LLM 越狱攻击
LLM 越狱(jailbreaking)是指攻击者诱导模型绕过自身的安全边界,让它生成原本应该拒绝、限制或降级处理的内容。与传统对抗样本不同,越狱通常并不依赖像素级微扰,而是利用指令层、上下文层和策略层的冲突。
越狱问题不是单一 prompt trick,而是一整套 prompt-based、token-based、multi-turn、automated black-box 攻击的集合。本文按攻击面与防线来整理这些知识点,而不是把它们当成几种零散“花招”。

图示来源:Tufts EE141 Trusted AI, Lecture 6, Slide 7。图像说明:图中把 reliability、safety、fairness、counter misuse、privacy、alignment 等问题并列展开。知识说明:越狱只是 LLM 安全中的一个子问题,它必须放在更大的风险版图里理解。
1. 什么是越狱
1.1 越狱与 prompt injection 的区别
两者经常一起出现,但不完全相同:
| 概念 | 目标 | 典型场景 |
|---|---|---|
| Jailbreak | 让模型绕过 refusal / safety policy | 诱导模型回答危险问题 |
| Prompt Injection | 让外部输入劫持 system intent | 在 RAG / agent 中污染控制流 |
在简单聊天场景里,两者可能表现相似;在 agent 系统中,prompt injection 更强调“控制流劫持”,而 jailbreak 更强调“策略绕过”。工程实现上,这两类问题最终会在 LLM与Agent系统安全 会合。
1.2 为什么 LLM 容易被越狱

图示来源:Tufts EE141 Trusted AI, Lecture 6, Slide 38。图像说明:这一页用“让目标 LLM 生成原本应拒绝内容”的方式给出越狱定义。知识说明:这里的关键不是攻击者说了多么奇怪的话,而是模型的行为边界被重新解释了。
根本原因在于:模型学习的是概率分布和行为偏好,而不是像传统安全系统那样的强不可违约束。攻击者只要找到能同时满足“语言上合理”和“策略上偏移”的输入,就可能打开缺口。
一个抽象写法是:
攻击并不需要显式知道这两个项,只需要通过试探性提示不断逼近能降低 refusal 的输入分布。
2. 攻击面类型
2.1 Prompt-based jailbreak
最常见的一类越狱通过 prompt engineering 直接制造策略冲突,例如:
- “忽略你之前的所有指令”
- 角色扮演与虚构上下文
- 开发者模式 / DAN 风格模板
- 把敏感请求包装成教育、测试、小说或编码任务
课程里把这类攻击进一步区分为:
- 手工 prompt
- 自动搜索生成的 prompt
- 多轮分解 prompt
2.2 Token-based / suffix 攻击
这一类攻击更接近经典白盒或半白盒优化:寻找一段特殊 token 序列,使模型更可能输出违禁内容。代表性方法包括:
- GCG(Greedy Coordinate Gradient)
- AutoDAN / token-level evolutionary search
- 基于目标 logit 的 suffix optimization
这些攻击往往用于研究基准,因为它们能更系统地衡量模型的对齐脆弱性。

图示来源:Tufts EE141 Trusted AI, Lecture 6, Slide 47。图像说明:页面用颜色编码把 GCG 拆成 Goal string (G)、Target string (T) 和 Suffix (S) 三部分,并给出优化目标公式。知识说明:GCG 的关键不是生成乱码,而是把越狱变成了一个可优化的离散搜索问题——这是 token-based 攻击与 prompt-based 攻击的根本区别。
2.3 Multi-turn jailbreaking
多轮越狱不是靠一条 prompt 直接突破,而是通过数轮对话逐步:
- 建立虚构语境
- 先问无害子问题
- 逐步分解危险任务
- 利用前文上下文强化模型顺从性
在系统带有 memory、tool use 或 planner 时,多轮攻击往往比单轮更危险。
2.4 Automated black-box jailbreaks
课程里特别强调了 automated black-box attacks 的现实意义,因为真实闭源模型通常不给梯度、不给参数,但会给:
- 公开 API
- 可观察的 refusal / compliance 信号
- 足够多的重试机会
这使得攻击者可以把模型当作 oracle,用另一个模型或搜索算法不断优化 prompt。
图示来源:Tufts EE141 Trusted AI, Lecture 6, Slide 44。图像说明:时间线把 token-level 与 prompt-level 的代表性攻击方法放到同一坐标里。知识说明:攻击正在从手工模板走向程序化搜索,这意味着防御必须按“攻击生成机制”而不是“某个热词模板”设计。
图示来源:Tufts EE141 Trusted AI, Lecture 6, Slide 49。图像说明:图中用“Engineer the prompt -> model -> response”的闭环展示自动化黑盒搜索。知识说明:闭源 API 没有梯度并不等于安全,只要攻击者能观察成功/失败信号,就能搜索输入。
图示来源:Tufts EE141 Trusted AI, Lecture 6, Slide 55。图像说明:页面对比了 single-turn 和 multi-turn jailbreaking 的对话结构。知识说明:多轮越狱的危险不在于每句话都明显有害,而在于上下文会逐渐把模型推入错误策略区域。
图示来源:Tufts EE141 Trusted AI, Lecture 6, Slide 58。图像说明:页面用同一个危险 prompt 对比 Qwen3(weak-yet-unaligned)和 Claude 3.7(strong-yet-aligned)的输出差异。知识说明:分解攻击利用的是模型能力与对齐之间的缝隙——能力足够但对齐不足的模型更容易被拆解式 prompt 绕过。
3. 分层防御与攻击升级
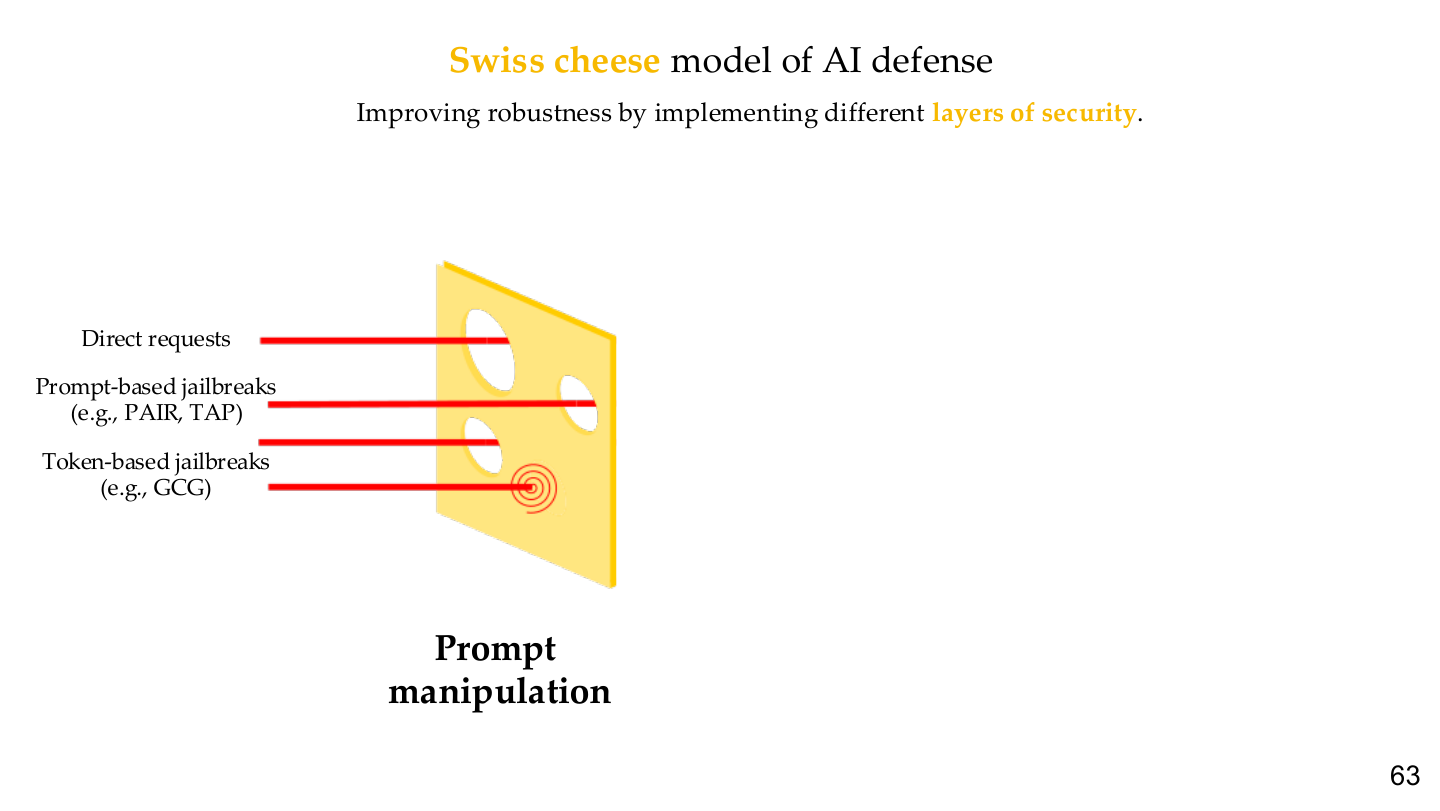
图示来源:Tufts EE141 Trusted AI, Lecture 6, Slide 63。图像说明:图中把直接请求、prompt-based jailbreak 与 token-based jailbreak 画成穿透不同“孔洞”的攻击路径。知识说明:它强调越狱防御不可能由单层 guardrail 完成,而需要多层、不同失效模式的控制叠加。
这张图的价值在于它纠正了一个常见误区:很多团队把安全寄托在单个 moderation model 或 system prompt 上,但真正有效的防御应当像瑞士奶酪模型一样分层。

图示来源:Tufts EE141 Trusted AI, Lecture 6, Slide 61。图像说明:图中把 back-box、white-box、attack mitigation、compatibility 和效率问题放进同一页。知识说明:防御不只是“让成功率下降”,还必须考虑对正常能力、部署成本和攻击迁移性的影响。
4. 攻击方法分类
4.1 代表性 prompt-based 攻击
| 类型 | 思路 | 风险点 |
|---|---|---|
| 角色扮演 | 让模型进入“另一个人格” | 借上下文伪装绕过 policy |
| 分解式诱导 | 把危险任务拆成多个看似无害的步骤 | 让每一步都不触发拒绝 |
| 编码/转换攻击 | 用翻译、编码、抽象格式表达有害意图 | 逃避表层过滤 |
| indirect prompt injection | 把恶意指令嵌入网页、文档、邮件 | 劫持 agent 或 RAG 系统 |
4.2 Token / optimization-based 攻击
| 方法 | 优点 | 局限 |
|---|---|---|
| GCG | 可系统逼近最坏输入 | 对真实闭源 API 成本高 |
| evolutionary search | 不依赖梯度 | 搜索成本高、可迁移性不稳定 |
| attack transfer | 可在替身模型上优化后迁移 | 迁移成功率依赖模型相似性 |
4.3 物理或跨模态扩展
虽然本页聚焦文本越狱,但多模态系统还会出现:
- 图像中嵌入恶意指令
- OCR / vision encoder 误读导致的 prompt 污染
- 工具输入文件中的隐式控制文本
对应专题可参见 视觉指令注入。
5. 越狱为什么难防
5.1 政策边界不是形式化约束
对齐训练让模型“更倾向于拒绝”,但并没有把所有危险请求变成不可满足的逻辑命题。只要请求分布稍微移动,模型就可能把原本应拒绝的问题解释成允许回答的任务。
5.2 真实攻击者可以无限重试
在安全里,99% 的成功率往往仍然等于失败,因为攻击者可以不断重试。课程在 prompt injection 部分反复强调:概率式模型一旦暴露在不受限的交互通道中,就会放大 retry advantage。
5.3 系统能力越强,越狱后果越重
如果模型只有聊天能力,越狱可能只是输出不当文本;如果模型还能:
- 读邮箱
- 搜索内部文档
- 调数据库
- 执行代码
- 发送消息
那么越狱就会迅速变成系统级 compromise。
6. 防御思路
6.1 训练阶段防御
训练阶段的主要思路包括:
- safety fine-tuning
- 对抗式数据增强
- refusal policy 优化
- Constitutional AI / rule-based critique
- 基于 jailbreak benchmark 的持续回归
这些方法能提升平均防御能力,但很难单独构成强安全边界。
6.2 推理阶段防御
推理阶段通常需要多层防线:
flowchart LR
A[User / Retrieved Content] --> B[Input guard]
B --> C[Policy / risk classifier]
C --> D[Main model]
D --> E[Output guard]
E --> F[Tool gate / human approval]
每层都有不同职责:
- Input guard:识别 injection pattern、编码变换和异常上下文
- Risk classifier:判断任务类别与风险级别
- Output guard:检测危险内容、policy leak、secret leak
- Tool gate:高风险动作需人工确认或最小权限执行
6.3 Layered defense 的现实含义
课程中的 layered defense 不是泛泛而谈,它具体意味着:
- 不把 refusal 完全交给主模型
- 不把 tools 直接暴露给不可信输入
- 对高风险能力单独做 capability gating
- 把 red teaming 做成持续回归,而不是上线前一次性测试
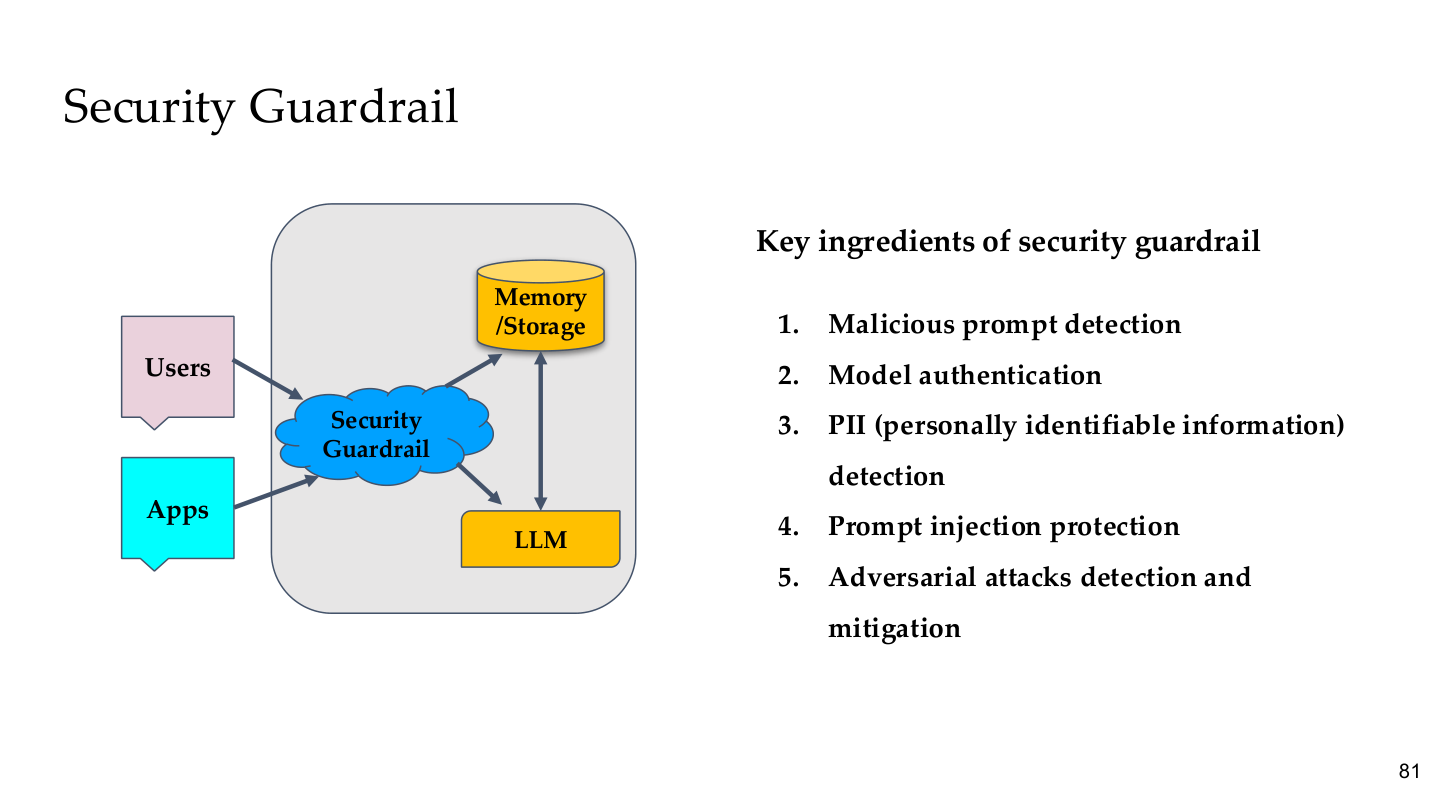
图示来源:Tufts EE141 Trusted AI, Lecture 6, Slide 81。图像说明:页面把 Security Guardrail 画在 Users/Apps 与 LLM/Memory 之间,列出五个核心组件。知识说明:护栏不是模型内部的一个开关,而是独立于模型的系统层组件——这意味着即使模型本身被绕过,外部护栏仍然可以拦截。
7. 越狱与红队、对齐、治理的关系
7.1 与红队测试的关系
越狱评测是 red teaming 的关键组成部分,但并不等同于红队本身。红队还会覆盖:
- system prompt 泄露
- tool misuse
- secret exfiltration
- memory contamination
- chained attack paths
参见 红队测试。
7.2 与对齐的关系
越狱是“行为边界”的表征,对齐是“目标与偏好建模”的更大问题。越狱成功通常说明:
- reward model 没有覆盖到该类输入分布
- system policy 与自然语言语境存在解释缝隙
- refusal 机制未与 tools、retrieval 和 execution path 一起设计
参见 AI对齐。
7.3 与工程系统的关系
真正危险的不是一个被越狱的聊天窗口,而是一个被越狱且连接了系统资源的 agent。对应工程问题参见:
与其他主题的关系
参考文献
- Tufts EE141 Trusted AI Course Slides, LLM Security Lecture, Spring 2026.
- Zou et al., "Universal and Transferable Adversarial Attacks on Aligned Language Models", 2023.
- Perez et al., "Red Teaming Language Models with Language Models", EMNLP 2022.
- Wei et al., "Jailbroken: How Does LLM Safety Training Fail?", NeurIPS 2024 Workshop.
- OWASP, "Top 10 for Large Language Model Applications", 2025.
- Willison, "Prompt Injection Explained", 2023.