AI 安全综述
AI 安全并不是单一问题,而是一组跨训练、推理、部署和治理阶段的风险控制任务。更准确的理解方式,不是把它缩成“防对抗样本”或“加一个安全过滤器”,而是把可信 AI 拆成能力、风险、控制与治理四个层次。
本文作为 AI安全与可信性 板块的总览页,只负责建立主线:统一 threat model、四类风险面和阅读地图。工程控制、权限隔离、日志审计和系统边界等细节不在这里展开,而是交给 AI工程安全与合规 与 LLM与Agent系统安全。
1. 什么是可信 AI
可信 AI 可以理解为:模型既有能力完成任务,又不会在可预见的攻击、误用和部署环境中失控,同时能被解释、审计和治理。
graph TD
A[可信 AI] --> B[能力 Capability]
A --> C[风险 Risk]
A --> D[控制 Control]
A --> E[治理 Governance]
B --> B1[任务性能]
B --> B2[泛化能力]
C --> C1[对抗攻击]
C --> C2[后门与投毒]
C --> C3[隐私泄露]
C --> C4[越狱与提示注入]
C --> C5[系统级失效]
D --> D1[训练防御]
D --> D2[监控与审计]
D --> D3[隔离与最小权限]
D --> D4[红队与回归]
E --> E1[模型卡片]
E --> E2[法规标准]
E --> E3[责任分工]

图示来源:Tufts EE141 Trusted AI, Lecture 1, Slide 74。图像说明:新闻标题、数据泄露事件和白宫政策页面被并置,强调可信 AI 同时受技术能力与制度约束影响。知识说明:这也是本页采用 capability-risk-control-governance 四层框架的原因。
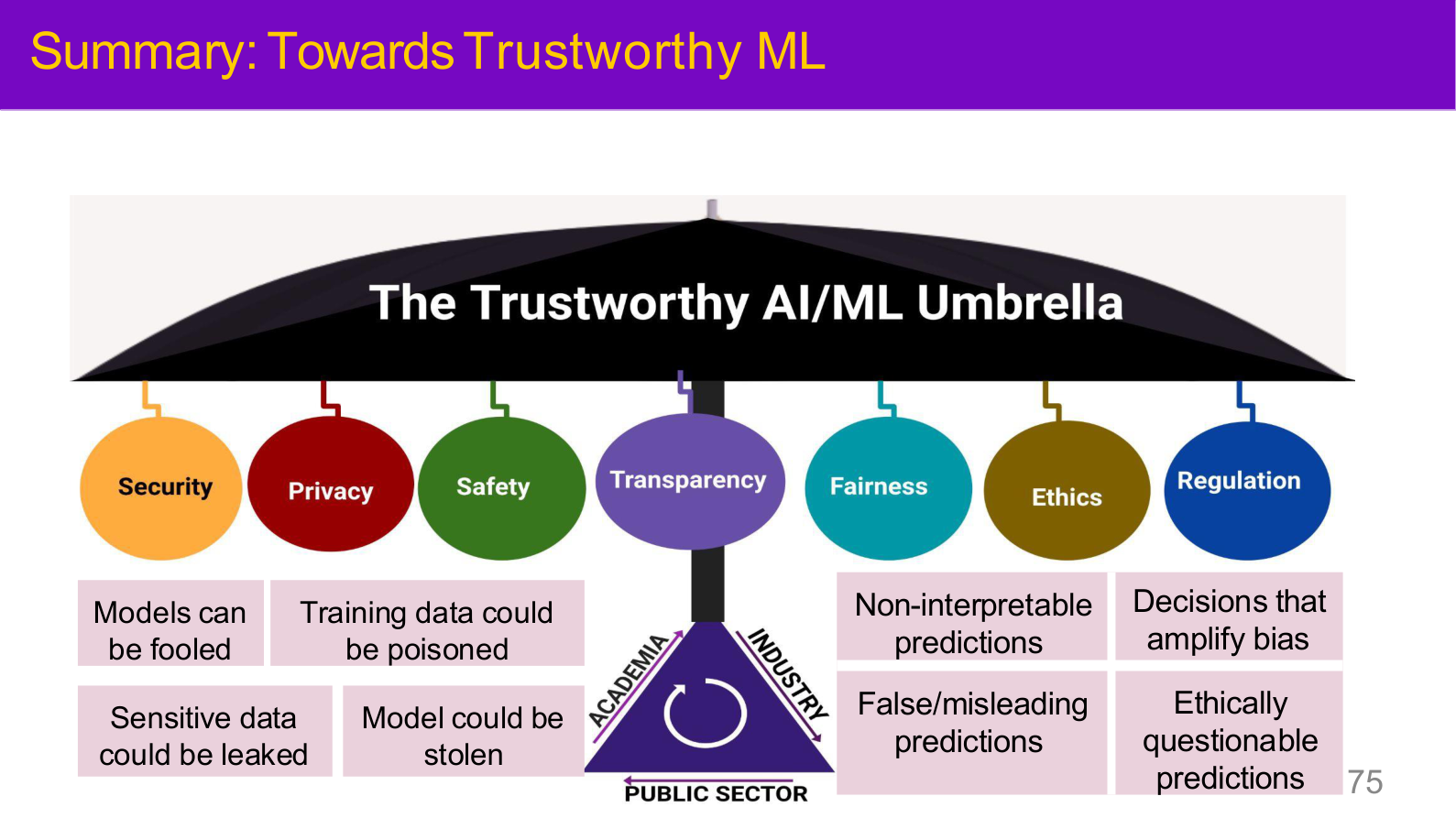
图示来源:Tufts EE141 Trusted AI, Lecture 1, Slide 75。图像说明:页面用伞形图把 Security、Privacy、Safety、Transparency、Fairness、Ethics、Regulation 七个柱子并列展示。知识说明:这张图是理解整个 AI 安全领域的起点——安全不只是”不被攻击”,而是覆盖隐私、公平、透明和治理的系统性问题。
1.1 可信不等于”绝对安全”
AI 系统通常在概率式组件上运行,因此不存在传统密码学意义上的“绝对无漏洞”。更现实的目标是:
- 明确威胁模型,而不是模糊地讨论“强安全”
- 为高风险场景建立分层控制,而不是只寄希望于单点模型能力
- 接受精度、可用性、成本与风险之间的 trade-off
- 用持续评估和 incident response,而不是一次性验收
1.2 与传统软件安全的区别
AI 安全比传统软件安全多出三类难点:
| 维度 | 传统软件 | AI 系统 |
|---|---|---|
| 行为定义 | 逻辑规则显式编码 | 由训练数据和参数隐式决定 |
| 失败模式 | 通常是确定性 bug | 常见为概率性失效、分布偏移或误对齐 |
| 攻击面 | 输入、协议、权限 | 额外包括数据、表示、损失函数、推理上下文 |
| 修复方式 | 补丁、权限收敛 | 还可能需要再训练、重新评测和数据治理 |
2. 最小 ML/DL 背景
本章只保留与安全相关的最小 ML/DL 背景,不重复教材式介绍。更完整的基础内容参见 机器学习基础 和 监督学习。
2.1 为什么学习器会暴露攻击面
监督学习本质上是在训练集经验风险上做最优化:
这里的每个元素都可能成为攻击面:
2.2 深度模型为何脆弱
深度模型的脆弱性通常来自以下组合效应:
- 高维输入空间中,局部线性近似就足以产生显著输出变化
- 训练目标与真实部署目标并不完全一致
- 训练分布与部署分布存在 covariate shift
- 模型经常学到“捷径”而不是真实因果机制
这也是为什么鲁棒性、可解释性、隐私和对齐会彼此耦合,而不是互不相干的专题。
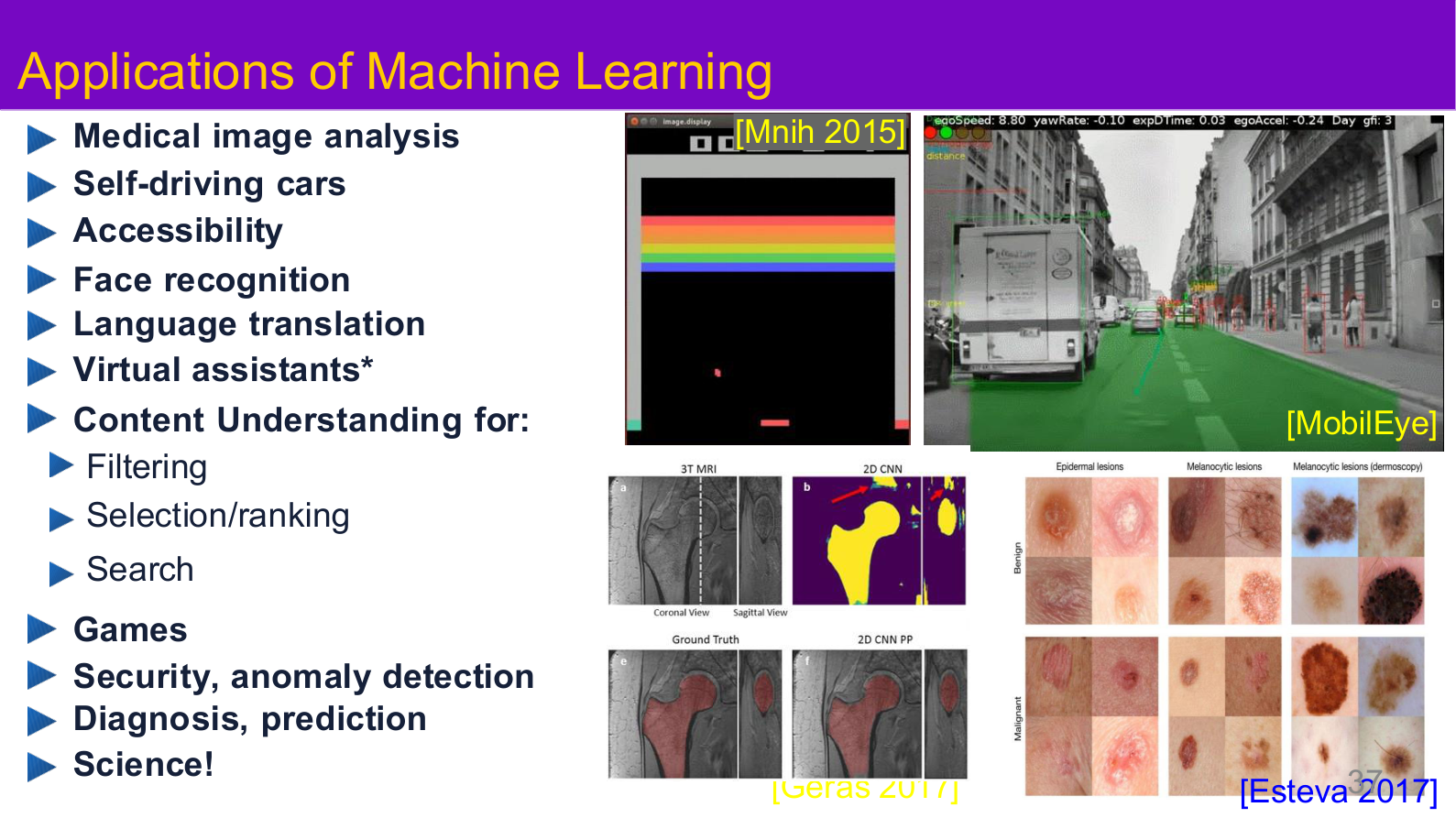
图示来源:Tufts EE141 Trusted AI, Lecture 1, Slide 37。图像说明:这一页把机器学习应用从医学影像、自动驾驶到内容理解和科学计算放在同一视图里。知识说明:攻击面之所以复杂,不是因为算法本身神秘,而是因为同一类学习器会进入完全不同、风险容忍度也完全不同的场景。

图示来源:Tufts EE141 Trusted AI, Lecture 1, Slide 46。图像说明:页面把“能做到什么”和“还做不到什么”并列展示。知识说明:可信 AI 的第一步不是盲目加控制,而是先承认模型能力边界,避免把尚不可靠的能力直接放进高风险闭环。
3. 统一威胁模型
3.1 按系统生命周期划分
| 阶段 | 主要问题 | 典型案例 |
|---|---|---|
| 数据收集与训练 | 数据投毒、后门、版权与隐私风险 | 恶意样本注入、pretrained model 供应链污染 |
| 模型评估 | 基准不完整、能力外溢、危险能力未披露 | 只测平均精度,不测高风险行为 |
| 推理接口 | 对抗样本、模型窃取、成员推理 | 黑盒查询、API 滥用、evasion |
| LLM 应用编排 | prompt injection、越狱、工具滥用 | 间接注入、绕过 refusal、secret exfiltration |
| 基础设施与运维 | 侧信道、日志泄露、权限配置错误 | multi-tenant accelerator、Redis/缓存事故 |
3.2 按攻击者知识与能力划分
| 维度 | 取值 | 说明 |
|---|---|---|
| Knowledge | white-box / gray-box / black-box | 攻击者了解多少模型内部信息 |
| Capability | training-time / inference-time / system-level | 能否触及训练链路、推理接口或基础设施 |
| Goal | integrity / privacy / availability / misuse | 破坏正确性、窃取信息、耗尽资源或诱导滥用 |
这种 threat model 视角,可以把图像模型攻击、LLM 越狱和系统级安全放到同一张表里,而不再把它们视为完全不同的学科。
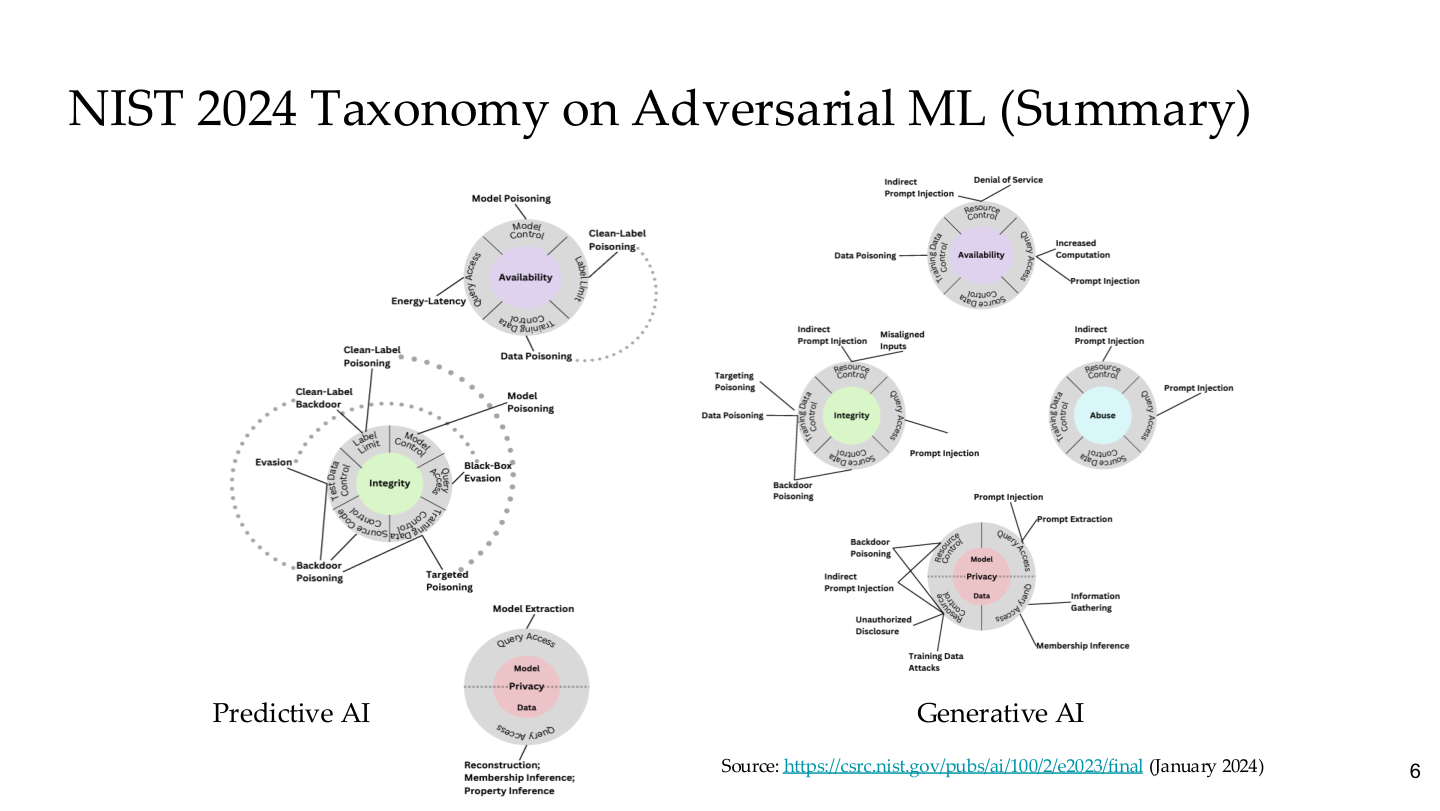
图示来源:Tufts EE141 Trusted AI, Lecture 6, Slide 6。图像说明:页面将 Predictive AI 和 Generative AI 的攻击面分别用圆形拓扑图展开,覆盖可用性、完整性和隐私三个维度。知识说明:传统 ML 攻击和 LLM 攻击看似属于不同领域,但 NIST 把它们放在同一分类框架下——对抗安全是一个统一学科,不是两个孤立问题。
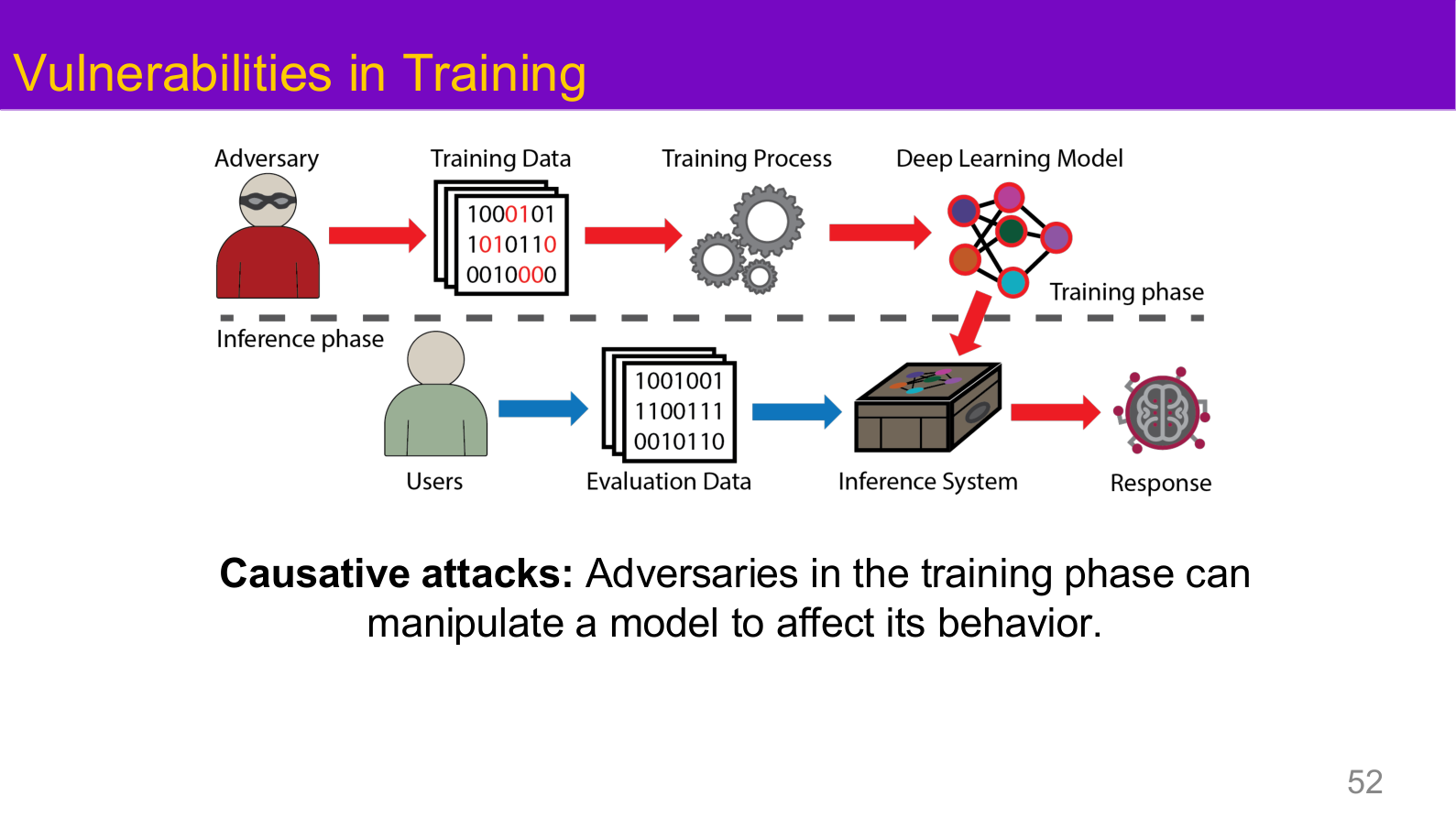
图示来源:Tufts EE141 Trusted AI, Lecture 1, Slide 52。图像说明:页面在标准 ML pipeline 上标红攻击者注入训练数据的路径,展示 causative attack 如何在训练阶段污染模型。知识说明:所有后门攻击和数据投毒都可以归入这张图所描述的"训练阶段攻击面",理解这一点是理解 AI 安全分层防御的前提。
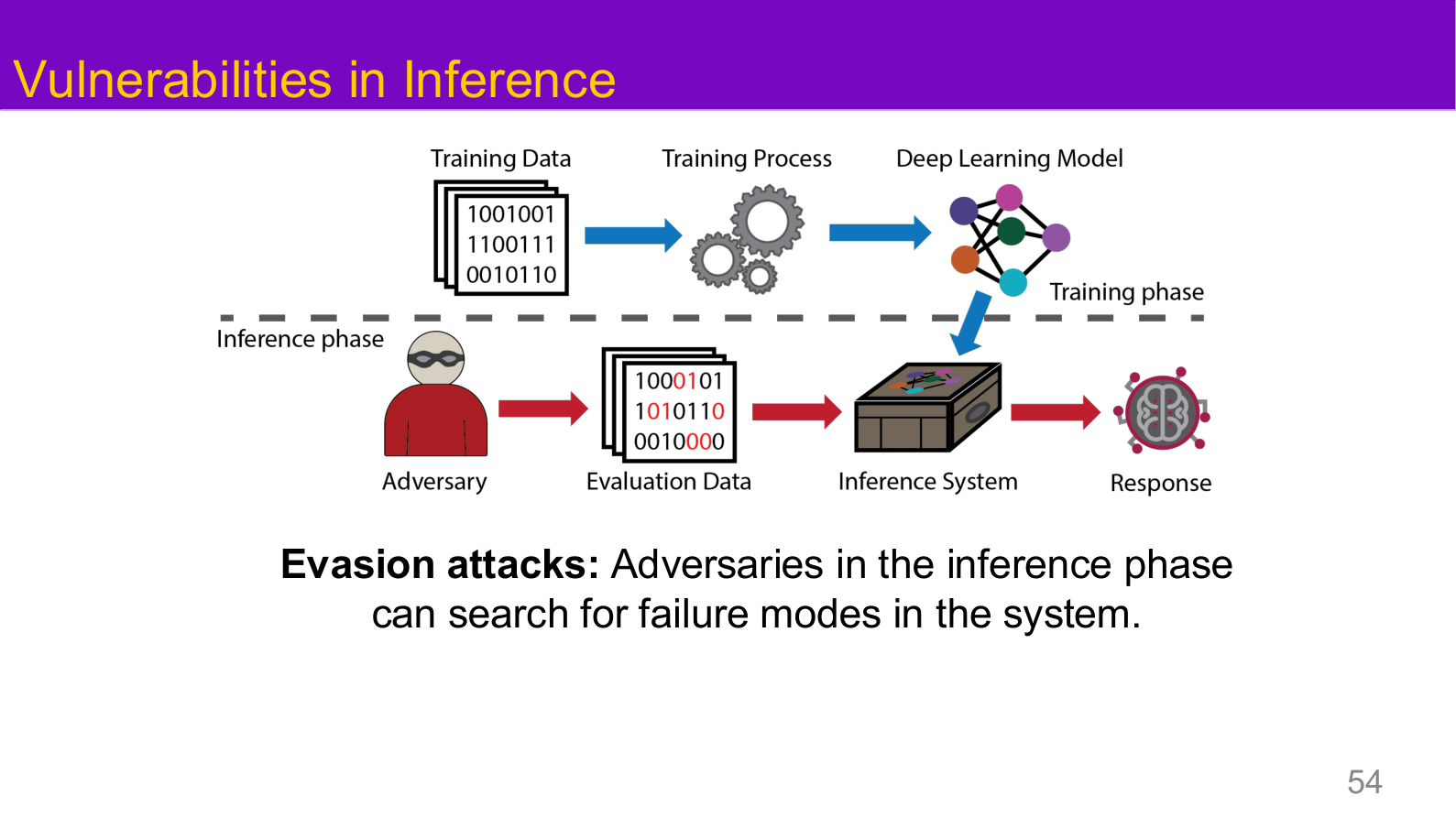
图示来源:Tufts EE141 Trusted AI, Lecture 1, Slide 54。图像说明:页面把攻击者放在推理端,展示 evasion attack 如何在不改变模型本身的前提下操纵输入以触发错误输出。知识说明:对抗样本、越狱和 prompt injection 都属于推理阶段攻击,与训练阶段攻击形成互补的威胁模型。
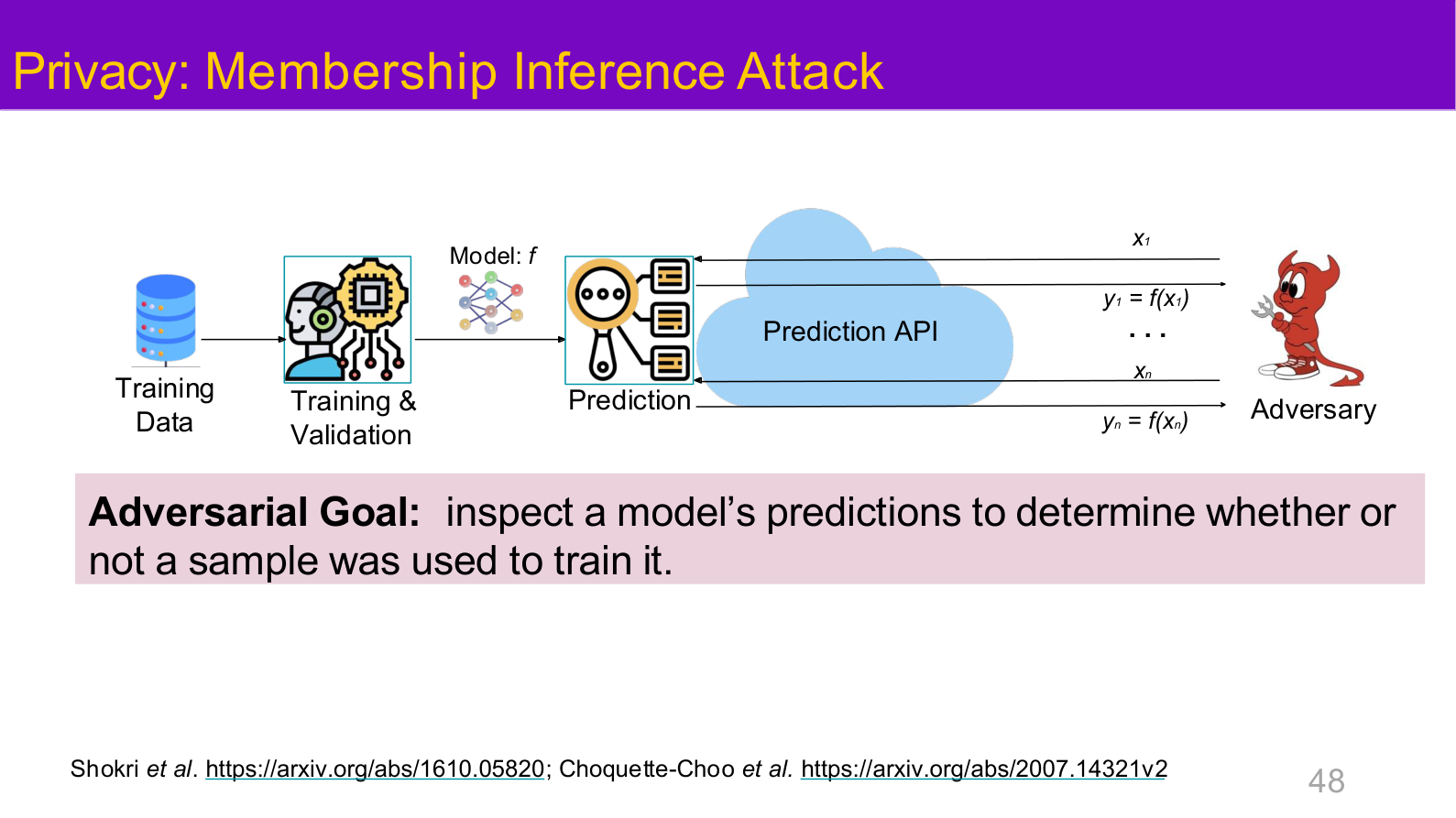
图示来源:Tufts EE141 Trusted AI, Lecture 1, Slide 48。图像说明:总览页把 membership inference attack 作为“隐私风险”的代表案例单独拎出。知识说明:隐私问题不是与主线无关的附录,而是可信 AI 风险模型中的一级攻击面。
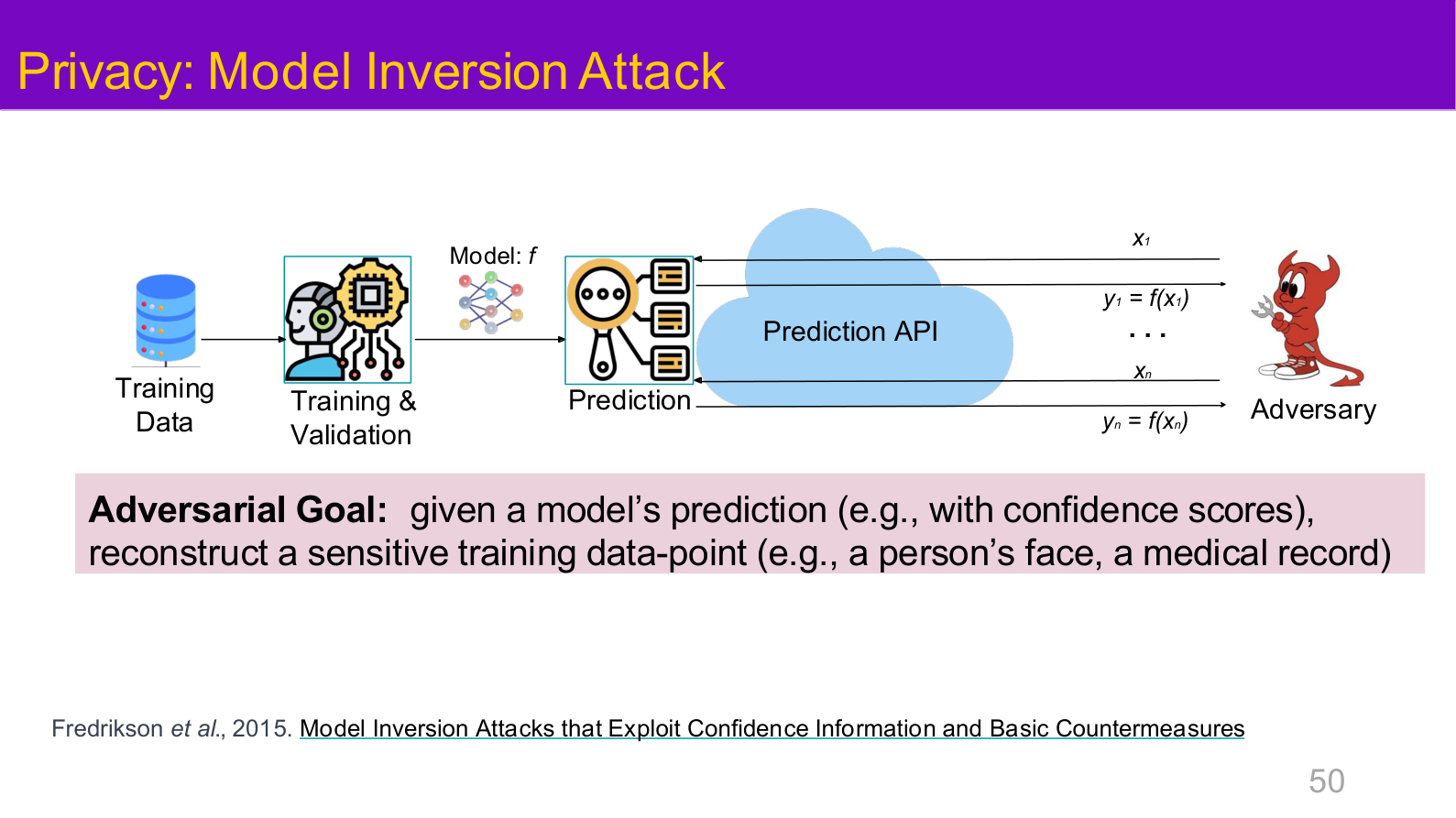
图示来源:Tufts EE141 Trusted AI, Lecture 1, Slide 50。图像说明:页面直接把 model inversion attack 置于可信 AI 总览之中。知识说明:这说明“模型是否会泄露训练信息”应被视为与正确率同等重要的系统属性,而不是上线后的附属合规问题。
4. 主要风险面
4.1 对抗鲁棒性
对抗攻击通常通过约束扰动大小来改变模型预测:
关键问题包括:
- 白盒梯度攻击如何构造最坏扰动
- 黑盒查询攻击如何依赖 transferability
- 物理世界攻击如何跨相机、光照和视角成立
- 防御是否真的提高鲁棒性,还是只造成 gradient obfuscation
对应专题页:
4.2 后门与投毒
后门攻击不是在推理时修改输入,而是在训练阶段植入“捷径特征”。模型在正常输入上看似正常,但当触发器出现时会强制输出攻击者指定的标签。
与普通对抗攻击相比,后门问题更贴近供应链风险,因为攻击可能发生在:
- 外包训练
- 第三方预训练模型
- 联邦学习客户端
- 数据标注和清洗流程
对应专题页: 后门攻击
4.3 隐私与信息泄露
AI 模型可能通过输出分布暴露训练数据的存在、属性甚至原文。课程中把这类风险拆成四层:
- 成员推理:某条样本是否在训练集中
- 属性/特征推理:原本未显式给出的敏感属性能否被推断
- 模型逆向:是否能从输出重建样本
- 模型窃取与数据抽取:能否复制模型行为或恢复训练片段
对应专题页: 隐私攻击
4.4 LLM 安全
LLM 安全与传统分类模型不同,因为攻击面不止是数值输入,还包括:
- system prompt 与用户 prompt 的指令竞争
- 检索文档、网页、邮件等“间接输入”
- tool calling、memory、plugin、code execution 等外部能力
- refusal policy、reward model 与 guardrail 之间的空隙
对应专题页:
4.5 可解释性与对齐
可解释性和对齐在很多工程团队里常被拆开,但在可信 AI 里它们有共同目标:确认模型为什么这样做,以及它是否在做我们真正想让它做的事。
这两个方向分别回答:
- 可解释性:模型的证据、表示与内部机制是什么
- 对齐:模型的目标、偏好与安全边界是否符合人类意图
对应专题页:
5. 防御不是单点技术,而是分层系统
安全控制必须分层。单一模型、单一过滤器或单一 benchmark 都不够。
flowchart LR
A[数据与供应链] --> B[模型训练]
B --> C[评估与红队]
C --> D[应用编排]
D --> E[权限与隔离]
E --> F[监控与响应]
A1[数据治理/来源追踪] --> A
B1[鲁棒训练/DP/对齐] --> B
C1[capability eval/jailbreak eval] --> C
D1[input-output guardrails] --> D
E1[least privilege/secret isolation] --> E
F1[audit logs/regression/incident review] --> F
一个成熟的安全方案通常包括:
- 训练前:数据来源控制、模型供应链审查
- 训练中:鲁棒训练、隐私保护、alignment tuning
- 上线前:红队测试、危险能力评测、回归基线
- 上线后:日志审计、速率限制、异常检测、incident response
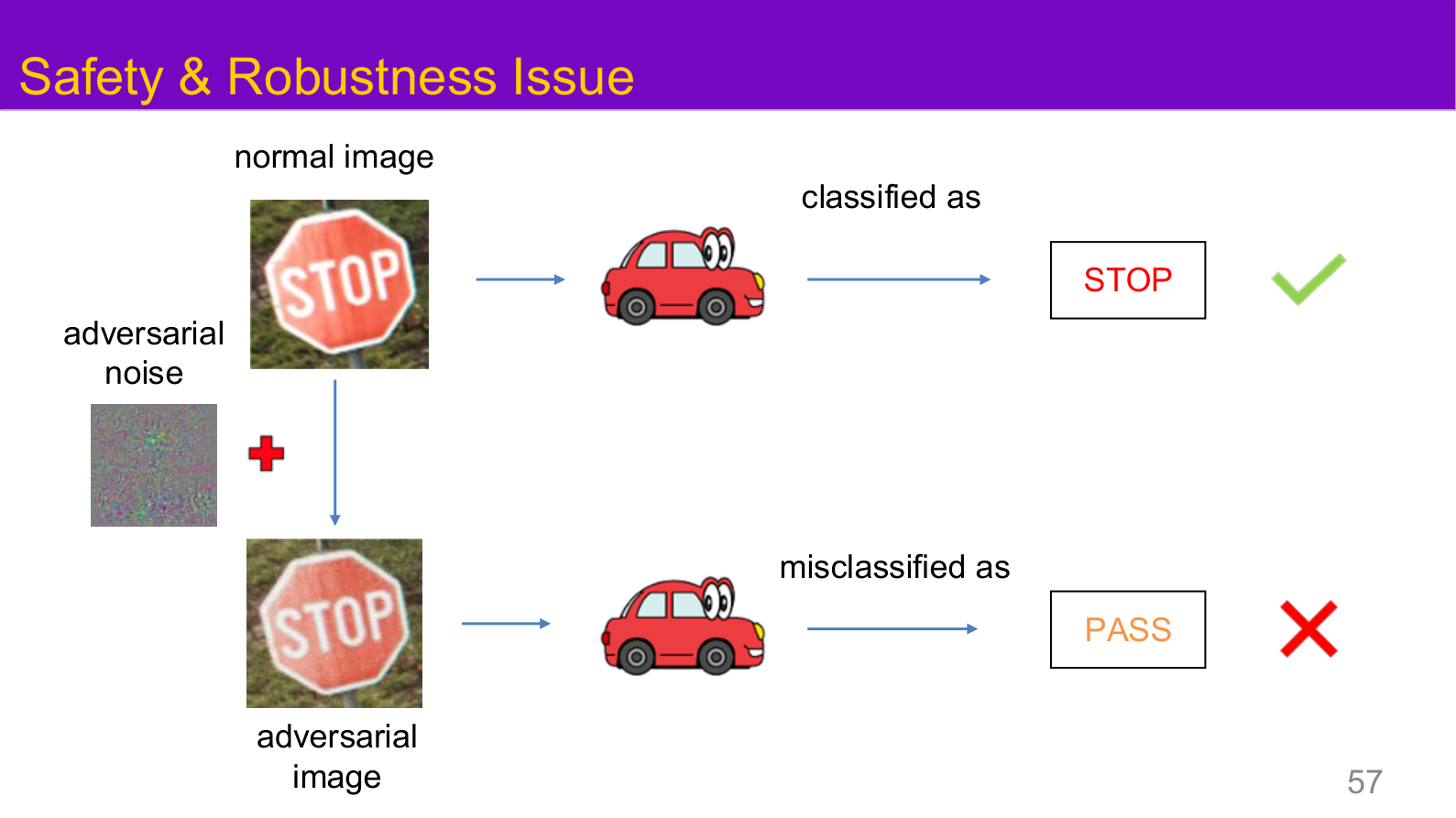
图示来源:Tufts EE141 Trusted AI, Lecture 1, Slide 57。图像说明:对比图展示同一视觉场景在正常输入和对抗输入下会给出完全不同的系统结论。知识说明:只看平均精度无法捕捉这类失效,系统必须显式引入鲁棒性测试与失效模式分析。
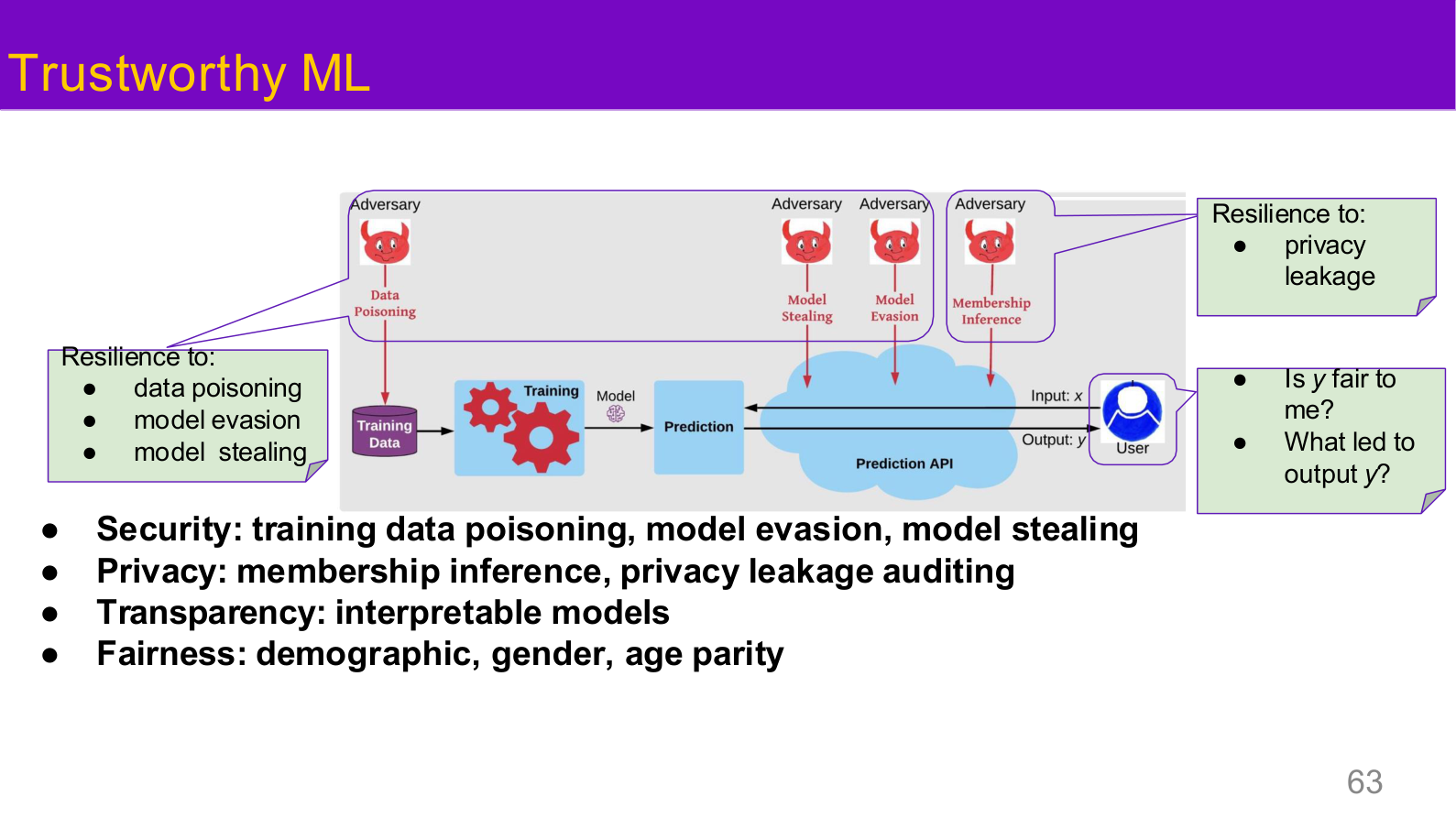
图示来源:Tufts EE141 Trusted AI, Lecture 1, Slide 63。图像说明:页面把训练数据投毒、模型逃逸、模型窃取、隐私泄露、公平性与透明度放进一个统一风险图里。知识说明:可信 AI 不是一个单项指标,而是多类失败模式共同构成的组合属性。

图示来源:Tufts EE141 Trusted AI, Lecture 1, Slide 66。图像说明:页面把数据收集、算法设计、模型实现、系统测试和部署串成一条责任链,并配以真实事故与责任归属问题。知识说明:治理不是写一条原则,而是把每个阶段的责任和失败后果明确到组织流程中。
6. 阅读路径与知识地图
如果你更关心:
- 训练和推理阶段的正确性破坏:先读 对抗攻击与防御、FGSM与PGD、后门攻击
- 信息泄露与删除:先读 隐私攻击
- 大模型行为绕过与系统边界:先读 LLM越狱、红队测试、LLM与Agent系统安全
- 解释、监督与治理:先读 可解释性与鲁棒性、AI对齐、AI伦理与治理
与其他主题的关系
- 与机器学习基础的关系:参见 机器学习基础 和 监督学习
- 与工程安全的关系:参见 AI工程安全与合规 和 LLM与Agent系统安全
- 与专题攻击面的关系:参见 对抗攻击与防御、后门攻击、隐私攻击
- 与可解释性和对齐的关系:参见 可解释性与鲁棒性 与 AI对齐
参考文献
- Tufts EE141 Trusted AI Course Slides, Spring 2026.
- Goodfellow et al., "Explaining and Harnessing Adversarial Examples", ICLR 2015.
- Amodei et al., "Concrete Problems in AI Safety", arXiv, 2016.
- Carlini et al., "Extracting Training Data from Large Language Models", USENIX Security 2021.
- Mitchell et al., "Model Cards for Model Reporting", FAT* 2019.
- OWASP, "Top 10 for Large Language Model Applications", 2025.