AlphaGo) | Robot Learning | Explanation |
|---|---|---|---|
| Environment | Known & static | Unknown & dynamic | The rules of Go are fixed; the environment is a completely predictable digital world. The physical world is full of uncertainty and can change unexpectedly at any time. |
| Tasks | One specific task | Many tasks | AlphaGo was built solely to play Go. A robot may need to complete multiple entirely different tasks such as opening doors, grasping, and navigation. |
| Goals | Clear optimization goals | Unclear goals | Game goals are very explicit: win. Rewards are easy to define. But in reality, goals like "clean the table well" are very hard to quantify with a simple mathematical formula. |
| Learning Mode | Offline learning is enough | Requires online adaptation | AlphaGo can learn by playing millions of offline games against itself. Robots must adjust and adapt in real time while interacting with the real world. |
| Action Speed | Slow action | Relatively fast real-time action | Decisions in games can take seconds or even longer. Autonomous vehicles or robotic arms need to react at high frequency (e.g., 50Hz). |
| Cost of Failure | Allows failures | Physics doesn't forgive! | Losing a game is inexpensive and can be replayed. In the physical world, a single failure can damage the robot, the environment, or even harm people. |
| World Model | Discrete digital world | Continuous physical world | Game states and actions are typically discrete (e.g., positions on a board). The physical world is continuous, with infinitely many possible variations of any action. |
The difficulties listed above are not specific to robots performing particular tasks, but rather a lesson revealed by countless experiences over nearly a century of AI research history.
Topics in Robot Learning
The main topics in robot learning today include:
- Imitation Learning
- Model-free RL
- Model-based RL
- Offline RL
- Preference-based Learning
- Online Adaptation
- Sim2Real, Real2Sim2Real
- ...
Overall, robot learning remains an open field.
Before studying robot learning, please review the following topics:
- Supervised Learning, Unsupervised Learning
- Generative Model
- Non-parametric Learning
- Architecture: MLP, ResNet, CNN, GNN, RNN, LSTM, Transformer
- Optimization: GD, SGD, etc
- Uncertainty Quantification
- Verification
Note: It is recommended to complete the following first, then return to robot learning:
- UCB CS285: DRL
- Machine learning fundamentals and deep learning optimization
Note: Chapter 2 of these notes covers robotics fundamentals, including forward and inverse kinematics, which are important topics from Robotics proper and are not themselves Robot Learning content.
After completing the above prerequisites such as DRL, we will enter the domain of robot learning. (Robot learning's current content is primarily research-oriented and academic, so without mastering the fundamentals, it will be very difficult to read the latest papers.)
Before beginning the study of Robot Learning, the CMU professor shared a very interesting anecdote:

The image above shows Ilya at a dinner gathering in 2008, trying to convince everyone at the table to work on deep neural networks. At the time, almost everyone believed that DNNs were not going to work. There is often a huge gap between theory and practice; what doesn't work today may work very well in the future. For technologies with potential, we must maintain an open and long-term perspective, even if they appear infeasible or immature at present, because future developments may completely change the landscape.
For example, Overparameterization was once considered a bad idea, but in practice, overparameterized models are performing better and better — upending classical learning theory.
From DQN to Human-Like Machines
This section is primarily based on key insights from a survey paper: "Building Machines That Learn and Think Like People", exploring the topic of machines that think like humans.
Modern cognitive science holds that building machines that learn like humans requires changing the current engineering approach to AI learning. The paper's authors therefore advocate:
- Machines should build causal models of the world to support explanation and understanding, rather than merely performing pattern recognition.
- Learning should be grounded in intuitive theories of physics and psychology. Intuitive theories explore the informal scientific theories that the human brain innately or automatically forms early in development — that is, children in early development actively construct theories to understand the world, rather than understanding it solely through perception.
- Leveraging compositionality and learning-to-learn to rapidly acquire and generalize to new tasks and new situations.
There are some particularly illuminating observations from intuitive theory:
- Infants first develop intuitive physics, building a cognitive theoretical framework for understanding the physical laws of the world, including objects, space, motion, and forces.
- Infants at six months already demonstrate understanding of object permanence.
- Infants show surprise when seeing a ball pass through a wall.
- Children believe heavier objects fall faster.
- Toddlers (ages 3-5) develop intuitive psychology, building a framework for understanding others' mental states.
Let us take DQN's classic Atari game task (Frostbite) as an example:
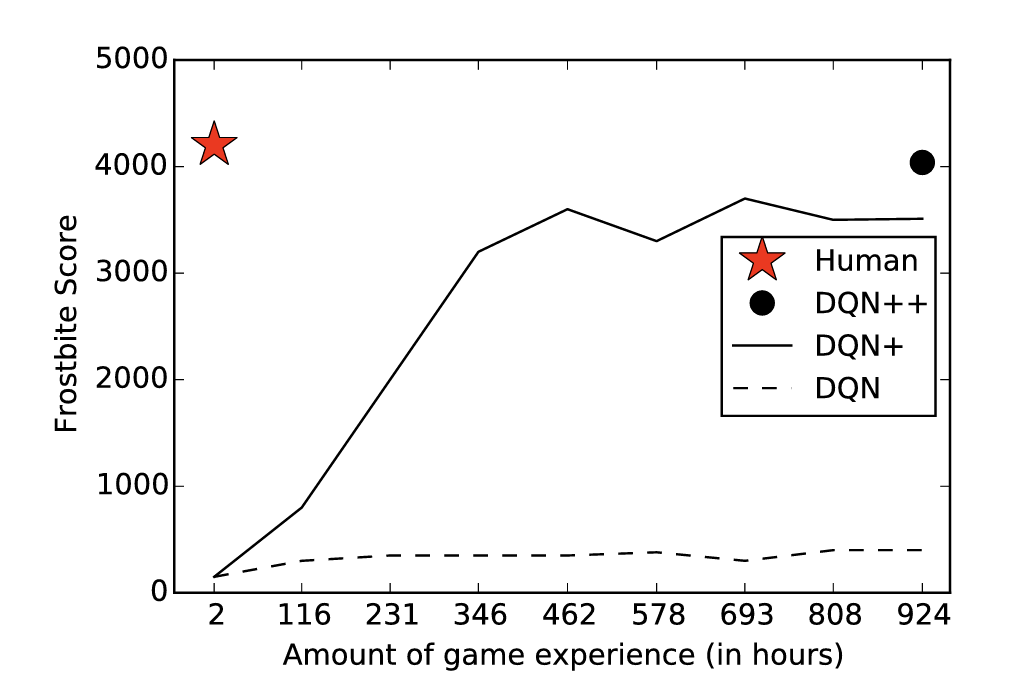
We can see that neural networks can approximate human-level performance on recognition tasks, but require far more experience and learning time than humans. Frostbite is a game where the player controls a character with the goal of building an igloo within a time limit. The igloo is built incrementally by jumping onto ice floes floating on the water; each time the character lands on an active ice block, another piece is added to the igloo.
Since the player must execute a series of correct actions before receiving a delayed reward, DQN's performance on this game is among the worst of the 49 Atari games tested. Optimized versions of DQN can reach human-level performance, but in terms of human learning experience, a human player's 2 hours of experience requires DQN++ to train for 924 hours, with extremely poor performance in the first 100-200 hours. This disparity stems from fundamental differences in how humans and DQN learn:
- Humans can rapidly form task schemas.
- Humans do not depend on sparse score-based feedback (they can reason about the high-level goal of building an igloo).
- Humans can easily adapt to different objectives, such as stalling for time or discovering hidden elements.
Of course, humans do not start from scratch either — they enter new tasks with a wealth of prior knowledge, including intuitive physics, intuitive psychology, and task structure reasoning abilities. DQN, by contrast, learns entirely from random pixels and rewards. Therefore, if we want machines to learn and think like humans, we might consider this question: can machines also approach new problems armed with rich prior knowledge, rather than starting from zero?
Intuitive physics posits that humans run an approximate physics engine in their minds for probabilistic and approximate simulation. This enables infants to quickly develop expectations about persistence, continuity, cohesion, and solidity; to distinguish rigid bodies, soft bodies, and liquids; and to gradually master basic concepts such as inertia, support, containment, and collision.
Intuitive psychology holds that infants can early on distinguish animate intelligent agents from inanimate objects, and expect intelligent agents to have goals, to act efficiently, and to be social (helping, harming, showing in-group/out-group preferences). This type of representation supports rapid learning from demonstration — for instance, after watching an expert play, one can learn the gameplay without personally experiencing punishments.
Traditional deep networks mostly implement learning as gradual weight adjustments, making them strong at pattern recognition with big data but extremely data-inefficient compared to humans: humans can learn new concepts or game strategies from few or even single examples, without requiring massive samples. Clearly, humans do not learn using classifier models. One conjecture is that what humans learn are rich models that can be used for classification, prediction, action, communication, imagination, explanation, and composition. We attempt to highly abstract this rich model into three elements: compositionality, causality, and learning to learn.
Compositionality is the ability to combine finite primitives into infinitely complex representations. This compositionality is ubiquitous in human cognition — pervading objects, concepts, and language. For example, in the Frostbite game, humans can recognize that the scene is composed of reusable objects (birds, fish, ice floes, igloos) with relationships between them, and this recognition enables effortless generalization of experience to different scenes and levels.
Causal models are generative models that reflect the data-generating mechanisms of the real world. Causality itself is notoriously difficult to analyze, but the human brain is innately equipped with a capacity for causal inference — even when the inferences may be wrong. Humans constantly replay past events, ruminate on history, and generate thoughts like "if I hadn't done X" or "if I had done Y, things would be different now" — this is a form of causal inference practice.
Learning-to-learn is a core and profound concept in today's AI. Humans are innately endowed with this ability: someone who has learned English grammar finds it easier to learn Spanish; a skateboarder more easily learns snowboarding; a designer who masters certain composition techniques can immediately apply them across different projects. Meta-learning in deep learning today addresses this very topic.
In summary, when we set out to build a robot with learning capabilities — one that does not need to master all skills in advance but can adapt to different household environments — we must confront the problems described above that current deep learning cannot solve. Robots operate in a highly complex, three-dimensional, real physical world full of uncertainty, with environmental complexity far beyond that of Atari games. The challenges robots must address include:
- Robots must physically interact with the world. A robot that has only learned pattern recognition without understanding causal models of the world will be unable to complete tasks in open environments.
- Robots must possess intuitive physics. All robot actions — walking, navigating, manipulating objects — are governed by physical laws. Therefore, a robot should be endowed from the start with a set of basic physical priors, rather than learning gravity exists from scratch through countless failures (such as breaking itself countless times).
- Robots with intuitive physics can perform mental simulation — predicting physical consequences before acting — which is essential for intuitive psychology. For future robots to enter homes, hospitals, and schools as human assistants and companions, they must understand human intent, which is crucial for both task completion and Human-Robot Interaction (HRI).
- Robots must be able to learn reusable skills, thereby mastering compositionality. For example, by making coffee, a robot should be able to acquire a series of reusable sub-skills (primitives) such as finding a cup, picking up the cup, walking to the coffee machine, and operating the coffee machine.
- Robots cannot possibly exhaust all training data across every home and every factory environment. They must possess the ability to rapidly adapt to new environments and new objects. Learning-to-learn and meta-learning technologies must develop to the point where robots can master general-purpose meta-skills.
From human intelligence, we can draw the following important inspirations:
- Robots must possess a simplified model of human psychology to build intuitive psychology, thereby aligning with human mental models — this is what will enable robots to integrate into human society.
- Robots must master lifelong meta-learning capabilities.
- Data efficiency and prior knowledge are critical.
- Intuitive physics may be combined with deep learning's powerful perceptual capabilities through Neuro-symbolic AI, forming structured and model-based intelligence.
As we can see, the limitations of current deep learning and reinforcement learning are most acutely manifested in the domain of robotics. The core task of building general-purpose intelligent robots must encompass understanding how the world works, being able to reason about the consequences of actions, and being able to generalize — learning to learn.
Background Knowledge
This section reviews some background knowledge related to robot learning, such as important concepts in deep learning, which are highly relevant to robot learning. These topics are covered in the machine learning and deep learning notebooks; here they are summarized at a high level for convenient review.
For content on machine learning and deep learning, see the machine learning fundamentals and DNN sections in the deep learning notes.
Learning Theory is the theoretical foundation of machine learning and artificial intelligence. This field primarily addresses fundamental questions such as:
- Learnability: What kinds of concepts or problems can be learned from data? How much data is needed to learn well?
- Generalization: Why can a model that performs well on training data also perform well on unseen new data? How can we quantify and guarantee a model's generalization ability?
- Complexity: How hard is it to learn a given problem? How do we measure a learning algorithm's efficiency?
- Convergence: How long does a learning algorithm need to find the optimal solution?
Representative theories include:
- PAC Learning (Probably Approximately Correct Learning) — a framework for analyzing how likely an algorithm is to learn an approximately correct model.
- VC Theory (Vapnik-Chervonenkis Theory) — defines the VC dimension to measure model complexity and provides upper bounds on generalization error.
- Rademacher Complexity — another way to measure model complexity and generalization ability.
From a psychology perspective, learning theory concerns how humans and animals learn:
- How do cognition, behavior, and environment interact to produce knowledge and skills?
- How is knowledge absorbed, processed, and remembered by the brain?
- Why do different teaching methods affect learning outcomes differently?
- What roles do motivation, emotion, and environment play in learning?
Representative theories:
- Behaviorism: Pavlov's dog — learning is the association between external stimuli and responses.
- Cognitivism: Views learning as an information processing process, analogous to a computer's input, processing, and output.
- Constructivism: Emphasizes that learners actively construct their own knowledge systems rather than passively receiving information.
In neuroscience, learning theory attempts to explain the physical basis of learning at the biological and chemical level:
- When learning occurs, how do neural connections (synapses) in the brain change?
- How is memory encoded, stored, and retrieved in the brain?
- Hebbian Learning: "Cells that fire together, wire together" — how is this realized at the molecular level?
A conceptual awareness of these topics is sufficient here; in-depth study of learning theory is not necessary at this point.