LLM与Agent系统安全
当模型具备工具调用、检索、代码执行和长期记忆能力后,安全问题就不再只是“模型会不会说错话”,而是“它能否跨越系统边界做错事”。这里把 LLM 安全和硬件/基础设施安全放在同一张地图里:外部攻击、内部故障、共享资源泄露和权限设计,最终都会影响 AI 系统的可信边界。
本文作为 AI_Engineering/Safety_Governance 下的 canonical 页面,覆盖 prompt injection 的系统含义、tool boundary、secret 管理、side-channel、multi-tenant accelerator、审计与 incident response。
1. 系统视角下的 AI 安全
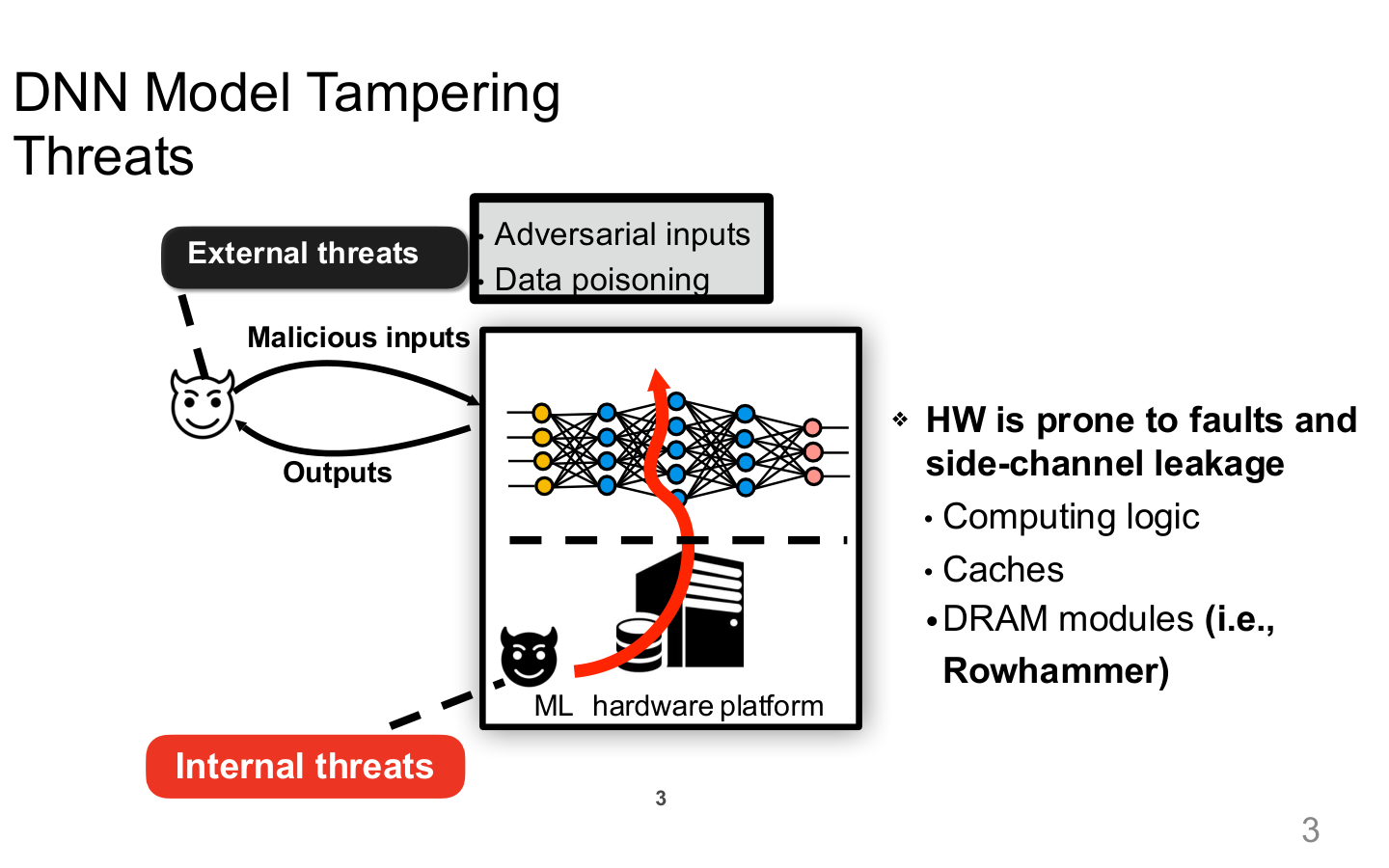
图示来源:Tufts EE141 Trusted AI, Lecture 7, Slide 3。图像说明:图中把恶意输入、数据投毒、内部硬件平台和侧信道泄露放在同一“DNN model tampering threats” 视图中。知识说明:这提醒我们,AI 安全边界并不止于模型 API,还包括训练链路、执行硬件和共享系统资源。
1.1 典型边界
AI/Agent 系统一般至少有五层边界:
| 边界 | 典型对象 | 风险 |
|---|---|---|
| Prompt boundary | system / user / retrieved content | injection、policy override |
| Tool boundary | shell、database、browser、email | 权限提升、误执行 |
| Data boundary | docs、memory、cache、logs | secret exfiltration、PII 泄露 |
| Runtime boundary | sandbox、container、VM、accelerator | 越权访问、持久化副作用 |
| Org boundary | 人员、审批、变更流程 | 责任不清、审计缺失 |
1.2 为什么“只是聊天机器人”并不安全
只要系统接入以下任一能力,风险级别就会迅速上升:
- 外部检索
- 内网知识库
- 文件系统
- 代码执行
- 高权限 API
- 自动发送消息或创建工单
因此 Agent 安全设计要从“能力组合”而不是“模型名称”出发。
2. Prompt injection 的系统含义

图示来源:Tufts EE141 Trusted AI, Lecture 7, Slide 39。图像说明:课程页强调模型无法可靠地区分 trusted 与 untrusted input,并提出 privileged / unprivileged 双模型模式。知识说明:这张图的重点不是某一句恶意 prompt,而是“控制流与数据流不能混在同一信任域里”。
2.1 单模型无法成为信任边界
如果一个模型既读取不可信输入,又持有高权限工具,那么 prompt injection 就会从语言攻击升级为系统 compromise。问题根源不是模型“不够聪明”,而是 trusted / untrusted data 被放在同一执行上下文里。
2.2 双通道或双模型模式
一种更稳健的模式是:
- privileged component:看得到高权限工具和可信策略,但不直接读取不可信原始输入
- unprivileged component:处理用户输入和外部内容,但没有危险工具权限
这并不意味着一定要两个 LLM,也可以是:
- 一个 policy engine + 一个 LLM
- 一个 parser / broker + 一个执行器
- 一个审批工作流 + 一个自动化 agent
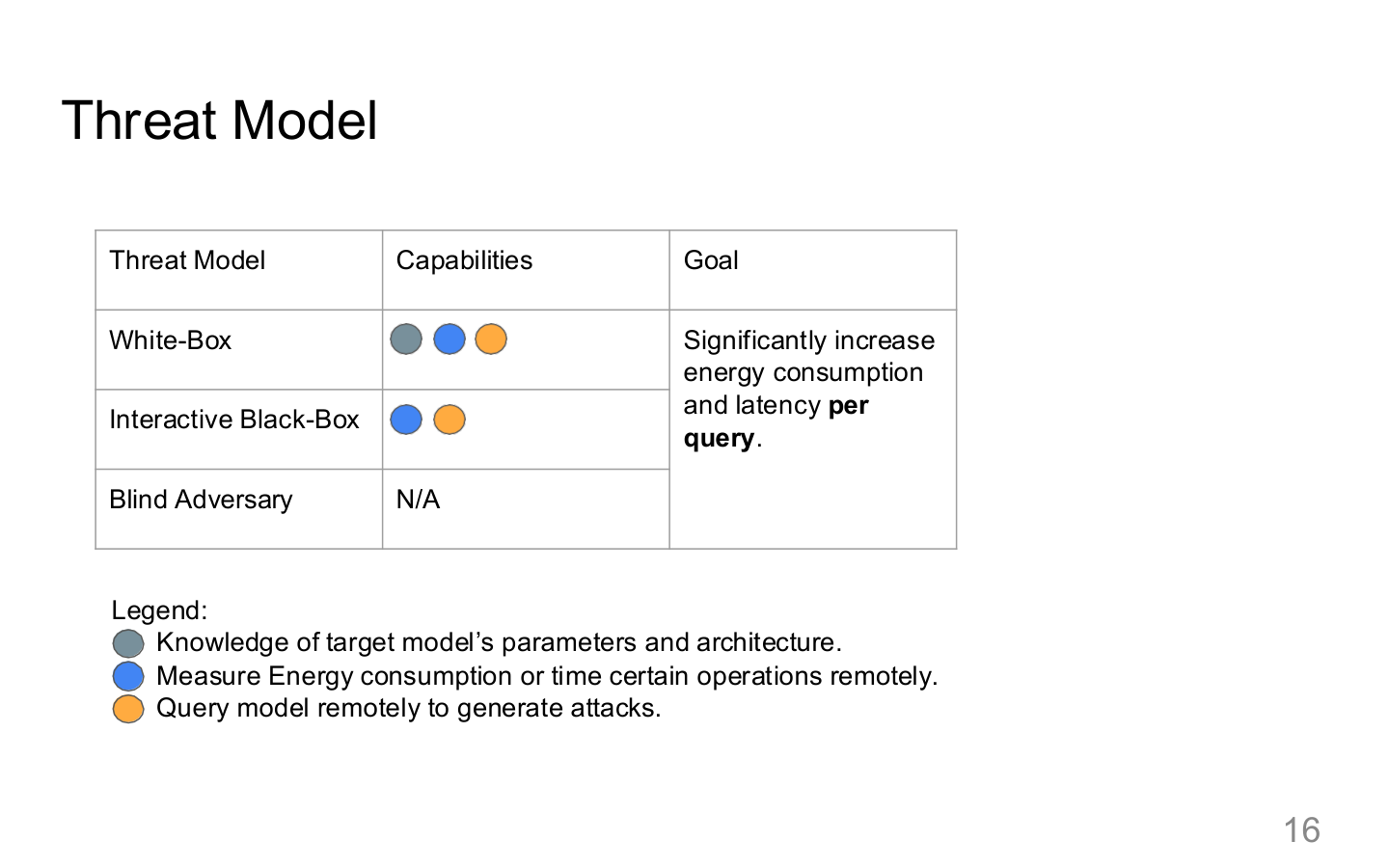
图示来源:Tufts EE141 Trusted AI, Lecture 7, Slide 16。图像说明:图中把威胁模型拆成外部与内部两类路径。知识说明:Agent 系统安全的第一步不是写规则,而是把输入、执行器、硬件和共享资源都纳入同一威胁模型。
3. Tool security:最危险的不是回答,而是动作
3.1 Tool broker 的必要性
所有外部工具都应通过 broker 或 policy layer 暴露,而不是直接挂给模型。broker 至少要做:
- capability allowlist
- 参数 schema 校验
- 敏感字段过滤
- dry-run / preview
- 人工审批
3.2 参数级限制
“允许访问数据库”这种说法没有意义,真正需要控制的是:
- 是否只读
- 是否只允许特定表
- 是否只允许带租户过滤的查询
- 是否禁止跨网段或外连
同理,“允许执行 shell”也必须细化到:
- 可执行哪些命令
- 可访问哪些目录
- 是否允许网络
- 是否允许生成或修改文件
4. Secret 管理与数据外泄
4.1 常见外泄路径
secret 并不只会从变量或配置文件泄露,还可能从:
- 检索文档
- prompt template
- tool output
- traceback / error message
- 日志与监控平台
4.2 基本原则
- 不把 secret 直接拼进 prompt
- 让工具在最小权限域内代理敏感操作
- 对 outbound request 做域名和目标限制
- 对返回给模型的工具输出做 redaction
4.3 Blast radius 设计
即便某个 agent 被注入成功,也要确保其损害范围可控:
- 一个 agent 只拿到单租户数据
- 一个 token 只对应单类能力
- 一个 tool 只对应单个 narrow action
5. 硬件与基础设施安全
AI 基础设施风险大致可以拆成两类:fault attacks 和 side-channel leakage。对很多软件团队来说,这部分容易被忽视,但在共享加速器或多租户环境里并不遥远。
5.1 Fault attacks
代表性例子包括:
- bit-flip attack
- rowhammer
- voltage / timing fault injection

图示来源:Tufts EE141 Trusted AI, Lecture 7, Slide 6。图像说明:页面用位翻转和参数更新关系解释 BFA。知识说明:模型参数并不是“静态真值”,在特定硬件条件下它们同样可能成为攻击面。

图示来源:Tufts EE141 Trusted AI, Lecture 7, Slide 12。图像说明:图中展示相邻 DRAM 行之间的干扰如何导致位翻转。知识说明:当模型部署在共享硬件上时,底层内存故障会直接传导到推理结果。
它们可能改变模型参数、扰乱中间激活,甚至导致推理结果被系统性操纵。
5.2 Side-channel leakage
共享硬件资源会暴露:
- cache access pattern
- DRAM timing
- accelerator power / voltage signal
- FPGA / TPU / GPU 上的资源争用信息
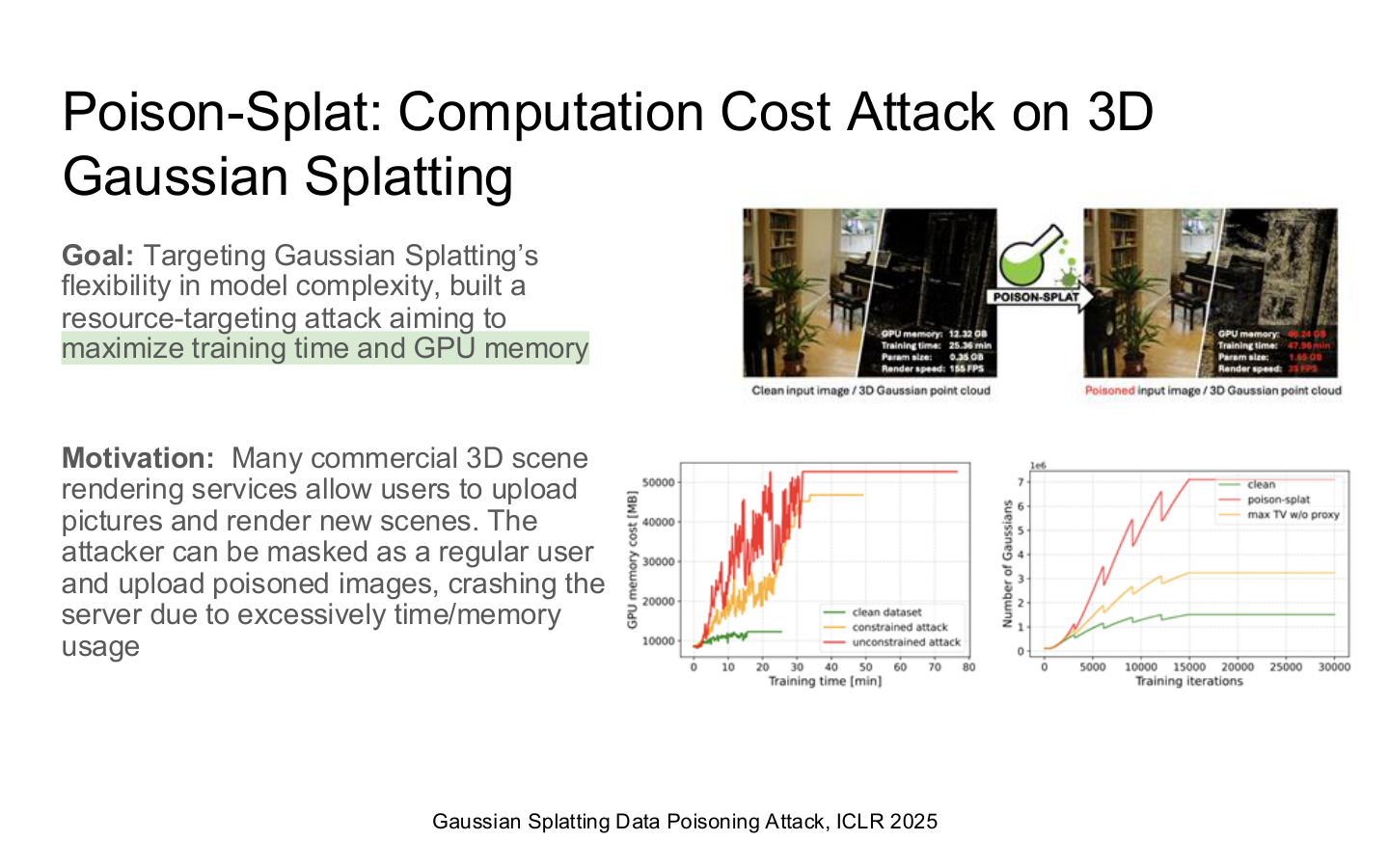
图示来源:Tufts EE141 Trusted AI, Lecture 7, Slide 23。图像说明:页面把 3D Gaussian Splatting 的计算成本攻击展示为资源耗尽问题。知识说明:系统安全不只关心机密性和完整性,攻击者也会直接针对可用性和 GPU 预算。

图示来源:Tufts EE141 Trusted AI, Lecture 7, Slide 25。图像说明:页面用红蓝水壶的心算问题说明仅凭时间/功耗差异就可能泄露信息。知识说明:侧信道攻击的关键不在于“读到明文”,而在于从副信号中恢复隐藏状态。

图示来源:Tufts EE141 Trusted AI, Lecture 7, Slide 29。图像说明:页面列出模型架构提取、参数恢复和输入恢复等攻击目标。知识说明:即便攻击者碰不到模型 API,只要共用底层资源,也可能逐步恢复高价值信息。
攻击者未必需要直接读取模型权重,只要能从侧信道恢复输入、结构或特征,就足以构成高价值攻击。
5.3 Multi-tenant accelerator 风险
当多个租户共享同一 FPGA/GPU/TPU 或推理集群时,最需要警惕:
- 未隔离的 cache 和 memory hierarchy
- 过于宽松的 driver / runtime 权限
- 调试接口、profiling 接口和 metrics 泄露
- 模型 artifact 在共享存储中暴露
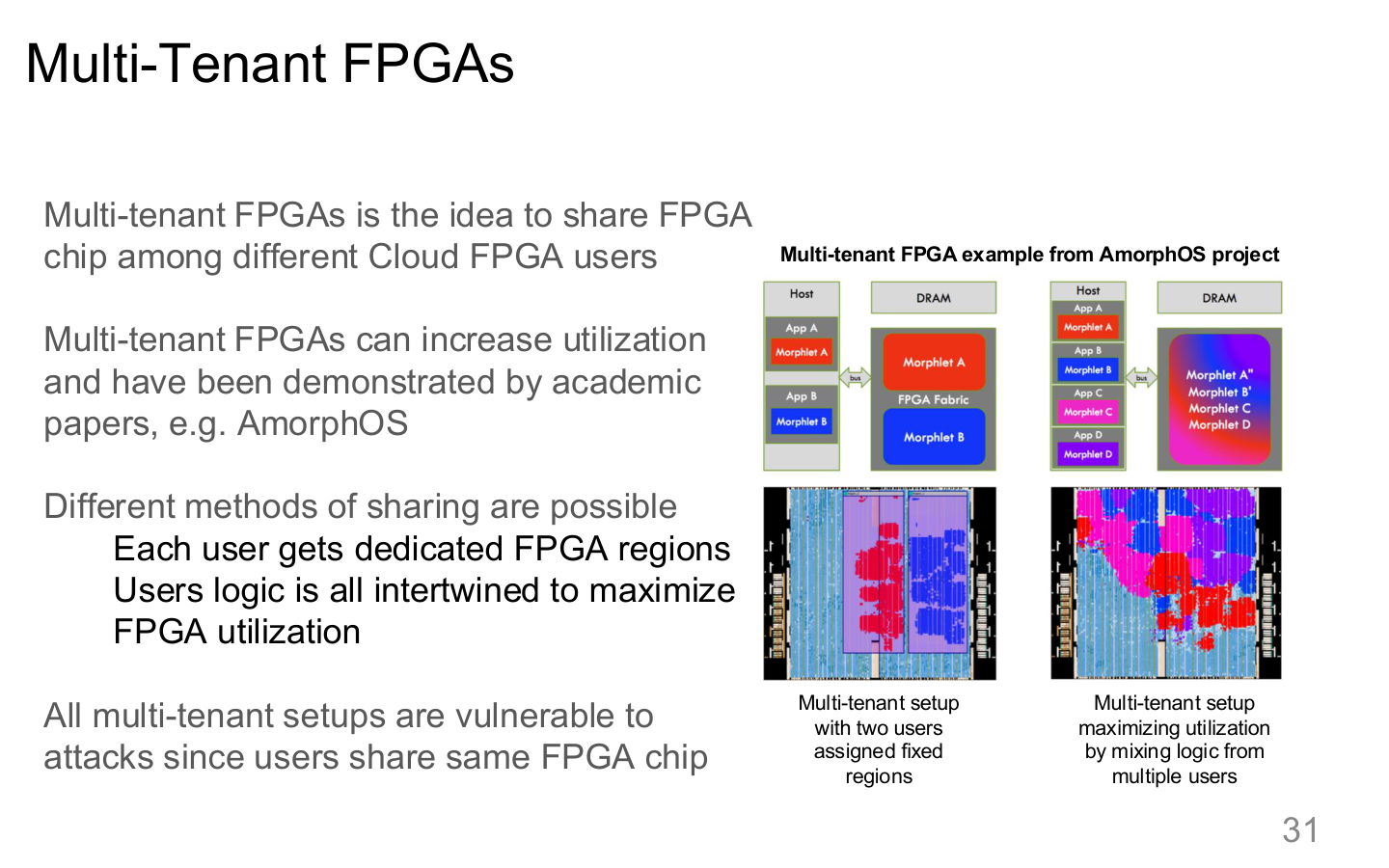
图示来源:Tufts EE141 Trusted AI, Lecture 7, Slide 31。图像说明:页面把多租户 FPGA 共享的概念直接可视化。知识说明:一旦共享资源边界不清,租户之间的推理、监控和调试行为都可能互相泄露。

图示来源:Tufts EE141 Trusted AI, Lecture 7, Slide 32。图像说明:页面从 custom ML accelerator 出发讨论信息泄露。知识说明:专用硬件带来性能优势,也会引入标准云安全文档里没有覆盖的新攻击面。
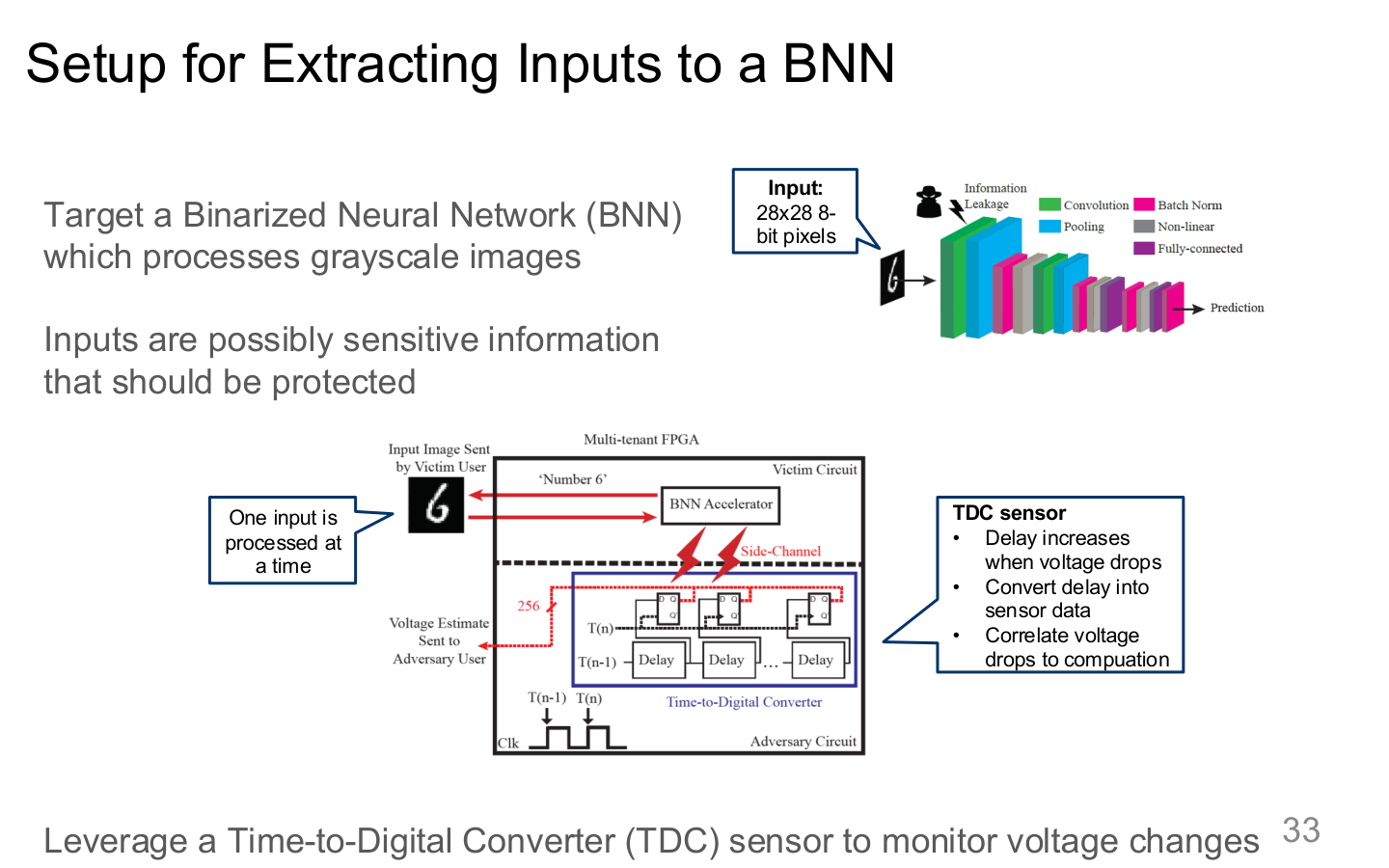
图示来源:Tufts EE141 Trusted AI, Lecture 7, Slide 33。图像说明:图中画出从加速器侧信号恢复输入的实验装置。知识说明:这表明“输入是否保密”不能只看网络链路,还要看执行时是否会从硬件副作用泄露。
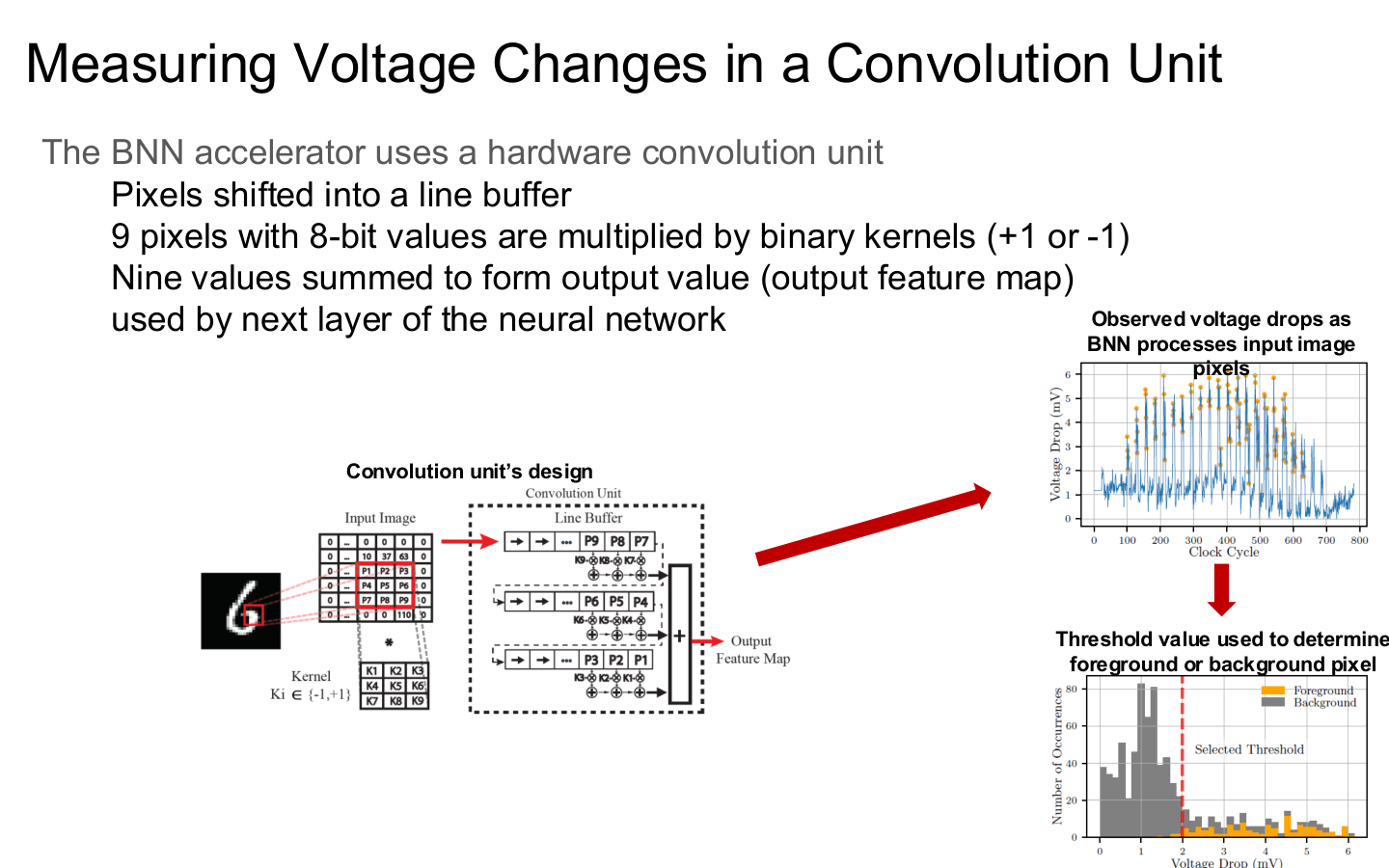
图示来源:Tufts EE141 Trusted AI, Lecture 7, Slide 34。图像说明:图中展示通过卷积单元电压变化测量侧信道信号。知识说明:许多攻击不需要读到软件日志,只需要足够稳定的物理观测窗口。

图示来源:Tufts EE141 Trusted AI, Lecture 7, Slide 35。图像说明:页面展示原始输入与重建结果的对比。知识说明:一旦可以从侧信号近似恢复输入,模型服务就可能同时泄露用户数据与业务数据。
6. 运行时隔离与审计
6.1 Sandbox 不是可选项
对高风险 tool use 场景,sandbox 至少需要回答:
- 文件系统能看到什么
- 网络能访问什么
- 进程能持续多久
- 是否有 CPU / memory / token budget
- 失败后如何清理副作用
6.2 审计日志应该记录什么
| 维度 | 最少记录 |
|---|---|
| 输入链路 | 用户输入、检索内容来源、memory 命中 |
| 推理链路 | prompt template、模型版本、policy route |
| 工具链路 | tool name、参数摘要、返回结果摘要、审批人 |
| 输出链路 | guard 是否拦截、是否脱敏、最终返回内容 |
| 安全事件 | 触发哪条规则、告警等级、处置结果 |
6.3 Incident response
一旦发生 prompt injection、secret leak 或 tool misuse,最低限度需要:
- 暂停相关能力或租户
- 回收 token / session / cached state
- 审查日志确定 blast radius
- 修复 policy、tool schema 或 isolation gap
- 把事件样例加入 red-team regression
7. 与治理页的分工
本文讨论“系统怎么不被攻破”;而 AI工程安全与合规 更关注:
- 模型卡片
- 法规与标准
- 内容治理
- 合规审计
- 组织流程
这两个页面应该一起读:治理页回答“谁负责和如何证明”,系统安全页回答“系统边界具体如何落地”。
与其他主题的关系
参考文献
- Tufts EE141 Trusted AI Course Slides, System Security Lecture, Spring 2026.
- Simon Willison, "Prompt Injection Explained", 2023.
- OWASP, "Top 10 for Large Language Model Applications", 2025.
- Razavi et al., "Flip Feng Shui: Hammering a Needle in the Software Stack", USENIX Security 2016.
- Yan et al., "Cache Telepathy", CCS 2015.